







近期学习了一些RDMA的基础知识,在这里做个整理记录,供以后快速查阅。
总体概念
RDMA是Remote Direct Memory Access的缩写,即远程DMA。顾名思义,RDMA最大的特点是支持对远端内存的直接读写,而不需要远端CPU介入。
RDMA的主要特点和优势有以下几点:
1. zero-copy。RDMA的网络收发接口可以直接把用户态的buffer地址交给RDMA网卡,网卡负责将buffer中的数据发送到远端,或将收到的远端数据写入buffer。这就避免了socket网络收发接口中需要先将数据复制到收发缓冲区的一次数据拷贝操作。
一些用户态协议栈和内核零拷贝特性(SOCK_ZEROCOPY)也能实现数据收发的零拷贝,但在接口和使用模式上目前还没有RDMA的自然和高效。这是因为RDMA是基于这个目标设计的,而普通的socket接口和TCP/IP协议栈设计时就没有考虑过这个目标。此外RDMA的零拷贝特性是与硬件实现相关的,普通网卡的收发功能是无法支持RDMA语义中收发操作的零拷贝的。
2. kernel-bypass。这和上面的zero-copy是同时获得的特性,用户态接口可以直接向RDMA网卡发起数据收发操作,而不需要再进入内核。
通过DPDK等用户态网卡驱动,一些用户态协议栈同样是kernel-bypass的。用户态驱动和kernel-bypass不是RDMA特有的。
3. hardware-offloading。RDMA协议大多是通过网卡硬件实现的,网卡会实现从链路层到传输层协议的报文封装、解析、可靠传输等功能。而一般的网卡是没有这些功能的,只负责报文的不可靠传输,其他功能都要通过软件实现,通过CPU完成。这就让使用RDMA接口和硬件的应用能获得更低的网络CPU开销和网络时延。
RDMA协议也有软件实现,例如内核中的rxe(ROCEv2)和siw(iWARP)模块。在软件实现RDMA协议时,就不存在上面所说的优势了。此外,其他协议栈(例如TCP/IP)理论上也能卸载到网卡上实现,但实际上比较罕见。这可能也与RDMA从一开始就是为硬件实现而设计的有关。
4. 传输与编程模型。RDMA最大的特点是其特有的read/write传输接口和语义。在read/write语义中,read和write的对端是不需要感知其他节点对其内存的read和write操作的。这使得一个节点可以在软件逻辑不主动参与、甚至不感知的情况下,与多个节点完成数据收发交互。这在其他网络编程模型下是无法做到的。
RDMA能够支持这些语义是因为RDMA协议包含了比传输层更高层次的会话层协议,在这些高层协议中实现了这些语义。而普通的socket编程基于的TCP/IP协议只包含到传输层协议。事实上目前主流的RDMA协议ROCEv2和iWARP都是在TCP/UDP传输协议上层封装RDMA会话层协议来实现的。RDMA协议不是一种单一的协议,而是能够实现RDMA功能的一套协议族。事实上,任何协议族只要能支持RDMA规范中定义的接口和语义,就能被称为RDMA协议。
因此,RDMA的传输和编程模型也不是RDMA专有的,通过自行设计上层协议和编程接口,也可以实现RDMA-like的网络编程接口和模型,例如google的SNAP/Pony-express。只是这些协议如果不能卸载到网卡硬件上完成,就仍然要通过协议栈软件实现,运行在CPU上。但即使如此,协议栈能够在接到远端请求时直接响应而不需要再与上层应用交互,也能在合适的场景下显著提升网络交互性能。
协议
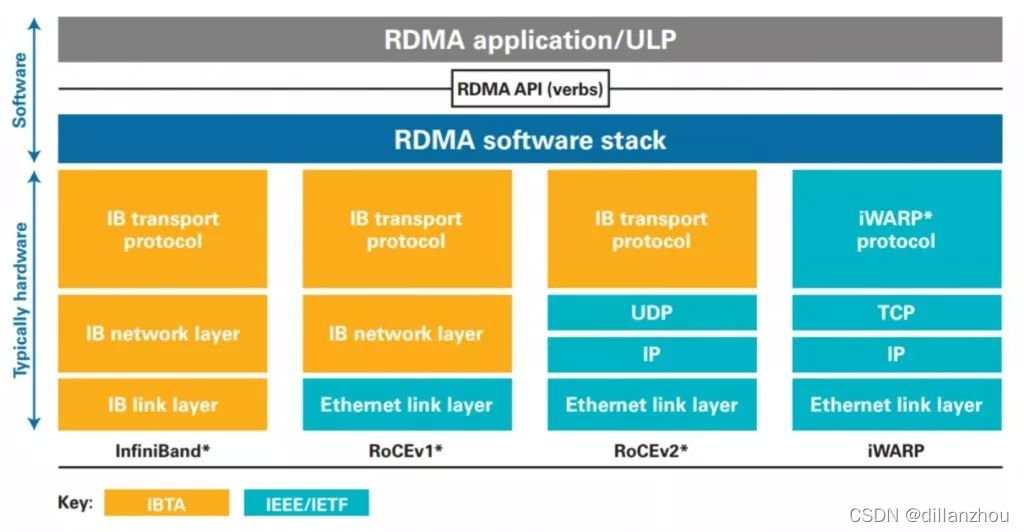
主要有3种:
1. InfiniBand协议。从链路层到传输/回话层都是专门设计的协议。
