







目录
__kfifo_put和__kfifo_get巧妙的入队和出队
多线程之无锁队列|性能优化
队列操作模型
(1)单生产者-单消费者(SPSC)

(2)多生产者-单消费者(MPSC)

(3)单生产者-多消费者(SPMC)

(4)多生产者-多消费者(MPMC)

3、队列数据定长与变长
(1)队列数据定长

(2)队列数据变长

并发无锁处理
(1)单生产者-单消费者模型
在该场景中,通常不建议使用传统的加锁机制来保证线程安全,而是推荐使用原子操作(如CAS)或无锁算法(避免竞争,例如生产者通过写索引控制入队操作,消费者通过读索引控制出队列操作。二者相互之间对索引是独享,不存在竞争关系。
无锁算法实现:https://blog.csdn.net/xy010902100449/article/details/47045837
对于定长队列,可以通过读指针和写指针进行控制;对于变长队列,则可以通过读指针、写指针及结束指针来进行控制。具体实现可以参考Linux内核提供的kfifo实现:
https://blog.csdn.net/linyt/article/details/53355355)
详细解释例如:在单生产者-单消费者模型中,使用 unitNum 变量来表示队列中可读单元的数量,并且生产者和消费者都对这个变量进行操作(即生产者增加 unitNum,消费者减少 unitNum),那么确实需要考虑线程安全问题。然而,是否需要加锁取决于具体实现:
1. 原子操作:如果你的编程语言或平台提供了原子操作(例如C++中的std::atomic<int>),你可以将 unitNum 定义为一个原子类型。这样就不需要显式的锁,因为原子操作保证了对变量的操作是不可分割的,从而避免了竞态条件。
2. 无锁算法:你也可以采用无锁算法,利用硬件级别的同步指令(如比较并交换,CAS)来实现对 unitNum 的安全更新。这同样不需要传统的锁机制。
3. 内存屏障:即使使用原子操作或无锁算法,确保正确的内存可见性和顺序性仍然很重要。你需要适当地插入内存屏障以确保编译器和处理器不会重排指令,导致数据不同步的问题。
4. 互斥锁:如果上述方法不适合你的应用场景,或者为了简化代码逻辑,你可以选择使用互斥锁(mutex)。在这种情况下,当生产者想要增加 unitNum 或消费者想要检查和减少 unitNum 时,它们必须先获取锁,操作完成后释放锁。这种方式简单直接,但可能会引入额外的性能开销,特别是在高并发环境下。
综上所述,虽然你可以通过加锁来保护 unitNum,但在单生产者-单消费者的场景下,通常更推荐使用原子操作或无锁算法,结合适当的内存屏障来保证线程安全,同时保持较好的性能。
(2)多对一模型/一对多模型/多对多模型
正常逻辑操作是要对队列操作进行加锁处理。加锁的性能开销较大,一般采用无锁实现。无锁实现原理是CAS、FAA等机制。定长的可以参考:
无锁队列的实现 | http://coolshell.cn/articles/8239.html
变长的可以参考intel dpdk提供的rte_ring的实现。
intel dpdk api ring 模块源码详解_编码人生——朝阳_tony-CSDN博客
并发无锁队列学习(单生产者单消费者模型)
摘自:https://blog.csdn.net/xy010902100449/article/details/47045837
1、引言
本文介绍单生产者单消费者模型的队列。根据写入队列的内容是定长还是变长,分为单生产者单消费者定长队列和单生产者单消费者变长队列两种。单生产者单消费者模型的队列操作过程是不需要进行加锁的。生产者通过写索引控制入队操作,消费者通过读索引控制出队列操作。二者相互之间对索引是独享,不存在竞争关系。如下图所示:
2、单生产者单消费者定长队列
这种队列要求每次入队和出队的内容是定长的,即生产者写入队列和消费者读取队列的内容大小事相同的。linux内核中的kfifo就是这种队列,提供了读和写两个索引。单生产者单消费者队列数据结构定义如下所示:
typedef struct
{
uint32_t r_index; /*读指针*/
uint32_t w_index; /*写指针*/
uint32_t size; /*缓冲区大小*/
char *buff[0]; /*缓冲区起始地址*/
}ring_buff_st;
为了方便计算位置,设置队列的大小为2的次幂。这样可以将之前的取余操作转换为位操作,即r_index = r_index % size 与 r_index = r_index & (size -1)等价。位操作非常快,充分利用了二进制的特征。
(1)队列初始状态,读写索引相等,此时队列为空。

