









无锁的定义
自由锁定编程通常被描述为没有互斥锁的编程,互斥锁也称为锁定。 这是真的,但这是故事的一部分。 基于学术文献的普遍接受的定义更广泛。 本质上,无锁定是编写特定代码的属性,不需要过多地描述代码的实际编写方式。
基本上,如果部分程序满足以下条件,则该部分当然不会被锁定: 相反,如果代码的特定部分不满足这些条件,则该部分未锁定。
从这个意义上说,无锁的锁定并不直接指排他锁定,而是指死锁、生锁,甚至是你最大的敌人可能会以某种方式“锁定”整个应用程序最后一点我觉得很有趣,这是关键。 共享互斥锁只是被排除。 因为线程获得独占锁后,最大的敌人将不再调度该线程。 当然,真正的操作系统只是定义术语而不是这样运行的。
无锁队列
生产环境中广泛使用生产者和消费者模型,要求生产者在生产的同时,消费者可以进行消费,通常使用互斥锁保证数据同步。但线程互斥锁的开销仍然比较大,因此在要求高性能、低延时场景中,推荐使用无锁队列。
根据操作队列的场景分为:单生产者——单消费者、多生产者——单消费者、单生产者——多消费者、多生产者——多消费者四大模型。
根据队列中数据分为:队列中的数据是定长的、队列中的数据是变长的。
无论是以上哪种操作队列的应用场景,无锁队列都可以完成。
无锁队列在UE4的应用
UE4 的 TaskGraph 实现任务级并行计算架构,整个系统实现的非常高效,得益于无锁队列。
TaskGraph 采用了 work stealing 的任务调度策略,可以在任意工作线程中动态创建 Task 并指定依赖关系,另外除了 task-base 的基本并行功能外,TaskGraph 可以将任务分发到指定线程执行,比如渲染命令任务都会被分发到渲染线程中,构造渲染命令列表,然后再由渲染线程分发到渲染抽象接口线程中执行。
实现无锁队列的方式
需要考虑多线程情况下,资源占用问题。
解决资源占用问题的方法
因为叫无锁队列,所以使用的是CAS方法。
其中悲观锁是 mutex锁,
乐观锁是 CAS操作。
悲观锁
- 假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
- 悲观锁的实现,往往依靠底层提供的锁机制。(跨平台比较困难)
- 悲观锁会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。
乐观锁
- 假设不会发生并发冲突,每次不加锁而是假设没有冲突而去完成某项操作,只在提交操作时检查是否违反数据完整性。
- 如果因为冲突失败就重试,直到成功为止。
- 乐观锁大多是基于数据版本记录机制实现。
- 为数据增加一个版本标识,比如在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。
- 此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
- 乐观锁的缺点是不能解决脏读的问题。
- 在实际生产环境里边,如果并发量不大且不允许脏读,可以使用悲观锁解决并发问题。
- 如果系统的并发非常大的话,悲观锁定会带来非常大的性能问题,所以我们就要选择乐观锁定的方法。
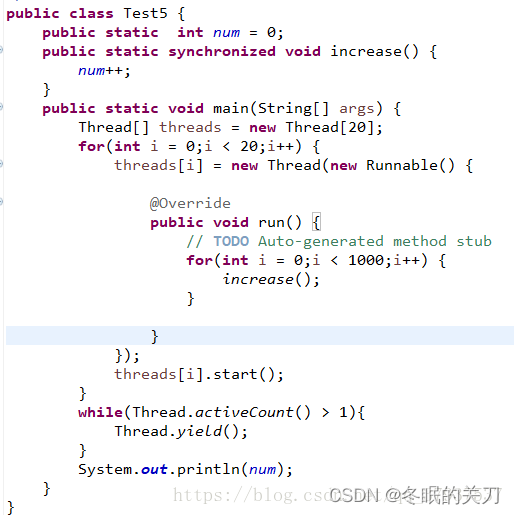
Java中的synchronized锁
用synchronized来保证在CPU上的原子性
其实就是在函数作用域内加锁,防止多个线程同时调用一个函数
原子变量
C++11提供了原子类型std::atomic,可以使用任意的类型作为模板参数。在多线程中如果使用了原子变量,其本身就保证了数据访问的互斥性,所以不需要使用互斥量来保护该变量了。
对原子变量的操作是原子操作,能保证在任何情况下都不被打断,是线程安全的,不需要加锁。
在新标准C++11,引入了原子操作的概念,并通过这个新的头文件提供了多种原子操作数据类型,例如,atomic_bool,atomic_int等等,如果我们在多个线程中对这些类型的共享资源进行操作,编译器将保证这些操作都是原子性的,也就是说,确保任意时刻只有一个线程对这个资源进行访问,编译器将保证,多个线程访问这个共享资源的正确性。从而避免了锁的使用,提高了效率。
std::atomic<long> globalCount = 0;
{
globalCount += 1;
}
自定义原子操作语义 (互斥锁 mutex)