2. RoCE。复用了已有的链路层、网络层和传输层协议,便于复用以太网交换机和IP路由器。主要应用的是RoCEv2,复用Ethernet/IP/UDP协议栈,最上层使用IB传输协议。
3. iWARP。在Ethernet/IP/TCP协议栈上层设计的RDMA协议栈。与IB协议栈完全不同,是IETF为RDMA在有损网络下使用而设计的。
相关组织
IBTA:Infiniband Trade Association,IB行业协会,由IB行业的主要厂商构成,负责制定协议标准,设备认证。IB协议与RoCE协议就是IBTA制定的。
IETF:Internet Engineering Task Force,互联网工程任务组。最大的网络标准制定组织。iWARP协议由IEEE/IETF制定。
RDMA Consortium,RDMA联盟,由Adaptec, Broadcom, Cisco, Dell, EMC, Hewlett-Packard, IBM, Intel, Microsoft和Network Appliance等公司建立。Verbs和iWARP初始版本的规范就是这个组织设计和提交给IETF的。
OFA:OpenFabrics Alliance。负责开发、测试、认证、支持和分发独立于厂商的开源跨平台infiniband协议栈。OFED(OpenFabrics Enterprise Distribution)协议栈是这个联盟的代表性产物,包括RDMA驱动、内核、中间件和API。
Linux社区:负责RDMA内核子系统和RDMA网卡驱动的开发维护。RDMA的网卡驱动有3种类型,分别由Linux内核社区、OFED和Mellanox维护,彼此之间会有一些差异,也会互相移植特性。
RDMA社区:负责用户态接口库libibverbs开发维护。https://github.com/linux-rdma/
常用名词与基本元素
HCA:Host Channel Adapter, 宿主通道适配器。在IB协议中就指代RDMA网卡硬件。
WQ:Work Queue,工作队列。用于向网卡提交网络收发操作任务,用途类似于virtio_ring中的available ring。
WQE:Work Queue Entry,工作队列项。用于描述提交的收发任务,类似于virtio_ring中的descriptor。
SQ:Send Queue,发送队列。WQ的一种,用于提交发送任务。向SQ中添加任务称作Post send。Send/Read/Write操作任务都属于Send request,都会提交到SQ中。
RQ:Receive Queue,接收队列。WQ的一种,用于提交接收任务。向RQ中添加任务称作Post receive。只有Recv操作会提交到RQ中。
QP:Queue Pair,队列对。由一个SQ、一个RQ组成。QP是RDMA通信的基本单元和端点,RDMA通信都是由一个QP发往另一个QP的。
QPN:Queue Pair Number,QP编号。每个QP有一个本地唯一标识,称作QPN,和普通TCP/IP连接的五元组用途类似。长度为24bit。QPN有两个特殊编号:QP0用于子网管理接口SMI(Subnet Management Interface)。QP1用于通用服务接口GSI(General Service Interface),GSI是一组管理服务,其中最出名的就是CM(Communication Management),是一种在通信双方节点正式建立连接之前用来交换必须信息的一种方式。
SRQ:Shared Receive Queue,共享接收队列。每个QP都要有一个SQ和一个RQ,但在很多情况下RQ使用较少,因此运行多个QP共用同一个RQ,这个RQ称作SRQ。由于RDMA的recv操作需要预先准备好接收buffer并下发WQE,因此每个RQ都会消耗一定的内存资源,使用SRQ可以减少RQ数量,也就减少了预先准备buffer和WQE消耗的内存资源。一个QP只能在RQ和SRQ中选择一种。SRQ也需要属于指定的PD,因此SRQ不能被不同PD的QP共享。