(2)写入队列
写操作即进行入队操作,入队有三种场景,
2.1 写索引大于等于读索引

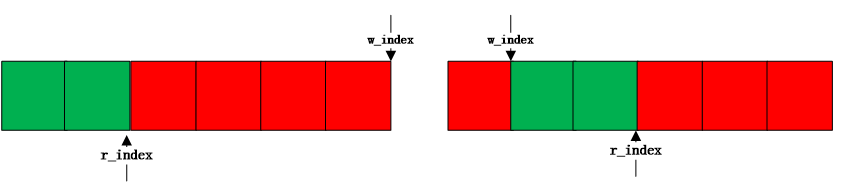
2.2写索引小于读索引

2.3.写索引后不够写入一个

(3)读取队列
读队列分为三种场景
3.1写索引大于等于读索引

3.2写索引小于读索引
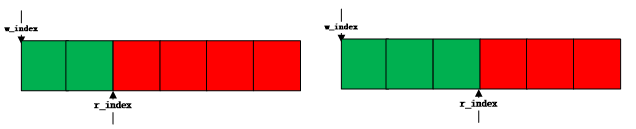
3.3.读索引后面不够一个

3、单生产者单消费者变长队列
有些时候生产者每次写入的数据长度是不确定的,导致写入队列的数据时变长的。这样为了充分利用队列,需要增加一个结束索引,保证队列末尾至少能够写入一个数据。变长队列数据结构定义如下:
详细见我博客关于边长数组介绍
http://blog.csdn.net/xy010902100449/article/details/46522533
typedef struct
{
uint32_t r_index; /*读指针*/
uint32_t w_index; /*写指针*/
uint32_t e_index; /*队列结束指针*/ 比定长的多了这个
uint32_t size; /*缓冲区大小*/
char *buff[0]; /*缓冲区起始地址*/
}ring_buff_st;
内核的无锁队列kfifo
计算机科学家已经证明,当只有一个读线程和一个写线程并发操作时,不需要任何额外的锁,只需采用无锁算法就可以确保是线程安全的。kfifo使用了无锁编程技术,以提高kernel的并发。
kfifo 是 Linux 内核中实现的一种环形缓冲区(FIFO,First In First Out),它主要用于单生产者-单消费者(SPSC)场景。
原文:巧夺天工的kfifo(修订版) https://blog.csdn.net/linyt/article/details/53355355
Linux kernel里面很多简洁,优雅和高效的代码。kernel开发者使用的不过是大家非常熟悉的基础数据结构,从基础的数据结构中,提炼出优美的特性。
kfifo就例子,十分简洁,绝无多余的一行代码,却非常高效。
关于kfifo信息如下:
本文分析的原代码版本: 2.6.24.4
kfifo的定义文件: kernel/kfifo.c
kfifo的头文件: include/linux/kfifo.h
kfifo概述
kfifo是内核里面的一个First In First Out数据结构,它采用环形循环队列的数据结构来实现;它提供一个无边界的字节流服务,最重要的一点是,它使用并行无锁编程技术,即当它用于只有一个入队线程和一个出队线程的场情时,两个线程可以并发操作,而不需要任何加锁行为,就可以保证kfifo的线程安全。
kfifo代码既然肩负着这么多特性,那我们先一敝它的代码:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};这是kfifo的数据结构,kfifo主要提供了两个操作,__kfifo_put(入队操作)和__kfifo_get(出队操作)。 它的各个数据成员如下:
buffer: 用于存放数据的缓存
size: buffer空间的大小,在初化时,将它向上扩展成2的幂(如5,向上扩展 与它最接近的值且是2的n次方的值是2^3,即8)
lock: 如果使用不能保证任何时间最多只有一个读线程和写线程,需要使用该lock实施同步。
in, out: 和buffer一起构成一个循环队列。 in指向buffer中队头,而且out指向buffer中的队尾,它的结构如示图如下:
+--------------------------------------------------------------+
| |<----------data---------->| |
+--------------------------------------------------------------+
^ ^ ^
| | |
out in size当然,内核开发者使用了一种更好的技术处理了in, out和buffer的关系,我们将在下面进行详细分析。
kfifo功能描述
kfifo提供如下对外功能规格
- 只支持一个读者和一个读者并发操作
