







笔记
iWARP协议是RDMA Consortium组织推动实现的,它由Broadcom、HP、IBM、Intel和Microsoft等公司在2002年5月成立
2005年11月,Ohio超算中心发布Soft-iWARP,同Soft-RoCE一样,是软件实现的iWARP协议栈,为学习、仿真和使用不支持硬件iWARP的网卡带来了方便。
iWARP协议一共有3层,所以更准确地讲iWARP应该是一组协议的统称,或者称为协议族。下图中绿色背景的部分,即为iWARP的三层协议,ULP指的是Upper Layer Protocol,即上层协议,iWARP通过Verbs接口向上层提供服务。ULP可以是一些存储协议,比如iSCSI、可能是中间件,比如UCX、也可能是用户的应用程序。
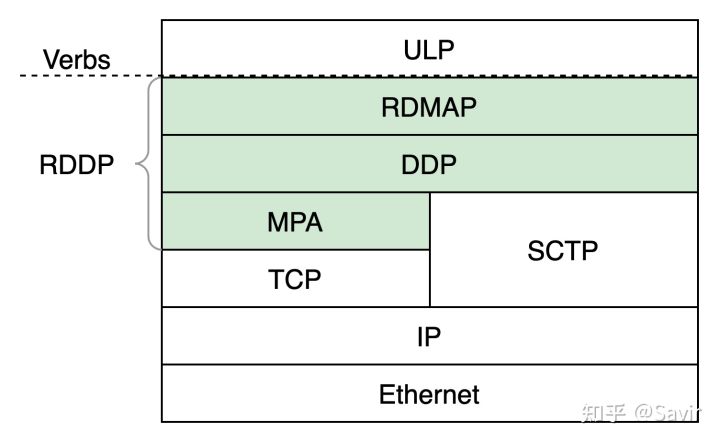
iWARP协议栈的层次关系
DDP(Data Placement Protocol)
DDP是iWARP的核心,负责在传输层协议之上实现零拷贝的功能。DDP是最能体现RDMA技术核心思想的一层。
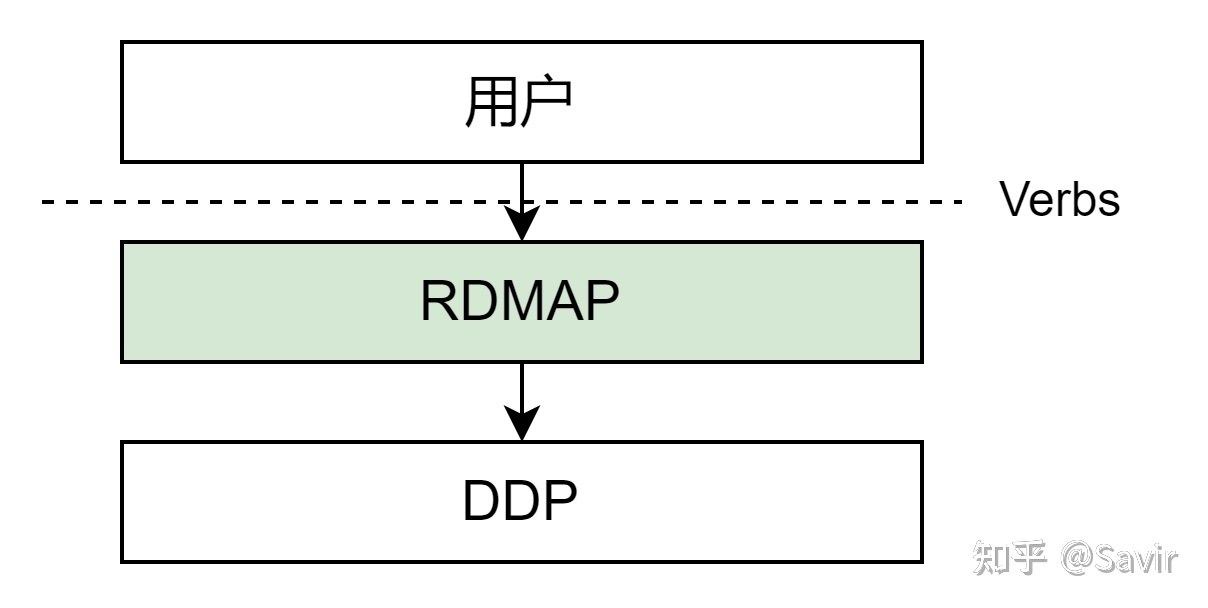
RDMAP(Remote Direct Memory Access Protocol)
RDMAP最靠近用户的一层,为上层用户提供RDMA语义,支撑它们的Send/RDMA Read/RDMA Write等各种类型的请求。RDMAP依赖于下层的DDP提供的零拷贝功能来实现对应的用户请求。
MPA(Marker Protocol data unit Aligned framing)
MPA负责在发送端按照一定的算法在TCP流中加入控制信息,从而使得接收端可以按照算法识别出流中的DDP消息的分界。实际上完成的是将DDP适配TCP的工作。当DDP的下层是SCTP协议时就不需要MPA这一层了,因为SCTP可以识别出上层协议的分界。
正文
转自: https://zhuanlan.zhihu.com/p/449189540 作者:Savir
本文欢迎非商业转载,转载请注明出处。
RDMA的三大协议:Infiniband、RoCE以及iWARP。文本中,带大家了解一下iWARP的概念、历史、工作原理以及特点,然后在多个方面对比iWARP和RoCE v2的差异,最后介绍如何在没有支持iWARP的网卡的情况下通过Soft-iWARP来做实验。
概述
iWARP指的是基于TCP/IP协议栈的RDMA技术,最开始是由RDMA Consortium组织设计的一组协议,最终由IETF(Internet Engineering Task Force)进行了标准化。iWARP被一些文章解释为Internet Wide Area RDMA Protocol,这是不正确的,RDMA Consortium专门做出解释说它不是一个缩写,我们把它当成一个专有名词就好了:
iWARP is a computer networking protocol that implements Remote Direct Memory Access (RDMA) for efficient data transfer over Internet Protocol networks. It is a suite of protocols comprised of RDMAP, DDP, and MPA which may be layered above TCP, SCTP, or other transport protocols. Some sources claim iWARP is an acronym meaning “Internet Wide Area RDMA Protocol”. This incorrect and misleading because iWARP was designed for a broad range of environments, including Local Area Networks (LANs), storage networks, data center networks, wide area networks (WANs), etc. iWARP is NOT an acronym.
