









本文聊一聊机器学习的大致过程,探讨下机器学习中常见的问题。本文借助了广告CTR预估这条主线,大概流程及内容如图所示:
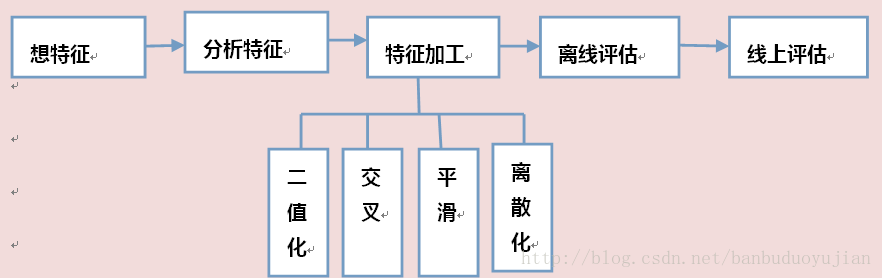
1.想特征
想特征主要靠一些经验,这些经验可能来源于以前做过的项目、特征选择、特征构建等一些实践或知识。大概的方向是想出的特征要具有区分性。比如现在要预测用户对篮球点击的概率,性别就可以作为一个特征,因为根据我们的常识:男性打篮球的可能性比女性要大。那么就引出另一个问题,怎么判断想出的特征具有区分性,特征的区分性有多明显呀?这就要根据数据进行特征分析了。
2.特征分析
对一个想到的特征是否具有区分性,我们可以基于历史数据进行统计分析。例如,经过统计我们发现,对篮球的点击男性的比例要远高于女性,那么说明性别这个特征是具有区分性的,可以作为特征考虑进模型中。经过特征分析,发现想到的特征是有区分性的,那么怎样使用特征才能使模型效果更明显呢?这就要引出特征加工了。
3.特征加工
对于特征加工,本文按照下图所示的过程进行讲解:

3.1二值化
下面主要探讨什么是二值化、为什么要二值化、怎样二值化以及二值化要注意的问题。
3.1.1什么是二值化
通过举例我们说明二值化,对于性别特征,我们可以二值化为两个特征:is_male,is_female。对于男性用户他在二值化的性别特征取值为10,女性为01.
3.1.2为什么要二值化
对有些特征来说直接进行加减乘除等数学运算是没有意义的,而后续所运用的模型可能会涉及到这些特征值之间的加减乘除的数学运算,这是不合理的。举例说明,我们要预测色彩对用户点击广告的影响。现在有红、黄、绿三种色彩,我们可以编码规定:色彩值=1,红色;色彩值=2,黄色;色彩值=3,绿色。我们的常识告诉我们,红、黄、绿之间是没有大小关系的,之间不存在红1<黄2<绿3的。因此,上述编码是不合理的。那么,怎么办才能更合理呢?采用二值化,其中一种二值化结果如下图所示:

3.1.3怎样二值化
这里探讨下dummy和one-hot编码。对上述色彩进行编码,dummy可以是3维,也可以是2维。one-hot是3维,可以说one-hot是dummy的一种情况。为了区分,在本文对色彩dummy编码特指2维。对色彩进行dummy编码如下图所示:

对色彩进行one-hot编码如下图所示:

3.1.4one-hot编码与多重共线性
什么是多重共线性,如下定义:

