







目录
什么是CUDA?
CUDA(Compute Unified Device Architecture,统一计算设备架构),是显卡厂商NVIDIA推出的一种并行计算平台和编程模型。
CUDA的核心思想是将异构计算平台(如CPU和GPU)抽象为一个统一的编程模型。这种统一性使得开发者能够使用C/C++语言来编写同时针对CPU和GPU的程序,而无需深入了解底层硬件的复杂细节。CUDA通过提供一系列的API和库函数,使得程序员可以轻松地将计算任务分配给最适合的device,从而充分发挥异构计算系统的性能优势。
CUDA 在整个计算体系中的层级可参考如下所示:
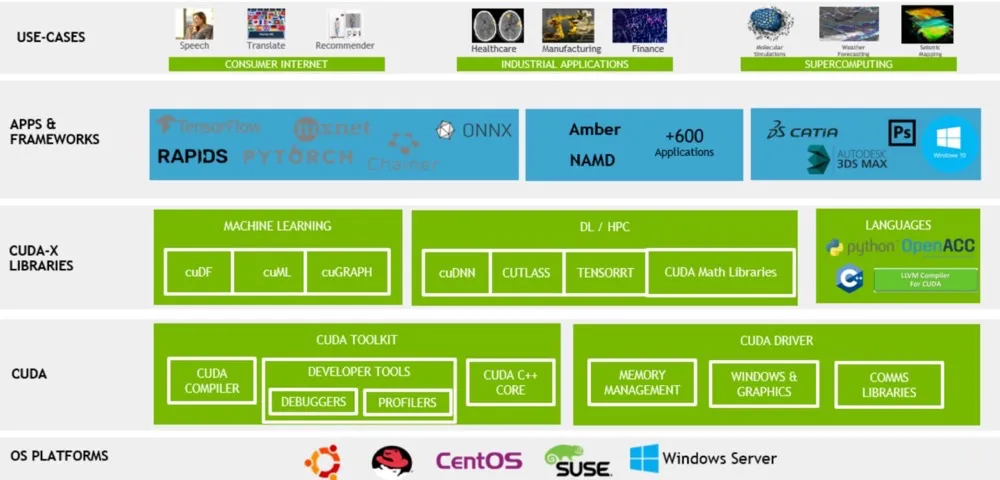
“统一”的含义是指该架构将不同类型的计算设备(主要是CPU和GPU)整合到一个统一的编程模型中,开发者可以使用相同的编程语言和工具集,在CPU和GPU上执行计算任务,而无为 CPU 和 GPU 分别编写完全不同的代码(既同时开发 CPU 和 GPU 上的共同程序),这种统一性简化了并行计算的开发流程
传统方式:CPU 和 GPU 编程是完全分离的,GPU 编程通常需要专门的图形 API(如 OpenGL、DirectX)。
CUDA 的方式:通过 CUDA,开发者可以用熟悉的编程语言(如 C/C++)直接编写 GPU 程序,无需学习复杂的图形 API。
什么是CUDA编程?
理解了CUDA就容易知道,CUDA 编程 是指利用 CUDA(Compute Unified Device Architecture)平台,编写能够在 NVIDIA GPU 上运行的并行计算程序。
为什么需要CUDA?
GPU的并行计算能力,特别是在CUDA架构的支持下,使得成千上万个线程可以同时执行,从而极大地提升了深度学习模型的训练速度和效率。
许多主流的深度学习框架都依赖于CUDA进行加速。包括Caffe2、Keras、MXNet、Torch和PyTorch在内的广泛使用的框架,都是基于CUDA架构进行优化的。
Nvidia CUDA是如何运作的?