Infiniband协议诞生以来,虽然相比传统以太网有着很大的优势,但是受限于从以太网切换的成本过于高昂,后面又分别产生了基于TCP的iWARP和基于UDP的RoCE v1/v2两种RDMA协议,使得RDMA的使用者只需要更换网卡,而不用更换现有的路由、交换设备以及线缆就可以享受到RDMA带来的网络性能提升和CPU负载的下降等收益。
跟RoCE协议继承自Infiniband不同,iWARP本身不是直接从Infiniband发展而来的。IB和RoCE协议都是基于《Infiniband Architecture Specification》所指定的标准的,也就是我们常说的”IB规范“。而iWARP自成一派,遵循着一套IETF设计的协议标准。
虽然遵循着不同的标准,但是iWARP的设计思想明显受到了很多Infiniband的影响,并且目前也在使用同一套软件API,也就是Verbs。因此读者不用担心要重新学习一套新的体系,这三种协议的概念层面是没有什么差别的,我们前面讲到的基础知识除了涉及协议的部分,也一样适用于iWARP。
下面回顾一下这几种协议的分层关系:
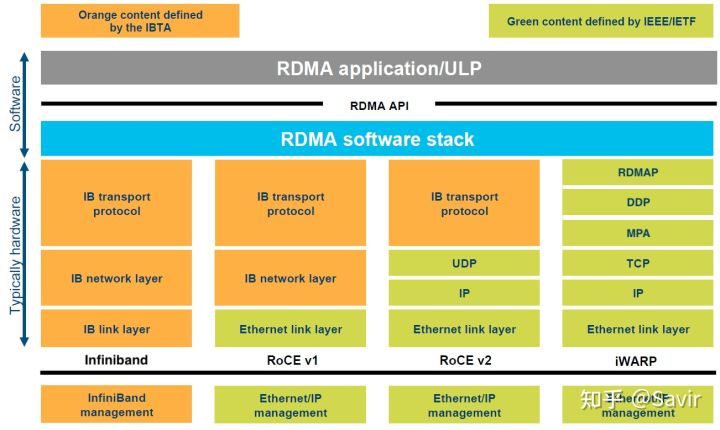
4种RDMA协议的层次关系
可以鲜明的看到,Infiniband和iWARP分别由IBTA和IETF完全定义。IBTA我们在《RDMA概述》一文中已经简单介绍过了,IETF大家也应该都很熟悉,我们现在的互联网标准,包括TCP/IP都是由这个组织定义的。
历史
iWARP有着比较悠久的历史,我们来了解一下iWARP是如何诞生和发展的:
iWARP协议是RDMA Consortium这个组织所推动实现的,它由Broadcom、HP、IBM、Intel和Microsoft等公司在2002年5月成立。我们在《RoCE & Soft-RoCE》一文中曾经介绍过,IBTA组织成立于1999年,该组织在2000年就发布了Infiniband Architecture Specification 1.0版本的规范,并且Infiniband已经开始商用。而IBTA的创建者也是包含Intel、IBM和Microsoft的,可见这几个公司当时并不是非常看好Infiniband的未来[2],它们另起炉灶,试图在传统以太网之上实现RDMA技术,这也是RDMA Consortium组织成立的目标。
同年2002年,IETF成立了RDDP(Remote Direct Data Placement)工作组,这个工作组负责iWARP协议的标准化工作。随后,RDMA Consortium在2003年3月完成并发布了最初版本的RDMAP/DDP/MPA标准,以及专为iWARP设计的软件API,也就是iWARP专用的Verbs接口(和现有的Verbs API不是一回事),同时上述标准也被当作草案提交给了IETF RDDP工作组。
当时整个RDMA领域处于群雄逐鹿的状态,即使不同厂商的设备可以通过标准协议相互通信,但是它们却各自使用着自己的软件栈和接口,也就是说用户对于不同的硬件要编写不同的应用程序。后来厂商们也意识到独立的API不利于行业的发展,因此在2004年6月一些厂商成立了OpenIB Alliance组织,也就是OFA的前身,这个组织致力于对Infiniband进行软件和接口的统一,而iWARP此时还在独立发展。
2005年7月,Ammasso 1100网卡发布,它是第一款支持iWARP的网卡。这个时候IETF标准的iWARP协议栈还没有发布,所以它支持的是RDMA Consortium版本的iWARP。
同年11月,Ohio超算中心发布了Soft-iWARP,同Soft-RoCE一样,这是软件实现的iWARP协议栈,为学习、仿真和使用不支持硬件iWARP的网卡带来了方便。12月,IETF RDDP工作组发布RFC 4296和4297,设计了RDDP的结构和接口,并分析了RDMA over IP面对的问题。
时年,占据市场领先地位的Mellanox的Verbs API已经统一了Infiniband领域,所以剩下的问题就是IB和iWARP的统一了。为了实现这个目标,DAT(Direct Access Transport)组织设计并提出了DAPL(Direct Access Programming Library),但可惜的是这套接口并没有被广泛使用。
而iWARP最终拥抱了OpenIB组织,放弃了专用的Verbs接口,决定和IB采用统一的软件栈和Verbs API。2006年,OpenIB Alliance组织宣布支持Windows与iWARP,并更名为Open Fabrics Alliance。同年4月,Linux内核开始支持iWARP。2007年4月, Chelsio宣布OFED软件包从1.2版本开始支持iWARP。至此,iWARP与Infiniband和RoCE完成了软件栈和接口上的大一统,RDMA的用户可以使用同一套应用程序来使用这几种协议。
2007年10月,IETF RDDP工作组相继发布RFC 5040 ~ 5045,iWARP协议族形成标准。至此iWARP协议形成了两个版本,分别称为RDMAC和IETF,两者之间存在一些差异。但是IETF版本可以视为是RDMAC版本的改进版,后续的硬件都是基于IETF的版本实现的。
2012年到2014年之间,IETF又发布了新增CM建链支持的RFC 6581,以及新增对Atomic操作等的支持的RFC 7306等,扩展了iWARP的能力,最终形成了现在的“完全体”版本。
组成
iWARP协议一共有3层,所以更准确地讲iWARP应该是一组协议的统称,或者称为协议族。下图中绿色背景的部分,即为iWARP的三层协议,IETF也将这三层称为RDDP。图中ULP指的是Upper Layer Protocol,即上层协议,iWARP通过Verbs接口向上层提供服务。ULP可以是一些存储协议,比如iSCSI、可能是中间件,比如UCX、也可能是用户的应用程序。