C++ 的标准原子类型在 头文件里。这些 atomic types 的所有操作都是原子的,C++标准定义下也只有这些类型的操作是原子的(显然你可以用 mutex 之类的同步原语自己实现原子性)。
互斥锁 mutex
#include <mutex>
mutex m;
void WorkFun(int param)
{
...
for(int i = 0;i<4;i++)
{
m.lock();
cout<<param<<"Hello, other thread." <<n << endl;
m.unlock();
}
...
}
自解锁
#include <mutex>
mutex m;
void WorkFun(int param)
{
...
for(int i = 0;i<2000;i++)
{
lock_guard<mutex> lg(m);//自解锁 创建时 调用这个类的构造函数 执行lock, 析构时,执行unlock
cout<<param<<"Hello, other thread." <<n << endl;
}
...
}
CAS操作
compare_and_swap
比较并交换
CAS即Compare and Swap,是所有CPU指令都支持CAS的原子操作(X86中CMPXCHG汇编指令),用于实现实现各种无锁(lock free)数据结构。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。
如果当前内存位置的值等于预期原值A的话,就将B赋值。否则,处理器不做任何操作。整个比较并替换的操作是一个原子操作。这样做就不用害怕其它线程同时修改变量。
CAS虽然能够高效的保证原子性,但是它还是存在着ABA问题以及循环开销大等缺点
- ABA问题:如果另外一个线程在这个线程进行CAS比较的途中,将内存位置的值已经进行了操作,但是操作结果又将内存位置的值改为了预期原值,这个时候这个线程在比较的时候会发现内存位置和预期原值是相等的所以进行了替换操作,事实上另外一个线程已经对这个内存位置的值进行了操作,但是当前线程并不能发现这个问题。这就是ABA问题。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一
- 循环开销大:自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
- 只能保证一个共享变量的原子操作:当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性。
C11对CAS支持
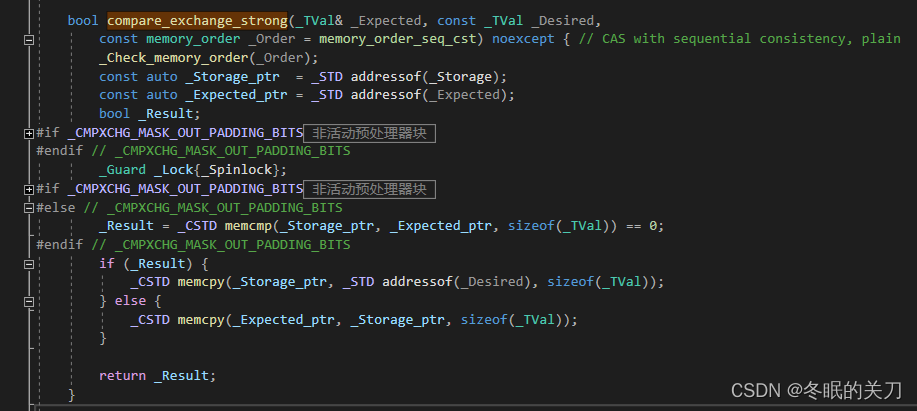
C11 STL中atomic函数支持CAS并可以跨平台。
template< class T >
bool atomic_compare_exchange_weak( std::atomic* obj,T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak( volatile std::atomic* obj,T* expected, T desired );
其它原子操作
Fetch-And-Add:一般用来对变量做+1的原子操作;
Test-and-set:写值到某个内存位置并传回其旧值;
无锁队列方案
1、boost方案
boost提供了三种无锁方案,分别适用不同使用场景。
boost::lockfree::queue是支持多个生产者和多个消费者线程的无锁队列。
boost::lockfree::stack是支持多个生产者和多个消费者线程的无锁栈。
boost::lockfree::spsc_queue是仅支持单个生产者和单个消费者线程的无锁队列,比boost::lockfree::queue性能更好。
Boost无锁数据结构的API通过轻量级原子锁实现lock-free,不是真正意义的无锁。
Boost提供的queue可以设置初始容量,添加新元素时如果容量不够,则总容量自动增长;但对于无锁数据结构,添加新元素时如果容量不够,总容量不会自动增长。
2、ConcurrentQueue
ConcurrentQueue是基于C实现的工业级无锁队列方案。
http://GitHub:https://github.com/cameron314/concurrentqueue