(摘自:一文了解NVIDIA CUDA)
前置概念
在解析 CUDA 实现原理之前,我们先来了解一下CUDA中常见的两个概念:CUDA工具包和CUDA驱动程序。
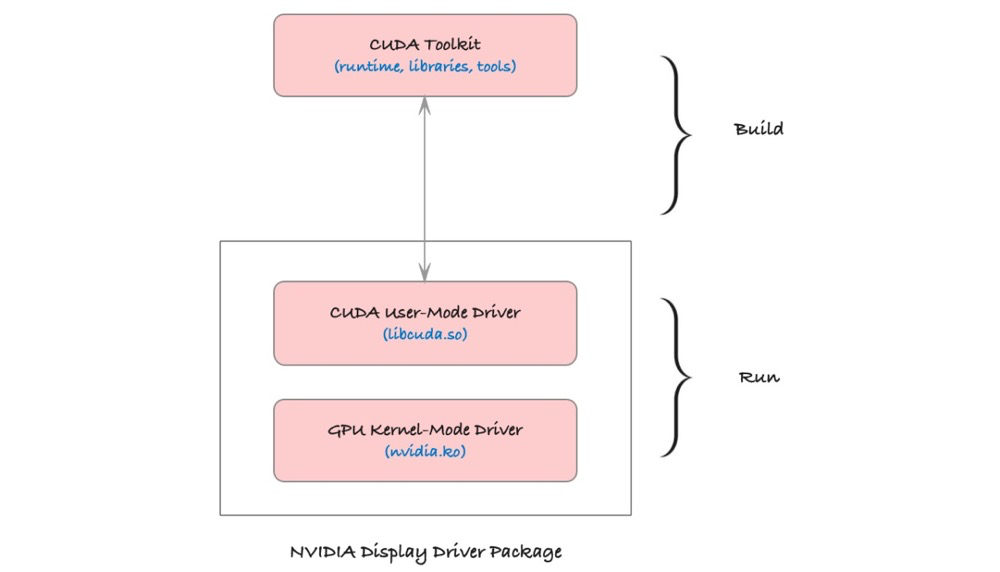
CUDA Toolkit
CUDA Toolkit 是 NVIDIA 公司提供的一套开发工具集,提供了一系列工具、库和 API,使得开发者能够将复杂的计算任务(从CPU)卸载到 GPU 上执行,从而实现加速。
CUDA Toolkit的 核心 组成部分如下:
-
CUDA编译器(nvcc):用于将CUDA C/C++代码编译为GPU可执行程序的编译器。
-
CUDA库:CUDA Toolkit包含多个加速不同应用领域的预编写库 ,例如cuBLAS、cuFFT、cuFFT以及Thrust等C++模板库。
-
调试和分析工具:如CUDA-GDB、CUDA-MEMCHECK等,用于排查GPU程序错误和性能瓶颈。NVIDIA Nsight还可以对GPU的性能进行深度分析。
CUDA Driver
CUDA Driver是负责(应用程序)与GPU硬件通信的底层软件,它充当了应用程序和GPU之间的桥梁。
CUDA Driver的主要任务是将来自CUDA程序的高层指令转化为GPU能够执行的低层指令,并管理GPU资源的分配。具体来说,CUDA Driver有以下几个关键功能:
-
硬件抽象:CUDA Driver将高层的并行计算请求转化为GPU硬件可以理解的操作,确保程序能够在不同的NVIDIA GPU上运行,而不必依赖于特定的硬件架构。
-
内存管理:CUDA Driver负责管理主机(CPU)和设备(GPU)之间的内存传输,以及在GPU上的内存分配。它确保CUDA程序可以高效地访问和传输需要处理的数据。
-
多进程和多GPU支持:CUDA Driver管理多进程环境下的GPU访问,确保多个应用程序或进程能够安全地共享同一台设备。它还支持多GPU系统的管理,允许在多个GPU之间分配计算任务。
针对CUDA Toolkit和CUDA Driver的关系的理解:
工具与执行的关系:
可以理解为:
- CUDA Toolkit:用来编写和编译GPU程序的工具包,
- CUDA Driver:则是执行这些程序的基础设施。
所以,为了运行CUDA程序,系统需要同时安装相应版本的CUDA Toolkit和CUDA Driver。
工作原理
那么, CUDA 到底是如何工作的?