iWARP协议栈的层次关系
与iWARP直接关联的下层协议可以是TCP,也可以是SCTP(Stream Control Transmission Protocol)。SCTP是一种结合了TCP和UDP的优点传输层协议,但是目前的应用情况不及TCP和UDP。
我们来简单讲一下各层的功能:
DDP(Data Placement Protocol)
DDP是iWARP的核心,负责在传输层协议之上实现零拷贝的功能。DDP的报文中包含有描述内存区域的信息,硬件可以直接根据DDP报文中的控制信息,通过DMA搬移DDP报文中的数据到内存中的目的地。上述过程不需要CPU的参与,所以DDP是最能体现RDMA技术核心思想的一层。
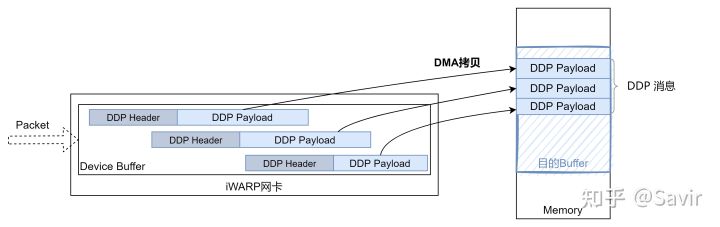
DDP层的功能示意图
RDMAP(Remote Direct Memory Access Protocol)
RDMAP是iWARP协议栈中最靠近用户的一层,主要功能是为上层用户提供RDMA语义,支撑它们的Send/RDMA Read/RDMA Write等各种类型的请求。RDMAP依赖于下层的DDP提供的零拷贝功能来实现对应的用户请求。
RDMAP层的功能示意图
MPA(Marker Protocol data unit Aligned framing)
MPA这一层负责在发送端按照一定的算法在TCP流中加入控制信息,从而使得接收端可以按照算法识别出流中的DDP消息的分界。实际上完成的是将DDP适配TCP的工作。当DDP的下层是SCTP协议时就不需要MPA这一层了,因为SCTP可以识别出上层协议的分界。

MPA层的功能示意图
标准
上述三层协议都分别由一个RFC所标准化,除此之外IETF还对一些iWARP的细节制定了标准。这些RFC的编号、标题和内容如下表所示:
| 名称 | 标题 | 内容 |
|---|---|---|
| RFC 4296 | The Architecture of Direct Data Placement (DDP) and Remote Direct Memory Access (RDMA) on Internet Protocols | 对DDP和RDMAP标准化的前瞻性分析,主要分析的是需要什么样的数据结构和接口。另外也简单分析了安全性问题 |
| RFC 4297 | Remote Direct Memory Access (RDMA) over IP Problem Statement | 分析当前网络中内存拷贝带来的性能瓶颈,以及使用RDMA技术后的安全问题(与rfc4296重复) |
| RFC 5040 | A Remote Direct Memory Access Protocol Specification | RDMAP层标准 |
| RFC 5041 | Direct Data Placement over Reliable Transports | DDP层标准 |
| RFC 5042 | Direct Data Placement Protocol (DDP) / Remote Direct Memory Access Protocol (RDMAP) Security | RDMAP和DDP的安全性进一步分析 |
| RFC 5043 | Stream Control Transmission Protocol (SCTP) Direct Data Placement (DDP) Adaptation | DDP如何适配于SCTP之上 |
| RFC 5044 | Marker PDU Aligned Framing for TCP Specification | MPA层标准 |
| RFC 5045 | Applicability of Remote Direct Memory Access Protocol (RDMA) and Direct Data Placement Protocol (DDP) | RDMAP和DDP的可用性分析,下层在使用SCTP和TCP层时的对比 |
| RFC 6580 | IANA Registries for the Remote Direct Data Placement (RDDP) Protocols | 对操作码、错误码等的规定 |
| RFC 6581 | Enhanced Remote Direct Memory Access (RDMA) Connection Establishment | 关于通过MPA建立RDMA连接的补充描述,是RFC 5043和5044的加强 |
| RFC 7306 | Remote Direct Memory Access (RDMA) Protocol Extensions | 扩展iWARP的功能,新增对Atomic操作和立即数的支持 |
如果读者想要学习更多iWARP标准的细节,大家可以点击文末指向本专栏其他iWARP文章的链接继续了解,然后进一步阅读上述的RFC。相比于IB Specification,iWARP的标准不仅规定了协议应该怎么实现,还解释了为什么要如此设计,是比较好的学习资料。
现状
说到iWARP的现状,有的读者可能认为其已经在与RoCE v2和Infiniband的竞争中完败,几乎被市场所淘汰。但是实际上还远远不到“被淘汰”的地步,虽然iWARP没有另外两者的市场份额大,但始终有厂商在继续研发和生产支持iWARP的网卡,它也一直在一些应用场景下发挥着它独特的优势。
对于具体的市场情况我不了解,但是我们可以通过开源生态的发展来侧面了解三大RDMA技术的现状,毕竟如果不会带来价值,这些商业公司是不可能投入人力和金钱去做软件生态的。
我们来看一下Linux内核的drivers/infiniband/hw目录,这个目录下是各个硬件厂商(VMware除外)的RDMA网卡驱动:
.
