







 本文详细介绍了CUDA编程技术在人工智能中的应用,包括CUDA的基本概念、GPU性能指标、CUDA编程模型(如线程和内存管理)、nvcc工作流程以及内核函数的编写。此外,还涵盖了错误处理和系统GPU查询等关键知识点。
本文详细介绍了CUDA编程技术在人工智能中的应用,包括CUDA的基本概念、GPU性能指标、CUDA编程模型(如线程和内存管理)、nvcc工作流程以及内核函数的编写。此外,还涵盖了错误处理和系统GPU查询等关键知识点。
文章目录
0. CURA Runtime API
https://docs.nvidia.com/cuda/cuda-runtime-api/index.html
1. CUDA人工智能编程
1.1. CUDA介绍
- CUDA(Compute Unified Device Architecture)
- AI技术的繁荣和AI应用场景的逐渐丰富,AI模型的训练、大数据分析都对系统计算能力提出了更高的需求,CUDA平台都对此能够提供很好的计算支持
- 主流的AI框架如TensorFlow、Caffe、Pytorch都依赖于CUDA平台的强大计算能力来完成模型训练
1.2. 课程内容
- 开发环境搭建
- CUDA线程模型
- CUDA内存模型
- CUDA流和事件
- 底层指令优化
- CUDA调试
2. 异构计算和并行计算
2.1. 什么是并行计算
- 任务并行,多个任务同时执行
- 数据并行,多个数据同时被执行
- 块分
- 循环分块
2.2. 什么是异构计算
异构计算指在具有多种类型处理(CPU和GPU)的系统中完成的计算
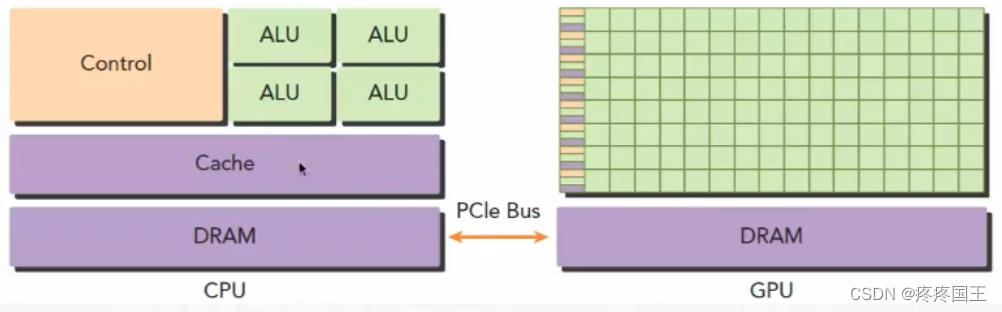
GPU上进行并行计算(主要是数据并行)
3. CUDA介绍
3.1. GPU的性能指标
- GPU核心数(core number)
- GPU内存容量
- 计算峰值,每秒单精度或者双精度的运算能力
- 内存带宽,每秒读出或者写入GPU内存的数据量
3.2. 什么是CUDA
图形计算 -> 通用计算
-
CUDA C是对ANSI C的扩展
-
CUDA平台提供了驱动层接口(Driver API)和运行时接口(Runtime API)
-
基于CUPA平台开发的代码包含主机代码和设备代码
3.3. 如何学习CUDA
- CUDA C编程时只需要编写顺序执行的程序,在程序代码中不需要有多线程的处理
- 要深刻理解CUDA平台GPU的内存架构和线程架构