SRQN:SRQ Number。SQ/RQ和QP是一一对应的,因此QPN就能标识SQ,但使用SRQ后SRQ和QP就不是一一对应的了,因此SRQ需要一个单独的标识符,也就是SRQN。
SRQ Limit:SRQ资源警戒阈值。由于SRQ被多个QP共享,其资源消耗速度可能比较快,因此提供了SRQ Limit配置功能。可以为SRQ设置一个资源警戒阈值/水位线,当SRQ中的WQE数量低于阈值时就会上报一个异步事件SRQ Limit Reached来提醒应用程序补充SRQ资源。
CQ:Completion Queue,完成队列。用于网卡反馈收发任务完成情况。每个WQ都必须有一个对应的CQ,但一个CQ可以同时对应多个WQ(SQ/RQ都可以)。WQ中的任务完成后就会在对应的CQ中生成一个CQE。SRQ中的(recv)任务完成后会在接收数据的目标QP的RQ对应的CQ中生成CQE。
CQE:Completion Queue Entry,完成队列项。每个CQE对应一个WQE的完成情况。
WR:Work Request,工作请求。WQE在用户态接口中的体现,用户态程序通过接口提交的WR会转化为WQE下发给网卡。
WC:Work Completion,工作完成。CQE在用户态接口中的体现,网卡反馈的CQE会被转化为WC后被用户态程序获取。
MR:Memory Region,内存区域。MR是注册到RDMA网卡的一块内存区域,RDMA网卡只能访问用户注册过的MR范围内的内存。注册时会在内存中创建MR内存的VA->PA映射页表,并pin住相应的物理页。之后RDMA网卡才能通过这个页表来获取用户态下发的VA对应的PA,从而访问到物理内存。这个过程和IOMMU注册和访问的过程类似,RDMA网卡实现了IOMMU的类似功能。
L_KEY:Local Key,本端秘钥。L_KEY/R_KEY长度为32位,前24位是索引,后8位是秘钥。索引用于HCA快速检索MR的地址转换表等信息,秘钥用于验证L_KEY/R_KEY的正确性。注册MR时由RDMA网卡生成。向网卡下发访问本地MR的操作时必须携带MR对应的正确L_KEY,否则本端网卡不会执行访问操作。
R_KEY:Remote Key,远端秘钥。注册MR时由RDMA网卡生成。向网卡下发访问远端MR的操作时必须携带MR对的正确R_KEY,否则远端网卡不会执行访问操作。
MW:Memory Window,内存窗口。用于让远端节点访问本端内存而创建的资源。MW需要绑定到已经创建的MR上,通过MW所能访问的内存是MR的一部分。每个MW有自己的权限控制,MR和MW的访问权限有四种:本端可读、本端可写、远端可读、远端可写。MW的意义在于它在已创建的MR基础上创建和使用,不涉及到页表创建等操作,因此操作的代价和危险性都较小,可以在用户态直接操作。因此可以在创建了一块大型MR后,再创建更细粒度的MW并分配不同访问权限来实现具体的功能。在MW的绑定操作中,会生成一个MW的R_KEY,远端必须使用这个R_KEY才能访问MW的内存空间。
PD:Protection Domain,保护域。可以将QP和MR等资源划分到不同的PD中。QP中的WQE只能请求访问属于同一PD的MR。
GID:Global Identifier,全局ID。用于标识RDMA设备节点,类似于IP地址或MAC地址。长度为128bit,格式有点像IPv6地址。