背景:
CPU设计目标是顺序处理,擅长一次执行一项任务。CPU的内核数量有限,通常只有几个高性能内核,但在处理需要大规模并行计算的任务时效率较低。
GPU由数千个较小且更专注于并行处理的内核组成,能够在同一时间执行大量任务。适合大规模、计算密集型操作。
价值:
1,任务拆分和转移到GPU并行处理
而CUDA允许开发人员利用C、C++等编程语言,并结合NVIDIA提供的特殊扩展指令集,来编写能够在GPU上并行执行的代码,将计算密集型任务的关键部分从CPU转移到GPU,利用其并行处理能力加快任务完成的速度。
CUDA并行计算的核心概念是将大型计算任务拆分为许多可以在不同GPU内核上同时执行的较小子任务。通过这种划分方式,原本由单个CPU串行执行的任务,能够在GPU的数千个内核上并行运行,从而大幅缩短计算时间。
2,优化CPU和GPU之间的数据传输
除了显著的速度提升,CUDA平台还提供了其他优化和简化计算的工具。例如,NVIDIA的CUDA核心不仅提供了卓越的并行计算能力,还通过统一的虚拟地址空间简化了CPU和GPU之间的内存管理。借助这一功能,开发者可以更轻松地在主机(CPU)和设备(GPU)之间共享数据。
3,预置各种高性能库
此外,CUDA平台还包含一系列专为GPU计算优化的高性能库,如cuBLAS(线性代数)、cuDNN(深度学习加速)和Thrust(并行算法库)。大幅降低了开发难度。
通过结合GPU并行架构的优势和CUDA平台的高效编程模型,开发人员能够以更快的速度解决复杂的计算任务。
CUDA特性
CUDA(Compute Unified Device Architecture,统一计算设备架构),“统一”(Unified)这个词体现了 CUDA 设计的一个重要理念,“统一”在这里有以下几层含义:
1. 统一的编程模型
CUDA 提供了一种统一的编程模型,使得开发者可以用同一种编程语言(如 C/C++、Python 等)和类似的编程逻辑,同时开发 CPU 和 GPU 上的程序。这种统一性简化了并行计算的开发流程,开发者不需要为 CPU 和 GPU 分别编写完全不同的代码。
-
传统方式:CPU 和 GPU 编程是完全分离的,GPU 编程通常需要专门的图形 API(如 OpenGL、DirectX)。
-
CUDA 的方式:通过 CUDA,开发者可以用熟悉的编程语言(如 C/C++)直接编写 GPU 程序,无需学习复杂的图形 API。
2. 统一的硬件架构
CUDA 的设计使得 NVIDIA GPU 的硬件架构能够统一支持多种计算任务,而不仅仅是图形渲染。GPU 最初是为图形处理设计的,但 CUDA 将其扩展为一种通用的并行计算设备,可以处理科学计算、机器学习、数据分析等多种任务。
-
传统 GPU:只能用于图形渲染。
-
CUDA GPU:既可以用于图形渲染,也可以用于通用计算(GPGPU,General-Purpose computing on GPU)。
3. 统一的内存访问模型
CUDA 提供了一种统一的内存访问模型,使得 CPU 和 GPU 可以共享数据,简化了数据交换的过程。通过 CUDA 的统一内存(Unified Memory)技术,CPU 和 GPU 可以访问同一块内存空间,而不需要开发者手动管理数据在 CPU 和 GPU 之间的传输。
-
传统方式:CPU 和 GPU 有各自独立的内存空间,数据需要在两者之间显式拷贝。
-
CUDA 的方式:通过统一内存,CPU 和 GPU 可以透明地访问同一块内存,减少了编程复杂性。
4. 统一的开发工具
CUDA 提供了一套统一的开发工具(如 CUDA Toolkit),包括编译器、调试器、性能分析工具等,这些工具为开发者提供了完整的支持,使得从开发到优化的整个流程更加高效和一致。
CUDA 编程的核心概念
GPU 与 CPU 的区别
CPU:适合处理复杂的串行任务,核心数量较少(通常为 4-16 个),但每个核心的性能较强。
GPU:适合处理大规模的并行任务,核心数量非常多(通常为数千个),但每个核心的性能较弱。
CUDA 编程的核心思想是将适合并行处理的任务(如图像处理、矩阵运算、机器学习等)交给 GPU 执行,从而大幅提升计算速度。
CUDA 编程模型
CUDA 扩展了 C/C++ 语言,允许开发者在代码中直接定义 GPU 上运行的函数(称为 核函数,Kernel)。
开发者可以通过 CUDA 控制 GPU 的线程层次结构,将任务分配给成千上万的线程并行执行。