- 无阻塞的读写操作,如果空间不够,则返回实际访问空间
kfifo_alloc 分配kfifo内存和初始化工作
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}这里值得一提的是,kfifo->size的值总是在调用者传进来的size参数的基础上向2的幂扩展(roundup_pow_of_two,我自己的实现在文章末尾),这是内核一贯的做法。这样的好处不言而喻——对kfifo->size取模运算可以转化为与运算,如下:
kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
在kfifo_alloc函数中,使用size & (size – 1)来判断size 是否为2幂,如果条件为真,则表示size不是2的幂,然后调用roundup_pow_of_two将之向上扩展为2的幂。
这都是常用的技巧,只不过大家没有将它们结合起来使用而已,下面要分析的__kfifo_put和__kfifo_get则是将kfifo->size的特点发挥到了极致。
__kfifo_put和__kfifo_get巧妙的入队和出队
__kfifo_put是入队操作,它先将数据放入buffer里面,最后才修改in参数;__kfifo_get是出队操作,它先将数据从buffer中移走,最后才修改out。(确保即使in和out修改失败,也可以再来一遍)
你会发现in和out两者各司其职。下面是__kfifo_put和__kfifo_get的代码
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}
奇怪吗?代码完全是线性结构,没有任何if-else分支来判断是否有足够的空间存放数据。内核在这里的代码非常简洁,没有一行多余的代码。
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
这个表达式计算当前写入的空间,换成人可理解的语言就是:
l = kfifo可写空间和预期写入空间的最小值
使用min宏来代if-else分支
__kfifo_get也应用了同样技巧,代码如下:
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len;
return len;
}认真读两遍吧,我也读了多次,每次总是有新发现,因为in, out和size的关系太巧妙了,竟然能利用上unsigned int回绕的特性。
原来,kfifo每次入队或出队,kfifo->in或kfifo->out只是简单地kfifo->in/kfifo->out += len,并没有对kfifo->size 进行取模运算。因此kfifo->in和kfifo->out总是一直增大,直到unsigned in最大值时,又会绕回到0这一起始端。但始终满足:
kfifo->in - kfifo->out <= kfifo->size
即使kfifo->in回绕到了0的那一端,这个性质仍然是保持的。
对于给定的kfifo:
数据空间长度为:kfifo->in - kfifo->out
而剩余空间(可写入空间)长度为:kfifo->size - (kfifo->in - kfifo->out)
尽管kfifo->in和kfofo->out一直超过kfifo->size进行增长,但它对应在kfifo->buffer空间的下标却是如下:
kfifo->in % kfifo->size (i.e. kfifo->in & (kfifo->size - 1))
kfifo->out % kfifo->size (i.e. kfifo->out & (kfifo->size - 1))
往kfifo里面写一块数据时,数据空间、写入空间和kfifo->size的关系如果满足:
kfifo->in % size + len > size
那就要做写拆分了,见下图:
kfifo_put(写)空间开始地址
|
\_/
|XXXXXXXXXX
XXXXXXXX|
+--------------------------------------------------------------+
| |<----------data---------->| |