AH:Address Handle,地址句柄。这里的地址指的是用于标识RDMA通信端的地址,在tcp/ip协议通信中就是IP/端口。在UD类通信中,每次通信都需要指定对端地址,指定的方式就是提供AH。在通信前用户态程序需要先调用接口,注册对端地址,获取对应的AH,之后才能通过AH指定UD通信的对端。AH也要划分到PD中,QP只能使用同一个PD中的AH。
操作类型
Send:发送。和普通(Socket)网络通信中的send类似。对应的WQE中包含了待发送数据的buffer地址和长度。
Recv:接收。和普通(Socket)网络通信中的recv类似。对应的WQE中包含了接收数据的buffer地址和长度。但和socket的recv不同的是,socket的recv可以在收到收到对端send的数据后再调用,数据可以保存在缓存中。而RDMA的Recv操作必须在收到对端的Send前就将接收buffer信息下发给网卡。从这个角度来看,RDMA的Send和Recv更接近网卡/virtio的RX/TX逻辑。相当于为每对QP提供了一对VF/virtio ring实现用户态网络通信。需要注意的是RDMA的send、recv操作是消息/数据报粒度的,而不是tcp这种流式传输。从这个角度看也接近网卡/virtio的RX/TX逻辑。
Write:远程写。这个写就和socket的write大不相同了,对应的WQE总不仅包含本地buffer信息,还包含了对端节点的buffer地址信息。RDMA网卡会将对端地址信息附加在RDMA协议数据中,对端接收到数据后根据携带的buffer地址信息将数据内容存入指定地址中。
Read:远程读。WQE中包含对端节点的buffer地址信息。RDMA网卡将对端地址信息附加在RDMA协议数据中,对端接收到数据后根据携带的buffer地址信息,读取内存中的数据并封装到响应报文中,本端就能从响应报文中读取到需要的对端数据。
Post Send Request:下发Send类请求。Post Send中的send是指这类请求会主动向远端发送请求。这里的Send类请求包括Send、Write、Read三种操作类型,这三种类型的操作都会由发起方首先发送请求消息。
Post Receive Request:下发Recv类请求。Post Receive只包括Recv操作。
Post SRQ Recv:向SRQ下发Recv类请求。和Post Receive不同的是,Post Recv的操作对象是QP,实际上就是把WQE下发到QP的RQ中。Post SRQ Recv操作对象是SRQ而不是QP,因为SRQ是不属于单个QP的。
服务类型
TCP/IP协议族可以通过TCP协议提供可靠流式传输,也可以通过UDP协议提供不可靠的数据报传输。与之类似,RDMA也可以提供不同类型的传输服务。
RDMA传输服务属性维度和普通的网络传输服务是一样的:有连接/无连接(数据报),可靠/不可靠。
这里的有连接,指的是传输两端的QP是固定的,一个本端QP只能向一个远程QP收发数据,与TCP类似;而无连接传输则可以在每次传输中指定不同的远端和QP。
这里的可靠,与TCP的可靠传输基本相同,包括数据正确性、完整性和有序性。保证可靠性的方式和TCP等可靠传输协议类似,包括checksum、seq/ack机制等。
但RDMA中这两种属性是可以任意组合的,因此形成了四种服务类型:
RC:Reliable Connection,可靠连接传输。类似TCP。
RD:Reliable Datagram,可靠数据报传输。
UC:Unreliable Connection,不可靠连接传输。
UD:Unreliable Datagram,不可靠数据报传输。类似UDP。
其中RC和UD与TCP、UDP概念类似,使用最广。
Verbs
Verbs是使用RDMA时最常遇到的概念,Verbs有两层含义:
1. RDMA设备向外提供的功能的抽象描述,在各类RDMA标准/规范中都会有verbs部分,描述了RDMA设备应该通过什么操作方式提供什么样的能力。但这种描述是抽象的,不涉及操作方式和提供的能力具体应该如何实现。
在规范中定义了每种Verbs功能所需的使用权限,只有数据面相关的功能可以由普通用户直接调用,例如Post Send、Post Recv等,控制面的功能都只能由特权用户调用,例如Create QP、Register MR等。
2. 实现RDMA verbs抽象能力的一套API编程接口。verbs API基本上和RDMA verbs规范是对应的,用户态和内核态的应用程序都需要调用verbs API来使用verbs功能。大部分情况下verbs具体指的就是这套API。如果没有特别说明,本文其余部分的verbs都是指代verbs API。
广义的Verbs API主要包含两类接口:
IB_VERBS:与verbs规范对应的主要接口,有用户态和内核态两种形式,分别供用户态和内核态的应用使用。这两种verbs API基本是一致的,通过前缀ibv_和ib_区分用户态和内核态接口。用户态的API由rdma-core中的libibverbs等库提供,内核态的API则由rdma内核模块提供。例如ibv_create_qp/ib_create_qp用于创建qp,ibv_post_send/ib_post_send用于下发send类型操作。
内核的ib_系列API在内核代码的include/rdma/ib_verbs.h中声明,每个接口的注释说明了接口的用途和参数。
用户态的ibv_系列API在infiniband/verbs.h中声明,可以在ibv_create_qp(3) - Linux manual page上阅读和检索接口的文档。
狭义的Verbs API就是指IB_VERBS这套API。
RDMA_CM:用于提供连接管理和基于连接的RDMA功能API。以rdma_为前缀。这一系列接口功能分为两类:
CMA(Connection Management Abstraction),用于建立rdma连接、交换对端的GID,QPN等信息。之所以这类接口不放到IB_VERBS中,是因为这类接口虽然是为RDMA设备使用而提供的,但本身不一定是通过RDMA实现的,也不在verbs规范定义中。建连操作是基于socket实现的,只是向上提供的接口是关联的QP。例如rdma_listen用于监听cm建连请求、rdma_connect发起cm连接等。
CM VERBS,这类接口是在IB_VERBS接口上又封装了一层,同样提供RDMA通信功能。但这类接口是和上面的CMA接口是对应的,只能操作通过CMA建立的连接。
此外还有MAD(Management Datagram)等接口也是广义的Verbs API的一部分。用户态的MAD接口由libibumad提供。
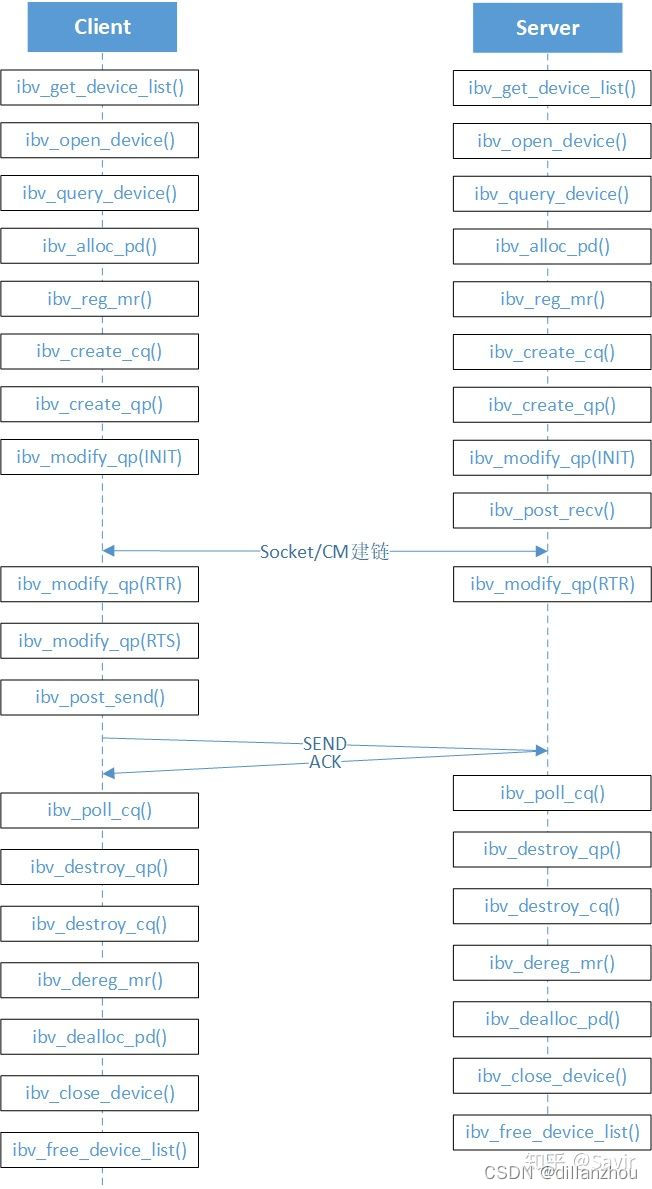
下图是一个简单的RDMA通信程序涉及的verbs接口调用序列。
软件栈
这里只讨论Linux上的RDMA软件栈。Linux上与RDMA相关的软件栈主要由两部分组成:
rdma-core:开源的RDMA用户态软件协议栈,repo为https://github.com/linux-rdma/rdma-core。rdma-core是rdma在用户态的主要组件。用户态的程序需要通过rdma-core提供的用户态verbs API来和内核中的rdma子系统、rdma设备驱动、以及rdma设备本身交互,来使用rdma通信功能。其中包括用户态库libibverbs、librdmacm和libibumad。不同的rdma设备有不同的内核驱动,这些设备驱动向用户态提供的操作接口和功能也各不相同,libibverbs对不同设备驱动进行了相应的适配,支持了当前主流的rdma设备驱动,包括rxe/siw这两种软件实现的rocev2/iwarp设备驱动。ibv_系列API就由rdma-core中的libibverbs提供。