ReaderWriterQueue是基于C实现的单生产者单消费者场景的无锁队列方案。
http://GitHub:https://github.com/cameron314/readerwriterqueue
多线程安全操作不同方法效率对比
volatile
Volatile,词典上的解释为:易失的;易变的;易挥发的。那么用这个关键词修饰的C/C++变量,应该也能够体现出”易变”的特征。大部分人认识Volatile,也是从这个特征出发。volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从内存中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象易变性。
Volatile关键词的第二个特性:“不可优化”特性。volatile告诉编译器,不要对我这个变量进行各种激进的优化,甚至将变量直接消除,保证程序员写在代码中的指令,一定会被执行。
一般结合原子变量使用
#include <iostream>
#include <thread>
#include <mutex>
#include <atomic>
#include <vector>
#include <chrono>
long long globalCount = 0;
//std::mutex globalMutex;
void ThreadFunction()
{
for (int i = 0; i < 100000; ++i)
{
//std::lock_guard<std::mutex> lock(globalMutex);
globalCount += 1;
}
}
int main()
{
std::vector<std::thread> threads;
std::chrono::system_clock::time_point startTime = std::chrono::system_clock::now();
for (int i = 0; i < 10; ++i)
{
threads.push_back(std::thread(ThreadFunction));
}
for (int i = 0; i < 10; ++i)
{
threads[i].join();
}
std::chrono::system_clock::time_point endTime = std::chrono::system_clock::now();
std::cout << "当前总数为:" << globalCount << std::endl;
std::cout << "消耗时间为:" << std::chrono::duration_cast<std::chrono::milliseconds> (endTime - startTime).count() << "毫秒" << std::endl;
getchar();
return 0;
}
线程不安全方法执行时间为19ms
加mutex互斥自解锁执行时间为200ms
Release为35ms
使用原子变量std::atomic< long long >执行时间也为200ms
Release为72ms
//这种方法是利用C++原生类型的原子赋值运算符操作
//可扩展性不好
std::atomic<long long> globalCount = 0;
{
globalCount++;
}
使用CAS原子操作的方法执行时间为220ms
Release为104ms
//用这种方法可以定义自己的原子操作
std::atomic<long long> globalCount = 0;
{
long long cid = globalCount;
while (!globalCount.compare_exchange_weak(cid, cid + 1))
{
}
}
这里的CAS代码块解释一下
首先先把globalCount存到栈帧变量cid里来,
如果这个时候,外部globalCount变了,那就把cid更新到外部globalCount的数据
如果外部globalCount没变,给cid和globalCount上锁,把globalCount赋值为cid+1,然后解锁















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