多重共线性会造成模型很不稳定,也就是说方程组的解不唯一,可能有无数多个解。这就可能导致以下问题(有不正确之处欢迎指正):
(1)一些特征的权重值非常大,另一些特征的权重值非常小。如果那些权重特别大的特征是一些不相关特征,就会导致模型预测时性能有所下降。
(2)造成ill-condition问题。也就是说当我们的特征值稍微改变一下,预测输出结果就会变化很大。在我们做预测时,往往假设具有相似特征的实例具有相似类别,而现在相似的特征可能会得到差别较大的结果,使模型变得不可信。
上述两点也从共线性解释了数据过拟合问题。那么怎样解决多重共线性问题,防止过拟合问题的发生,其中一种方法 引入正则化。关于正则请看这篇牛文规则化,正则化使模型更简单,提高模型的泛化能力,并且正则化可以约束模型特性,使模型具有我们所需要的性质:稀疏、平滑等。在这里,简单总结下L1、L2正则化。
L1:可以实现稀疏性,进行特征选择。
L2:使每个feature的权重都很小,提高泛化能力。另外L2还可以使我们的求解更稳定、迅速。
L1与L2的区别及联系也请参见上述博文
3.2特征交叉(待续)
3.3 平滑
下面主要探讨为什么要平滑、怎样进行平滑等问题
3.3.1为什幺平滑
为什么要进行平滑呢?举个例子,现在进行抛硬币,连续抛了三次,出现的都是正面朝上,如果根据实验结果,正面朝上的概率为1,显然这是不可信的。为什么会出现这种不可信的概率估计?我们知道,当我进行了充分多的实验,通过实验结果估计出的概率会接近真实概率。而现在,只进行了三次实验,不能通过这三次得出正面朝上的概率就是1. 为了应对这种情况,就要引入平滑处理,使得正面出现的概率不会是1,而反面出现的概率也不会是0,从而使结果更合理。
3.3.2 怎样进行平滑
平滑的方法有很多,这里简单讨论下关于广告点击率的平滑问题。wang等人对广告CTR进行了平滑处理,获得了很好的效果,因此,本文借助这篇paper讨论下涉及到的一种平滑方法。看了这篇论文,我们可能会产生这样的疑问,为什么文章假设用户是否点击符合二项分布之后提出二项分布的期望的先验分布期望是beta分布呢?在这里我们进行探讨一下。深入了解参考此博文
二项分布与beta分布在这里就不过多的讲述。我们知道,二项分布与beta分布是共轭的,也就是说beta分布作为二项分布均值P(X=1)的先验分布时,后验分布正比于先验分布与似然函数的乘积,且与先验分布具有相同的函数形式。beta分布如下式:
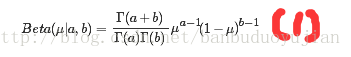
数据集大小为N,具有m个x=1的二项分布为:
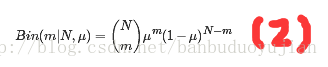
把(1)看成beta先验分布,把(2)看成似然函数,只保留关于u的因子,得后验分布:
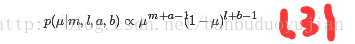
其中l=N-m,为x=0的次数。其实(3)也是beta分布,可以写成:
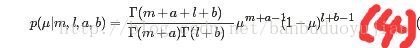
这样,从先验分布到后验分布,把x=1的个数从a增加到m+a个,x=0的个数从b个增加到l+b个,那么我们基于后验可以算出x=1的概率:
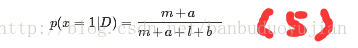
至此,我们可以了解到paper的统计学原理,至于怎样计算a,b超参数,这里就不再赘述。
3.4离散化
接着讨论下什么是离散化、为什么要离散化、怎样离散化等问题
3.4.1 什么是离散化
对于离散化的介绍参见博文
特征离散化
3.4.2为什么要离散化
对于某个连续特征,可以出于以下考虑:
(1)特征数值之间的大小没有明显的区分性。举个例子,假设是否买篮球与收入有关,A月收入1万,B月收入5千,这两者之间的收入差异不能够说明两者之间买篮球的概率差异A就是B的两倍。
(2)离散化可以增强数据的表达能力。还是买篮球,如果收入特征权重为w,那么10000*w=5000*w。现在,把收入离散化,收入1万为w1,收入5千为w2.那么每一个工资段都对应一个权重wi,就有可能10000*w1<5000*w2等情况发生。
(3)防止过拟合。
3.4.3怎样离散化
怎样离散化参见博文
离散化方法

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