kernel RDMA subsystem:开源的Linux内核中的RDMA软件栈,是Linux内核的一部分,主要包括内核的rdma子系统框架,以及各种rdma设备的驱动。ib_系列接口由其中的ib_core.ko提供。
除了上述开源社区发布的版本外,OFA和厂商基于社区版本也会发布自己的软件包:
ofed:OpenFabrics Enterprise Distribution,OFA负责开发和维护的开源软件包集合,其中包含了rdma用户态和内核态软件栈,以及一些测试工具和文档,以软件包(rpm、dpkg等)形式发布。ofed中提供了rdma-core和内核RDMA子系统的另一个版本,和前两者是互相替代的关系。ofed定期从前两个社区repo中获取最新版本的代码,适配主要的发行版,发布相应的软件包。
厂商版ofed:一些厂商会在开源ofed的基础上,增加一些私有的增强特性和一些专用的配置、测试工具,发布针对自家产品的ofed软件包。最常见的是mellanox的MLNX_OFED。
这样一来,就出现了3种rdma用户态/内核态的软件栈,虽然这3者的功能和接口基本相同,主体代码也都来自相同社区,但彼此之间仍然会存在一些版本差异和兼容性问题。例如如果安装了ofed/mlnx_ofed版本的内核rdma模块,内核原生的一些驱动和模块可能就会无法使用,例如rxe、siw等。
RDMA各个组件的关系如下图所示:
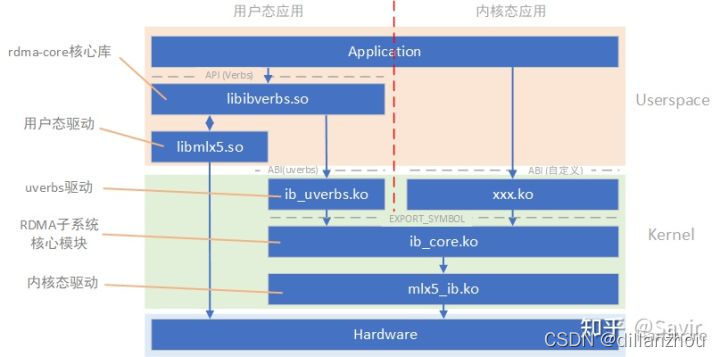
在介绍Verbs功能时提到,不同的Verbs功能需要不同的权限,大部分控制面功能都只有特权用户才能使用。在Verbs API的实现上也体现了这一点,用户态libibverbs提供的ibv_接口是普通用户就能够使用的,因此它能在用户态直接实现的只有数据面的接口,通过调用libmlx5.so等网卡对应的用户态驱动直接与HCA交互。其他控制面相关的ibv_接口,都需要通过系统调用进入内核态,通过内核检查调用操作合法后,再调用内核ib_core模块的ib_接口来实现。通过这种方式,可以避免普通用户态程序错误的或者恶意的操作HCA。此外,注册MR等操作需要在内核态建立VA到PA的映射页表,并pin住物理页。由于RDMA的实现并没有基于VFIO/IOMMU,因此这些操作需要在内核中完成。
用户态与内核态的接口是/dev/infiniband/uverbsN字符设备文件,libibverbs通过write这个文件向内核提交操作请求,ib_uverbs.ko负责解析write的内容,根据内容中的请求信息再去调用ib_core.ko提供的ib_接口。
RoCE
RoCE的全称是RDMA over Converged Ethernet,是一种可以在以太网环境下使用的RDMA技术。在2011年接触到RDMA网络时,使用的是Mellanox的Infiniband卡,这种IB卡使用的协议从链路层开始就是IB专用协议。因此使用这种网卡时,需要使用专门的IB交换机和带IB光模块的IB连接线,那时一条不长的IB连接线就要数千元。组建一套IB网络成本很高,还需要额外的网络规划部署工作,因此在一段时间后我们的产品中就不再使用IB网络了。RoCE和iWARP都是为了解决IB网络的成本和部署问题而产生的技术。通过在2/3/4层采用通用的ethernet/ip/tcp/udp协议,采用RoCE和iWARP技术的RDMA报文可以在普通的ethernet/ip网络环境和硬件设备下传输,避免了专门建设IB网络的成本和工作。