- 掌握CUDA平台常用的性能分析和调优工具
- NVIDIA Nsight
- CUDA-GDB
- 图形化性能分析工具
4. 系统GPU查询
- 系统GPU查询
lspci |grep nvidia
硬件是否支持CUDA查询: https://developer.nvidia.com/cuda-gpus
- GPU计算能力(compute capability)
MajorVersion.MinorVersion
5. Linux系统
- 系统版本
- gcc
- 内核头文件
sudo apt-get install linux-header-$(uname -r)
6. CUDA安装
安装完成后,验证
- 驱动版本
cat /proc/driver/nvidia/version
- nvcc编译器版本
nvcc -V
7. 查询GPU信息
- nvidia-smi 管理和检测GPU
8. CUDA编程模型
8.1. 什么是编程模型
- 对底层计算机硬件架构的抽象表达
- 编程模型作为应用程序和底层架构的桥梁
- 编程模型体现在程序开发语言和开发平台中
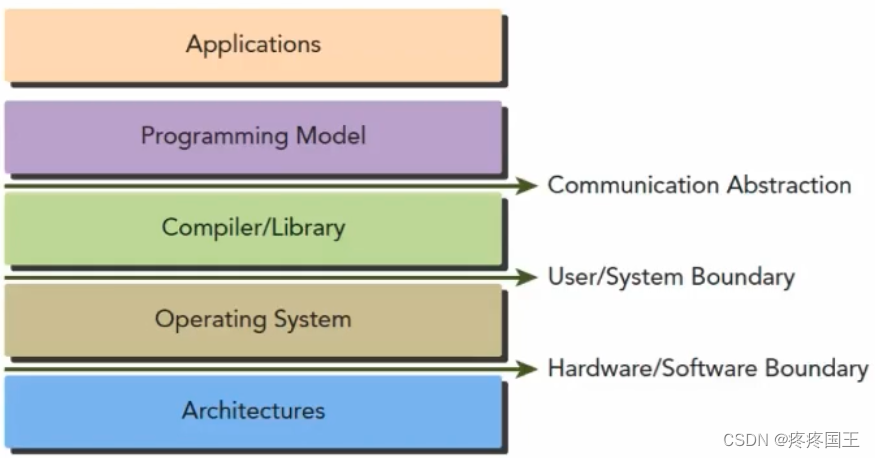
8.2. CUDA编程模型
- CUDA平台对线程的管理
- CUDA平台对内存访问控制
- 主机内存和GPU设备内存
- cpu和GPU之间内存数据传递
- 内核函数(kernel function)
- 内核代码本身不包含任何并行性,由gpu协调处理线程执行内核
- CPU和GPU处于一步执行状态
9. CUDA线程模型
9.1. 线程模型结构
-
关键概念: grid(网格)和block(块)
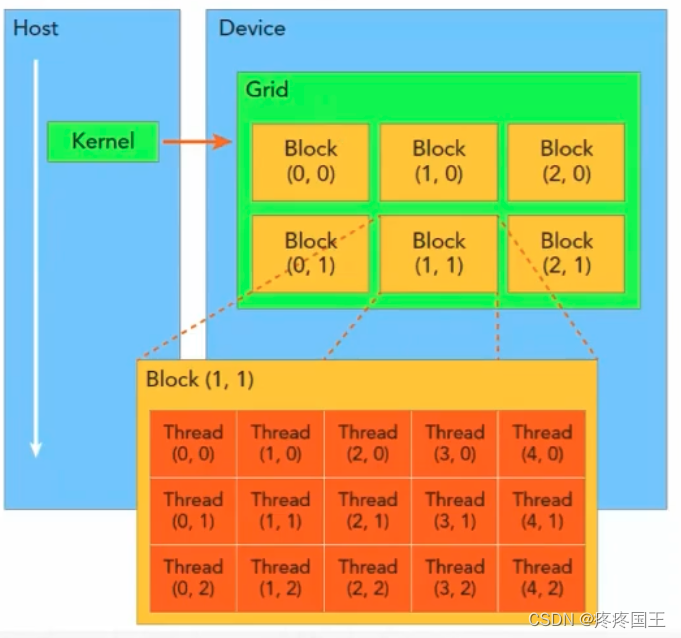
-
内核(kernel)执行时所产生的所有线程称为grid
-
grid由多个block构成
-
相同block中的线程可以通过同步机制和块内共享内存做数据交互(不同的block之间无法数据交互)
9.2. 线程管理
- 线程标识
- blockIdx和threadIdx唯一标识每一个线程
- 线程标识由CUDA平台内置和分配,可以在内核程序中访问
- 两者均为三维向量, 访问方法blockIdx.x ,blockIdx.y, blockIdx.z, threadIdx.x,threadIdx.y,threadIdx.z
- 线程模型纬度(标识grid和block)
- 内置变量blockDim和gridDim