├── Makefile
├── bnxt_re
├── cxgb4
├── efa
├── hfi1
├── hns
├── irdma
├── mlx4
├── mlx5
├── mthca
├── ocrdma
├── qedr
├── qib
├── usnic
└── vmw_pvrdma这些驱动程序所属的厂家(括号外的公司被括号内的公司收购或者为其子公司)如下:
| 驱动名 | 厂商 | Infiniband | RoCE v2 | iWARP | 备注 |
|---|---|---|---|---|---|
| bnxt_re | Broadcom | √ | |||
| cxgb4 | Chelsio | √ | |||
| efa | Amazon | 自成一派,使用自研的SRD协议,也支持UD。 | |||
| hfi1 | Cornelis | 使用Omni-Path协议,从Intel拆分出来的公司。 | |||
| hns | HiSilicon(Huawei) | √ | |||
| irdma | Intel | √ | √ | ||
| mlx4 | Mellanox(NVIDIA) | √ | √ | ||
| mlx5 | Mellanox(NVIDIA) | √ | √ | ||
| mthca | Mellanox(NVIDIA) | √ | |||
| ocrdma | Emulex(Broadcom) | 只支持RoCEv1,很久没更新了。 | |||
| qedr | QLogic(Marvell) | √ | √ | Qlogic非IB部分最终被Marvell收购 | |
| qib | Qlogic(Intel) | √ | Qlogic的IB技术被Intel收购 | ||
| usnic | Cisio | 私有协议 | |||
| vmw_pvrdma | VMware | √ |
可以看到,目前RDMA的网卡主要剩下了几个玩家:博通、Chelsio(切尔西奥)、华为海思、Intel、NVIDIA、Marvell,以及自成一派的亚马逊、Cornelis和思科。除了Infiniband技术由NVIDIA一家独大之外,iWARP和RoCEv2阵营中都有多个厂商。
支持iWARP厂商近几年也更新了几款网卡:
2017年,Chelsio发布Terminator 6 (T6);收购了Qlogic的Cavium发布了FastLinQ 45000系列网卡,然后同年被Marvell收购。
2018年,Intel发布了X722。
2020年,Intel又发布E810 irdma网卡,同时支持RoCE v2和iWARP,2021年也推出了新型号的E810。
应用层面,网上能搜到微软的关于部署iWARP的一些文章,Marvell和Chelsio也提到微软内部的存储系统有在使用iWARP:
Storage Spaces Direct Hardware Requirements | Microsoft Docs

国内而言,阿里内部也在使用自研的iWARP网卡,最近正在向Linux社区上传他们的网卡驱动:
[rdma-next,00/11] Elastic RDMA Adapter (ERDMA) driver - Patchwork (kernel.org)
总体来说,iWARP的发展确实不如RoCE和Infiniband,而且带头人之一的Intel也有转向RoCE的趋势,不过从上面的分析来看,目前iWARP还是有一定的市场的。那么iWARP和其他RDMA技术的差异在哪里呢?