RoCE有两个版本,v1版本只有链路层使用了ethernet协议,v2版本则使用了ethernet/ip/udp作为链路层/网络层/传输层协议,协议规定了RoCEv2使用UDP端口4791。由于v2版本使用了ip协议,可以复用普通的ip路由器,因此得到了较广泛的应用。
需要注意的是,IB传输协议是假设自身处于无损网络下的。因此RoCE是基于融合以太网的,这里的融合以太网是指能够提供无损传输的以太网。RoCEv2通过ethernet和ip协议路由转发报文,因此要求这两层的转发设备都能提供无损传输。RoCEv2要求的无损传输是通过交换机和路由器的一些增强特性实现的。在以太网交换机上实现RoCE报文的无损传输需要交换机支持PFC(Priority Flow Control),PFC通过802.1q协议定义的vlan标签实现基于优先级的流量传输控制。当出现网络拥塞时,PFC会优先保障高优先级的链路报文不被丢弃,从而实现某种程度的无损传输。如果RoCEv2报文需要经过路由,需要支持将vlan标签中的优先级映射到IP的DSCP字段中,让路由器通过DSCP字段保障RoCEv2报文的优先传输,或者要求路由器支持vlan标签中的优先级字段PCP。
可见,RoCE虽然能在ethernet/ip网络上传输,但对网络中的设备仍是有一定的功能要求的。此外,要让交换机和路由器支持RoCE报文的优先传输,需要在RDMA网卡和交换机上都配置上对应的vlan和标签信息。RoCE对网络设备的要求以及大规模部署时的配置复杂度,使其使用规模受到了限制,很少有超过一千台主机的集群配置通过RoCEv2通信。Mellanox实现了自行改进的RoCE协议,来支持RoCE在有损网络(Lossy)上的传输。但到目前为止这种协议虽然可用,但在丢包场景下的性能较差,且无法和普通的RoCEv2协议兼容互通,因此实际使用场景有限。
ROCEv2同样需要专门的网卡才能支持stack offloading和zero copy等特性,Mellanox的CX-5/CX-6等网卡可以支持硬件ROCEv2协议。Linux内核中也支持了基于软件实现的ROCEv2,模块名为rxe。rxe模拟实现了ROCEv2设备,并且在libibverbs中也提供了相应的支持。应用程序可以通过verbs接口与rxe设备交互来实现RDMA通信,而不需要通过支持RDMA的网卡。rxe模块会根据ROCEv2协议规范,完成IB层传输协议的封装,之后通过Linux内核协议栈实现UDP/IP/Ethernet层的封装,最终通过普通的以太网网卡将报文发出。
使用rxe软件实现的RDMA通信当然就失去了hardware stack offloading和数据面不需要syscall的优势,但仍然有RDMA交互模式以及zero copy方面的一些优势。此外通过rxe理论上可以让部分对高性能网络没有需求的设备也加入到RDMA网络中来,而无需配备专门的RDMA网卡。
iWARP
iWARP的全称是Internet Wide Area RDMA Protocol,虽然RDMA Consortium表示iWARP不是一个缩写,也不仅仅适用于广域网,但在RDMA Consortium几个创始厂商以及主要玩家intel、chelsio的文档中都能找到这个名词的全称。
iWARP的历史比ROCE更久一些,在Infiniband协议和产品出现后,许多厂商认同RDMA这种网络模式,但对IB协议和设备的前景并不看好。因此,这些厂商成立了RDMA Consortium,开始在主流的Ethernet/IP/TCP协议族基础上设计一种能在传统网络设备上传输的RDMA协议,也就是iWARP。和IB与ROCE不同,iWARP通过TCP协议在传输层保证了在有损网络中的可靠传输,因此可以用于广域网、互联网等存在丢包、乱序等现象的网络环境。