+--------------------------------------------------------------+
^ ^ ^
| | |
out%size in%size size
^
|
写空间结束地址 第一块当然是: [kfifo->in % kfifo->size, kfifo->size]
第二块当然是:[0, len - (kfifo->size - kfifo->in % kfifo->size)]
下面是代码,细细体味吧:
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l); 对于kfifo_get过程,也是类似的,请各位自行分析。
kfifo_get和kfifo_put无锁并发操作
计算机科学家已经证明,当只有一个读经程和一个写线程并发操作时,不需要任何额外的锁,就可以确保是线程安全的,也即kfifo使用了无锁编程技术,以提高kernel的并发。
kfifo使用in和out两个指针来描述写入和读取游标,对于写入操作,只更新in指针,而读取操作,只更新out指针,可谓井水不犯河水,示意图如下:
|<--写入-->|
+--------------------------------------------------------------+
| |<----------data----->| |
+--------------------------------------------------------------+
|<--读取-->|
^ ^ ^
| | |
out in size为了避免读者看到写者预计写入,但实际没有写入数据的空间,写者必须保证以下的写入顺序:
- 往[kfifo->in, kfifo->in + len]空间写入数据
- 更新kfifo->in指针为 kfifo->in + len
在操作1完成时,读者是还没有看到写入的信息的,因为kfifo->in没有变化,认为读者还没有开始写操作,只有更新kfifo->in之后,读者才能看到。
那么如何保证1必须在2之前完成,秘密就是使用内存屏障:smp_mb(),smp_rmb(), smp_wmb(),来保证对方观察到的内存操作顺序。
总结
读完kfifo代码,令我想起那首诗“众里寻他千百度,默然回首,那人正在灯火阑珊处”。不知你是否和我一样,总想追求简洁,高质量和可读性的代码,当用尽各种方法,江郞才尽之时,才发现Linux kernel里面的代码就是我们寻找和学习的对象。
#define RAW_SIZE 13
cout << "v:" << pow(2,5) << endl; //2 的5次方
cout << "v:" << log2(62) << endl; //求log2(62)
cout << "v:" << ceil(log2(62)) << endl; //ceil 向上取整
cout << "v:" << pow(2,ceil(log2(RAW_SIZE))) << endl;//求离RAW_SIZE最近的不小于RAW_SIZE的2的幂值注意事项
只有每个op时间很短的时候,才有意义。(也就是锁造成的线程切换时间占比OP时间比较大)
如果op的时间本身比较长,锁造成的切换时间占比OP时间很小,那么意义就很小。 (例如,每秒处理50万以下,这点速度,可能用无锁意义不大)
链表无锁队列,可能比有锁队列还低。 因为链表队列 在插入的时候要new,就会在系统有锁,那么无锁队列可能退化成有锁。所以 商用的无锁队列,大多是数组的。
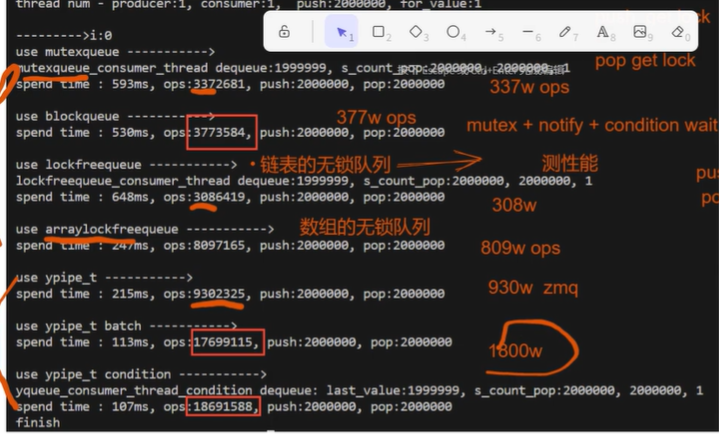
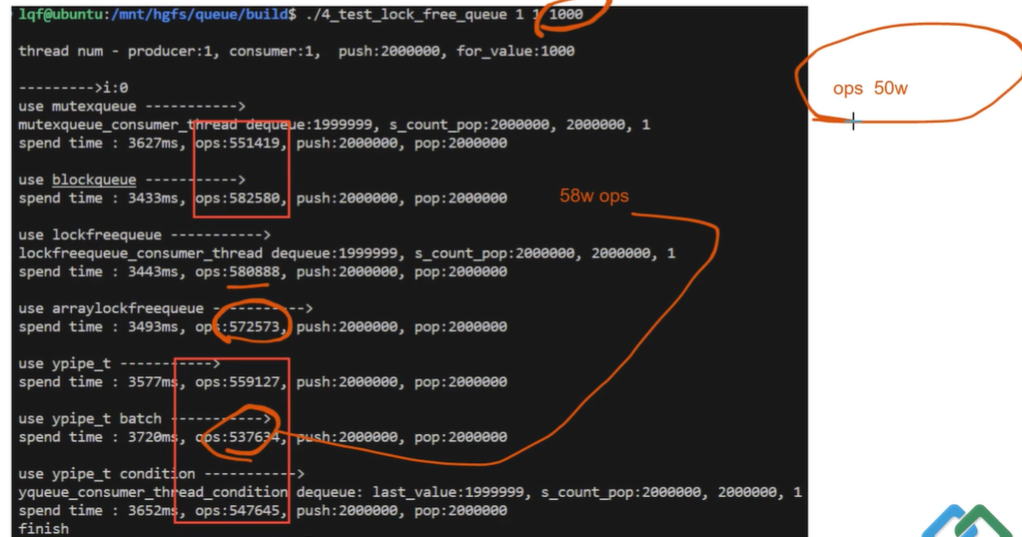
C++多线程编程——无锁数据结构之无锁队列_https://www.bilibili.com/video/BV1Xh4y1e7UK
(并发编程和多线程操作)为什么大部分人对无锁队列的理解是错误的?_https://www.bilibili.com/video/BV1234y1w7jR/


















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