和RoCE v2的对比
目前叫得上名字的几种RDMA技术有:Infiniband、iWARP、RoCE v2、RoCE v1和Omni-Path等。而其中的RoCE v1的定位处于Infiniband和RoCE v2中间,更像是过渡阶段的协议,应用不是很多;Omni-Path已经被Intel放弃,拆分出独立的公司继续发展,而且我也不了解,因此就不展开说这两种技术了。
而剩下三种主流协议中,Infiniband从协议到软硬件形成了生态闭环,其性能虽然好于另外两者,但是企业应用它的成本也最高昂,因为需要更换全套设备,包括网卡、光缆和交换机等。企业如果对于从以太网切换到Infiniband的成本不敏感,那么自然就会选择使用IB而不考虑iWARP和RoCE v2。
RoCE v2和iWARP的设计初衷都是为了在传统的以太网上技术上实现RDMA,网络层都基于IP,只不过在传输层一个选择了UDP,一个选择了TCP。它们都兼容现有的以太网线缆、交换及路由设备,并且都提供软件实现的协议栈。
相似的定位和功能意味着它们存在竞争关系,因此RoCE v2的老大哥Mellanox和iWARP的主要支持者Chelsio就在网上公开diss对方主推的技术不如自己家的好用,具体可以看一下这两篇“著作”:
- Mellanox对于RoCE v2和iWARP的竞争力分析:
https://www.mellanox.com/related-docs/whitepapers/WP_RoCE_vs_iWARP.pdf
- Chelsio关于如何从RoCE v2和iWARP之间做选择的分析:
https://www.chelsio.com/wp-content/uploads/resources/iwarp-or-roce-rdma.pdf
而作为同时掌握iWARP和RoCE v2技术的Marvell,对两者的优劣做出了相对客观的对比:
RoCE or iWARP for Low Latency? - Marvell Blog | We’re Building the Future of Data Infrastructure
综合这几篇文章的内容,我们来比较一下这两种协议的主要差异。Mellanox的文章搜索引擎中的排名很高,容易给人造成先入为主的印象,所以下面我先讲RoCE的缺点。
重传开销
当网络遭遇链路拥塞或者物理故障(不常见)等情况时,往往会出现丢包的情况,即数据包没有按照预期从发送端到达目的端。如果用户使用的是可靠服务类型,这时就需要发送端重新发送丢失的数据包,也就是重传。
因为iWARP是基于TCP的,支持选择性重传,丢哪个包就重传哪个包,因此重传开销极小;而RoCE v2是基于无连接协议的UDP协议,相比面向连接的TCP协议,UDP协议更加快速、占用CPU资源更少,但其不像TCP协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,只能依靠上层应用检查到了再做重传,会大大降低RDMA的传输效率。RoCE v2采用的是go-back-N的重传方式,即从丢了的包开始重传之后每一个数据包。假设发送端发送了1~5一共5个数据包,但是2号丢了,这时候即使3~5已经被接收端收到,也会被视为无效,需要等待发送端重新发送2~5,可见重传开销是很高的。采用这种方案是因为RoCE v2不支持乱序接收,所有的数据包必须按序处理。(下图未画出ACK报文)
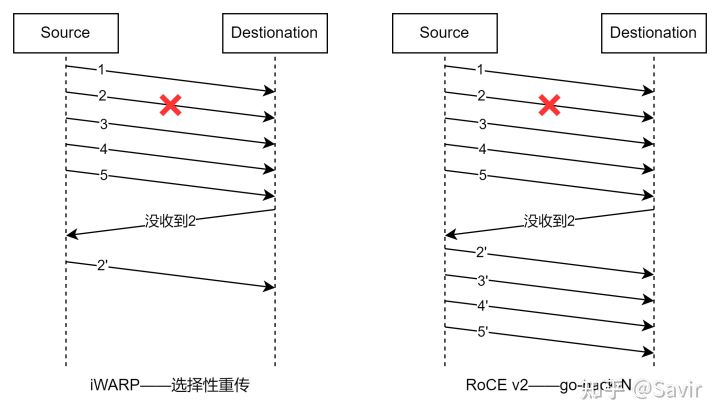
iWARP和RoCE v2的重传机制对比
也因为这个原因,RoCE v2往往强调的应用场景是“无损网络(Lossless)”,即不会发生丢包的网络。一旦丢包发生,就会重传,而重传报文又可能会加剧链路的拥塞,导致网络情况恶化。
拥塞控制
当一个节点的入口流量大于出口流量时,就会通过缓存机制来暂存收到的数据包。当缓冲区满了的时候,只能选择丢弃后收到的数据包,也就是发生了丢包的情况,我们把这种情况称为拥塞。
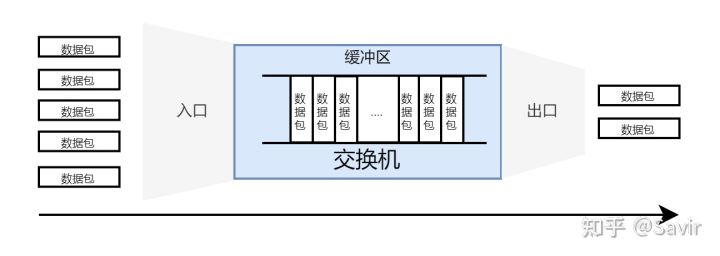
网络拥塞示意图
RoCE所要求的无损/无丢包网络,可以通过PFC流量控制机制来实现。这里我们只简单说一下原理,大致就是当某一个节点即将发生拥塞时,会通过发送特殊的报文“Pause帧”来告知上游停止发送数据。而上游节点收到这个Pause帧之后,会继续发Pause帧给它的上游。这样逐级传递下去,最后所有收到Pause帧的节点都会停止发送数据,直到拥塞解除。