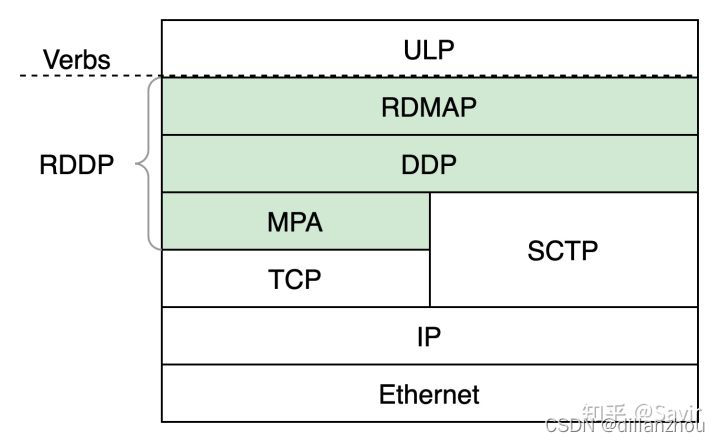
如上图所示,iWARP协议族(图中的RDDP是IETF最早对这套协议的称呼)由3层协议构成,由下向上分别是:
1. MPA:Marker Protocol data unit Aligned framing,数据单元封包标识协议。用于在使用TCP协议传输iWARP数据时标识上层协议消息的起止位置。RDMA通信是基于消息的,而TCP协议只支持流式传输,这就导致接收端需要根据TCP载荷中的上层协议信息来分解和重组出RDMA消息,MPA就专门用于提供这个消息标记能力。从上图可见,iWARP也可以使用SCTP作为传输层,这时是不需要使用MPA协议的,因为SCTP本身就支持数据报形式传输。
2. DDP:Direct Data Placement Protocol,直接数据放置协议。顾名思义,DDP协议用于说明如何将报文中的数据直接放置到内存中,从而实现RDMA语义。网卡可以根据DDP协议头中的信息,将DDP报文的载荷数据直接放置到协议信息指定的内存地址中,而不需要CPU和内核/应用逻辑参与。
3. RDMAP:Remote Direct Memory Access Protocol,RDMA协议。用于描述RDMA各类操作语义的协议。通过这个协议,操作发起方可以将自己的操作通知给接收方,接收方将操作的结果反馈给发起方。
支持iWARP协议RDMA功能的网卡主要有Chelsio的T6和Intel的X722、E810等。和支持RoCEv2的rxe类似,Linux内核中也有软件支持iWARP的模块,名称是siw。
iWARP虽然由3层协议构成,但每一层的功能都很清晰和单纯,因此整体上也并没有比RoCEv2复杂太多。关于RoCEv2和iWARP的优劣,两个阵营的主要厂商(其实就是Mellanox和Chelsio、Intel)写了多篇文章赤裸裸的互相攻击:
https://www.mellanox.com/related-docs/whitepapers/WP_RoCE_vs_iWARP.pdf
https://www.chelsio.com/wp-content/uploads/resources/iwarp-or-roce-rdma.pdf
其实两者的主要差异就在于:iWARP基于TCP协议,硬件实现复杂,在IDC机房内部传输这种可靠性较高的环境下,TCP协议的可靠传输机制带来的价值不易体现,而硬件实现TCP协议的复杂性则可能带来成本和时延的上升。RoCEv2基于UDP协议,硬件实现要简单的多,上层基于IB协议,对于Mellanox这种老牌IB厂商还节省了协议开发成本并掌握了技术主导权。
虽然双方提供的数据并不一致,但可以看到目前大体的情况是iWARP网卡的时延会高于RoCEv2网卡,但RoCEv2在不可靠网络下仍然基本不可用。iWARP协议在2014年后就基本稳定了,厂商的工作主要是将iWARP和TCP/IP协议在网卡上实现的更加高效。而RoCE则仍然有厂商(主要是Mellanox,也包括华为和其他一些厂商和研究者)在尝试改进其拥塞控制和可靠传输机制,但这种机制必然和TCP协议比较类似。如何在获得可靠传输能力的同时避免复杂度和性能上的代价,目前仍然没有一个很好的答案。
从目前的使用情况看,RoCEv2的市场占用率要高于iWARP,但这很大程度上也和RDMA/IB技术与市场的发展历史过程有关。目前的RDMA市场并不是很大,使用场景也比较有限,RoCE和iWARP的竞争还会随着RDMA市场和应用的发展继续进行很长一段时间。
参考信息
本文参考了RDMA杂谈 - 知乎中的很多信息,在这个专栏中有许多概念更详细的介绍。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