线程层次结构
线程(Thread):最基本的执行单元。
线程块(Block):一组线程,可以互相协作和共享内存。
网格(Grid):一组线程块,构成一个完整的计算任务。
内存模型
CUDA 提供了多种内存类型,包括全局内存、共享内存、常量内存和寄存器等。开发者需要根据任务特点合理使用这些内存,以优化性能。
CUDA 编程的基本步骤
-
1 分配内存
-
在 GPU 上分配内存,用于存储输入数据和输出结果。
-
例如:使用
cudaMalloc分配 GPU 内存。
-
-
2 数据传输
-
将数据从 CPU 内存拷贝到 GPU 内存。
-
例如:使用
cudaMemcpy进行数据传输。
-
-
3 编写核函数
-
定义在 GPU 上执行的核函数(Kernel),核函数会被多个线程并行执行。
-
例如:
__global__ void vectorAdd(float* A, float* B, float* C, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { C[idx] = A[idx] + B[idx]; } }
-
-
4 启动核函数
-
调用核函数,并指定线程块和网格的大小。
-
例如:
vectorAdd<<<numBlocks, threadsPerBlock>>>(d_A, d_B, d_C, N);
-
-
5 结果回传
-
将计算结果从 GPU 内存拷贝回 CPU 内存。
-
例如:使用
cudaMemcpy将数据从 GPU 拷贝到 CPU。
-
-
6 释放资源
-
释放 GPU 上分配的内存。
-
例如:使用
cudaFree释放内存。
-
CUDA 编程的优势
-
高性能计算
-
GPU 的并行计算能力远超 CPU,适合处理大规模数据并行任务。
-
例如:深度学习训练、科学计算、图像处理等。
-
-
灵活性
-
CUDA 支持 C/C++、Python 等多种编程语言,开发者可以使用熟悉的工具进行开发。
-
-
广泛的应用领域
-
深度学习、计算机视觉、物理模拟、金融分析、医学成像等领域都广泛使用 CUDA 加速计算。
-
示例代码:向量加法
以下是一个简单的 CUDA 程序,实现两个向量的加法:
#include <iostream>
#include <cuda_runtime.h>
// 核函数:向量加法
__global__ void vectorAdd(float* A, float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
int N = 1024; // 向量大小
size_t size = N * sizeof(float);
// 分配主机内存
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// 初始化数据
for (int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
// 分配设备内存
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// 将数据拷贝到设备
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// 启动核函数
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 将结果拷贝回主机
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 输出结果
for (int i = 0; i < 10; i++) {
std::cout << h_C[i] << " ";
}
std::cout << std::endl;
// 释放内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
总结
CUDA 编程是一种利用 NVIDIA GPU 进行并行计算的技术,通过编写核函数并合理管理内存和线程,可以显著加速计算密集型任务。它在深度学习、科学计算、图形处理等领域有广泛应用。


















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