但是PFC本身会带来一些问题,比如不公平降速(Unfairness)和伤及无辜(Victim flow),我们就不展开讲了。PFC本身对于RoCE v2网络是必须的,但是PFC启动对网络影响很大,所以一般都是尽量避免触发PFC,同时采取一些更温和的、细粒度的拥塞控制方法。另外PFC本身有8个优先级,可以理解为支持8个互不影响的数据流,这对于复杂网络环境是远远不够的。
目前比较流行的应用于RoCEv2网络中的拥塞控制算法是DCQCN(Data Center Quantized Congestion Notification),原理是即将发生拥塞时会通知发送端降低发送速率,从而避免拥塞。当多次收到拥塞通知时,发送方的速率会按照一定的算法越来越低;而当发送方一段时间没有收到拥塞通知时,其发送速率又会按照算法快速恢复,充分利用网络的带宽。DCQCN支持QP粒度的拥塞控制,即RDMA技术中“流”的粒度。
即使RoCE有了DCQCN算法的加持,但是其在面对大规模部署的情况时面临着问题,其中最重要的就是参数调优。当网络节点多、网络拓扑复杂的情况下,需要对DCQCN算法的各个参数进行微调,这需要投入不少的精力,而且网络拓扑一旦发生变化,就可能需要重新调整参数,这个人力和时间成本是需要企业慎重考虑的;另外,DCQCN算法还需要交换机支持RED(Random early detection)和ECN(Explicit Congestion Notification)功能,不过现在主流的企业级交换机一般都是支持这两个功能的。
除了DCQCN之外,目前还有TIMELY、华为提出的LDCP等算法试图解决RoCE大规模部署的问题,相信在不久的将来,一定可以产生一个标准化的、成熟的、易用的RoCE拥塞解决方案。
总结来说,RoCE v2面临问题的根源是重传机制对于丢包的敏感性,影响了其在大规模部署场景下的应用。除了设计拥塞控制算法外,目前一些厂商也开始研究RoCE的选择性重传来解决该问题。
说回iWARP,因为其TCP这种可靠传输技术,其本身天然就支持有损网络,对网络环境的容忍度高,扩展性也更好。当网络规模较大时,也有很多比较成熟的算法来解决拥塞问题,比如DCTCP,相比RoCE v2,易用性也更胜一筹。
说了几个RoCE的缺点,下面我们看一下iWARP的缺点:
处理时延
通过本文一开始对几种RDMA协议的层次对比图我们很容易就能发现,iWARP协议栈的层数比RoCE v2多了两层。而且从协议栈上看,RoCE的UDP层很简单,而UDP层之上的IB传输层的逻辑也不复杂。相比之下,iWARP协议栈的TCP层和MPA层都比较复杂,组装和解析报文的过程都要考虑各种各样特殊的情况。
协议复杂度大带来了处理时间长的问题,所以iWARP相比RoCE而言,时延性能要差一些。虽然据Chelsio所说,NVMe-oF(一种存储业务)场景下两者的性能差距只有3%左右,但是Mellanox和Marvell给出的数据,纯RDMA业务场景下,大包时延差距在20%以上甚至更多。
实现复杂度
iWARP的协议栈本身比RoCE v2要复杂,光是在硬件中实现TCP/IP协议栈(也叫TOE,即TCP Offload Engine)就已经极其困难了,更别说加上iWARP的三层协议了。所以有的厂商使用FPGA来实现,也有的选择只在硬件中实现iWARP及其所需的TCP部分功能,而普通TCP/IP业务仍然走内核中的软件协议栈。这可能也是iWARP厂商比较少的原因之一吧。
灵活性
因为iWARP是基于可靠的传输层协议TCP实现的,所以只能支持可靠服务类型,即RC服务类型,不支持UD。当网络节点较多时,RC这种QP之间“一对一”连接的方式,相比UD会消耗大量的内存来维护连接信息(在QPC)中,进而增加了企业部署的成本。
另外,因为iWARP必须依赖于MPA层提供的建链机制,所以不能像RoCE v2一样通过Socket链接来交换两端的信息,只能通过RDMA软件框架提供的CM建链接口来实现,对上层应用开发者来说略微增加了一点学习接口的时间成本。
最后我们总结一下两者的差别:
| iWARP | RoCE v2 | |
|---|---|---|
| 标准组织 | IETF | IBTA |
| 规范 | RFC 5040~5045、6580、6581、7306 | IB Architecture Specification |
| 传输层协议 | TCP | UDP |
| 总协议层数 | 7 | 5 |
| 主要厂商 | Intel、Chelsio、Marvell | NVIDIA(Mellanox)、Broadcom、华为、Marvell |
| 网络环境 | 有损/无损 | 无损 |
| 诞生时间 | 2003年 | 2014年 |
| 重传机制 | 选择性重传 | Go back N |
| 拥塞控制算法 | TCP、DCTCP、TIMELY等 | DCQCN、LDCP、TIMELY等 |
| 支持服务类型 | RC | RC、UD、XRC、UC等 |
| 支持建链类型 | CM | Socket、CM |
| 通信时延 | 大 | 小 |
| 可扩展性 | 强 | 弱 |
| 部署难度 | 低 | 高 |
| 实现复杂度 | 高 | 低 |
| 灵活性 | 低 | 高 |
综上所述,虽然RoCEv2的存在感比较高,而且市场占有率也更高,但是iWARP也并非完全被RoCE v2碾压。从两者中做选择时,要充分考虑自己的网络环境和业务场景等因素。如果网络规模较小,对时延敏感,那么更建议选择RoCE v2;如果网络规模大、注重网络的可扩展性,或者对时延不敏感,那么更建议选择iWARP。
Soft-iWARP
同我们之前介绍的Soft-RoCE一样,iWARP也有软件实现的版本——Soft-iWARP。其提出于2005年,并在2019年进入了Linux内核主线(位于drivers/infiniband/sw/siw目录下)。有了它之后,网络中不具备支持iWARP协议网卡的普通TCP/IP节点也可以和其他支持硬iWARP的节点进行通信;此外,我们也可以基于Soft-iWARP进行学习、实验和测试。
由于减少了系统调用,发送方使用零拷贝技术等原因,Soft-iWARP相比于传统TCP/IP也会带来一定的性能提升。但是毕竟是软件实现的iWARP,和硬件实现相比还是有不少的性能差异的。
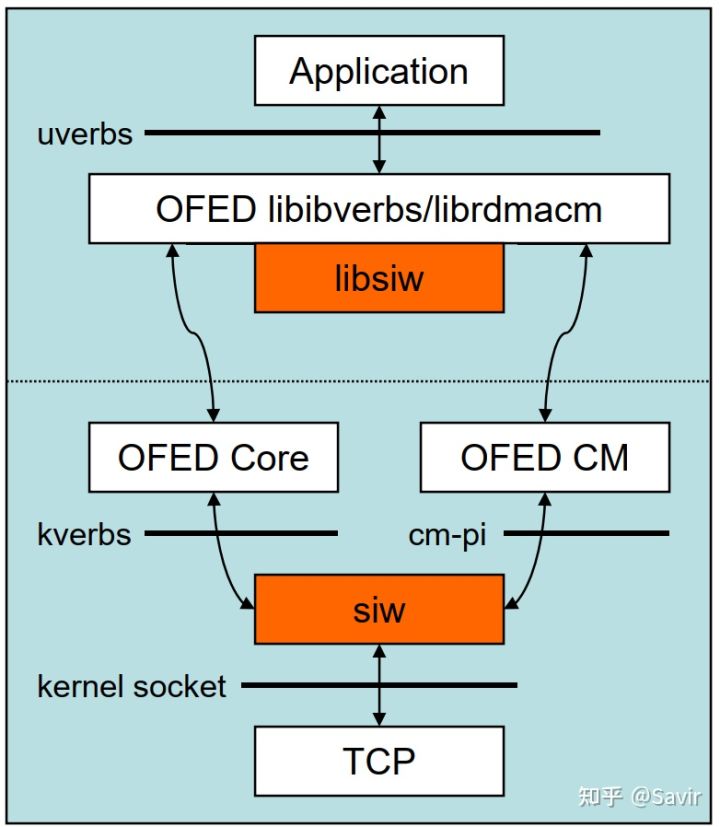
iWARP实现原理[9]
如上图所示,它的底层是基于Socket实现的,发送端的驱动程序组装完iWARP三层协议的报文后,继续交给下层的TCP/IP协议栈处理完成报文的发送。接收端则相反,先由TCP/IP协议栈处理报文,再交由驱动剥离iWARP域段,然后根据控制信息拷贝数据到对应的内存位置。
需要注意的一点是,因为实现难度问题,Soft-iWARP目前并不支持在发送端插入MPA层的Marker(见《MPA》一文),相当于说MPA层的发送端功能是有一部分缺失的。
实验
下面我们在虚拟机环境中基于Soft-iWARP,做一个简单的抓包实验。
准备工作
准备工作请参考《RoCE & Soft-RoCE》一文章节“如何做实验”章节从“准备做实验”到“配置虚拟机网卡“之间的流程。
为了避免Soft-RoCE可能造成的干扰,建议先删除RXE设备并且卸载其驱动:
sudo rdma link del rxe_0
sudo rmmod rdma_rxe配置siw网卡
Soft-iWARP在内核中的驱动名为siw,我们首先加载其驱动程序:
sudo modprobe siw然后通过rdmatool添加Soft-iWARP设备:
sudo rdma link add siw_0 type siw netdev ens33其中siw_0为我们想给设备起的名字,siw为设备类型,ens33为其基于的网卡的设备名。
接下来我们可以通过ibv_devices或者rdmatool工具确认设备已经添加成功:
ibv_devices
rdma link两种命令都可以看到新添加的设备siw_0:

RDMA设备查询结果
通过ibv_devinfo查看设备信息,我们可以看到transport类型为iWARP:
ibv_devinfo -d siw_0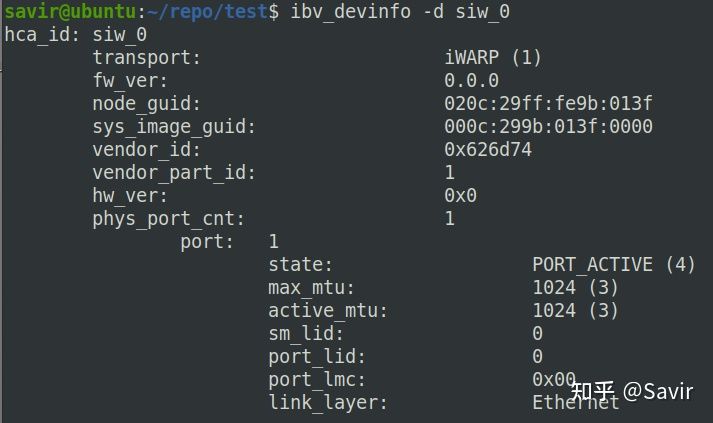
ibv_devinfo查询设备信息结果
执行perftest测试
基于iWARP的通信需要两端节点的QP先在MPA层进行参数的协商,而目前软件栈中的MPA协商是基于Connection Manager提供的用户接口来触发的,因此iWARP不支持基于Socket的建链(即像RoCEv2一样通过Socket交换QPN等信息后两端QP就可以利用对端信息进行通信了),只支持CM建链。
另外前文我们说过,因为iWARP基于TCP,所以是不支持UD服务类型的,因此我们的perftest只能进行基于CM建链的RC服务类型的测试。CM建链对应perftest中的参数是“-R”。
下面开始进行Write操作的实验,Server端(RDMA Write响应端)执行:
ib_write_bw -d siw_0Client端(RDMA Write发起端)执行:
ib_write_bw -d siw_0 192.168.217.128 -RServer端结果:
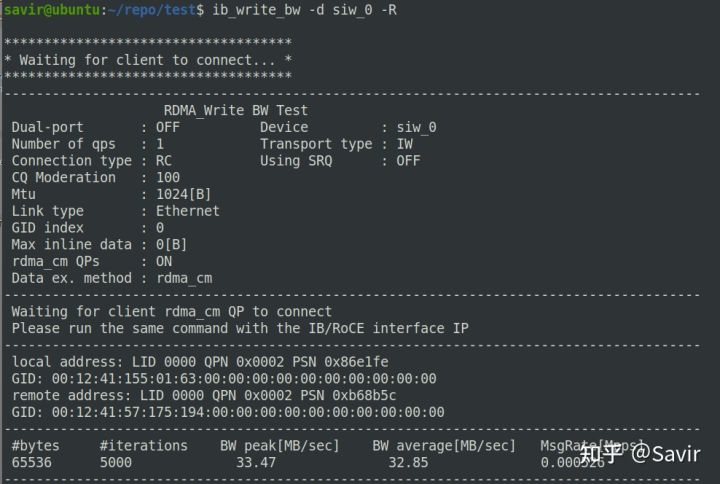
Server端perftest执行结果
Client端结果:
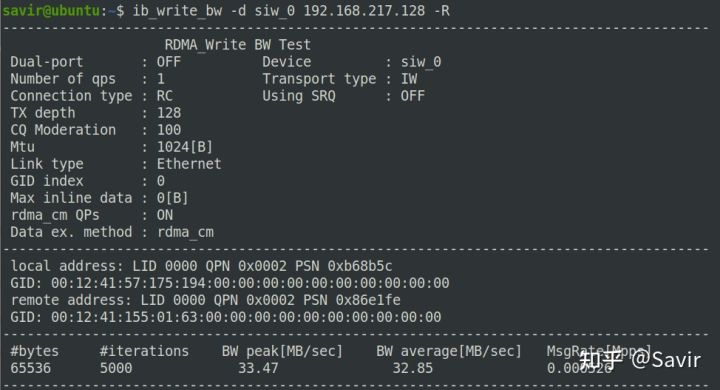
Client端perftest执行结果
注:使用ib_send_bw测试Send操作,两端在最后都会打印下面的信息,显示销毁PD错误:

Ib_send_bw报错信息
因为PD是最先申请、最后释放的RDMA资源,所以除了造成一点内存泄露之外没有其他影响,可能是虚拟机环境造成的。我也没时间定位,所以就先忽略它吧:)
通过Wireshark抓包
抓包的配置跟《RoCE & Soft-RoCE》一致,本文不再赘述了。
我们任选一个Write操作的iWARP报文,可以看到从物理层→以太网链路层→IPv4网络层→TCP传输层→iWARP MPA层→iWARP DDP/RDMAP层→用户数据的层次关系。
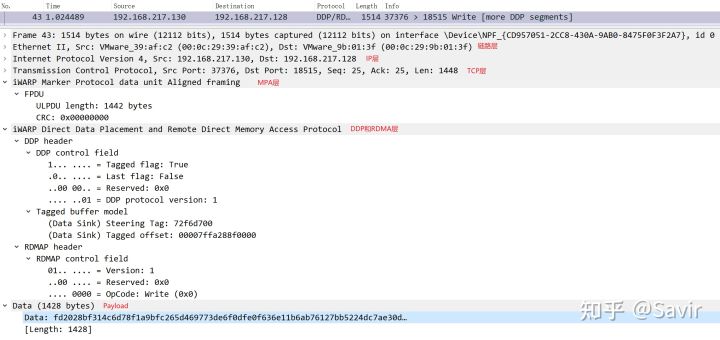
因为DDP和RDMAP本身之间没有明确的分界线,所以在Wireshark中它们被划分到了一起,这个我们在《RDMAP》一文中做出了解释。
好了,iWARP和Soft-iWARP我们就介绍到这里,感谢阅读。大家如果有疑问请在评论区发出来,大家一起学习。更多关于iWARP协议的细节,请读者移步本专栏另外三篇文章:
1. DDP(Direct Data Placement)26 赞同 · 14 评论文章
2. RDMAP(Remote Direct Memory Access Protocol)16 赞同 · 5 评论文章
3. MPA(Marker PDU Aligned framing)15 赞同 · 0 评论文章
专栏索引:
下期预告:打算讲一下RDMA技术中的内存管理,或者介绍如何基于Pyverbs快速编写RDMA程序。
参考资料
[1] OFA wiki. OpenFabrics Alliance - Wikipedia
[2] iWARP wiki. iWARP - Wikipedia
[3] attaining high performance communications a vertical approach
[4] RDMA Consortium官网. Home (rdmaconsortium.org)
[5] Marvell FastLinQ 系列网卡官网. FastLinQ Performance NICs | Universal RDMA | Ethernet Adapters and Controllers - Marvell
[6] 不动如山的博客. 容损网络vs无损网络,讨论RDMA网络的两种思路 - 不动-如山 - 博客园 (cnblogs.com)
[7] Omni-Path wiki. Omni-Path - Wikipedia
[8] Revisiting Network Support for RDMA. https://dl.acm.org/doi/pdf/10.1145/3230543.3230557
[9] Soft-iWARP OFA材料. https://www.openfabrics.org/downloads/Media/Sonoma2009/Sonoma_2009_Mon_softiwrp.pdf
[10] Congestion Control for Large-Scale RDMA Deployments
















 5803
5803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