- 两者也是三维向量
- 线程ID(thread ID)和线程标识符换算关系
10. CUDA内存模型
10.1 内存架构
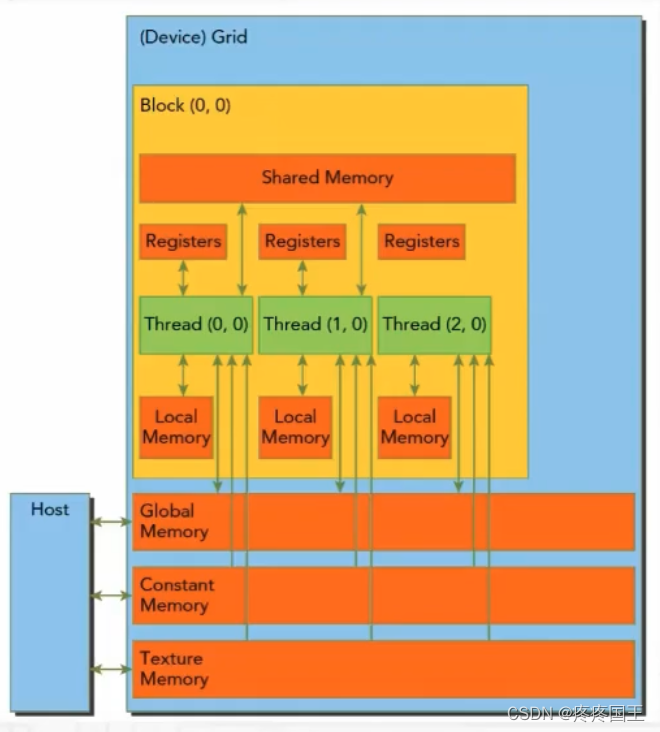
- 寄存器
- GPU中访问最快的内存,为每个线程私有
- 本地内存
- 无法存入寄存器的数据存于本地内存,如较大的数据结构
- 共享内存
- 由__shared__修饰的变量都保存在共享内存中,是片上存储空间,具有低延迟和高带宽的特点
- 常量内存
- 由__constant__修饰,可以被所有内核代码访问
- 全局内存
- 数量大,使用最多,延迟最大
- 静态分配:__device__关键字
- 动态分配: 主机中使用内存管理函数
- 纹理内存
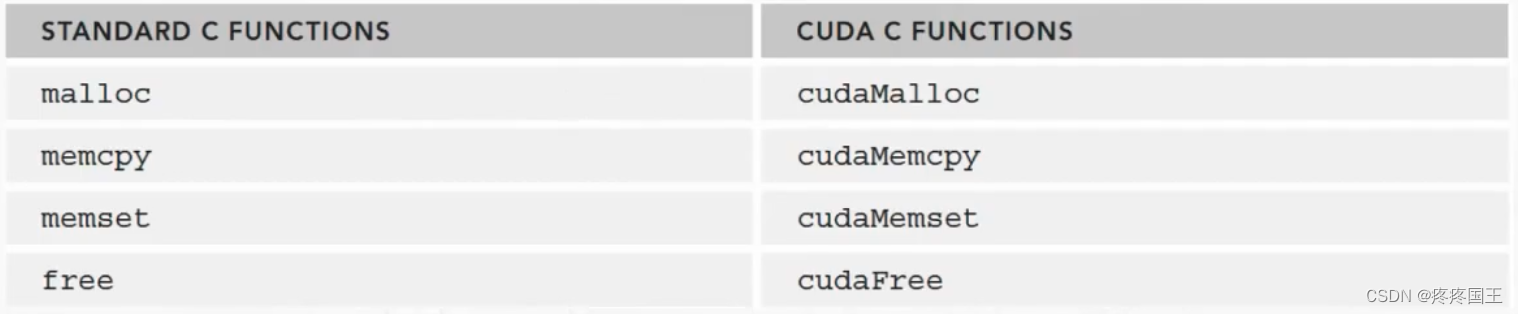
内存管理接口函数:
11. nvcc工作流程
11.1. nvcc是什么
- 类似于gcc
- nvcc将ptx或者c语言编写的代码编译为可执行程序
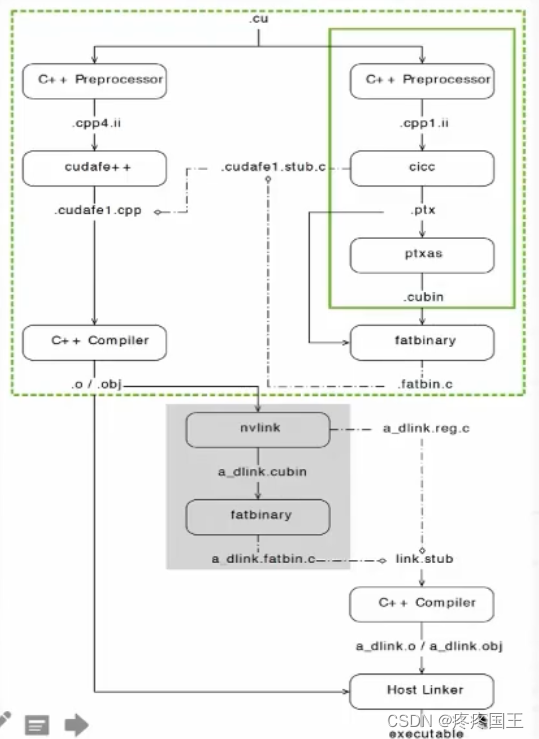
11.2. nvcc工作流程
- CUDA程序默认编译模式为全程序编译模式(主机代码和设备代码同时编译)
- 分离源文件和GPU相关的内核代码,编译为cubin或者PTX中间文件,保存在fatbinary中
- 分离源文件的主机代码,使用系统中可用的编译器(如gcc)进行编译,并将fatbinary嵌入其中
- 链接,相关的CUDA运行库会被链接
nvcc入参文档:
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
12. CUDA内核函数
-
kernel function被GPU上线程并发执行
-
内核函数定义
- global void kernel_name(argument list)
-
CUDA程序中的函数修饰符(function qualifier)

-
内核函数限制条件:
- 只能访问GPU内存
- 必须返回void
- 不能使用变长参数
- 不能使用静态变量
- 不能使用函数指针
- 内核函数具有异步性
Hello word内核函数
- code:
#inlcude <stdio.h>
__global__ void helloFromGPU()
{
printf("Hello World From GPU\n");
}
int main()
{
printf("Hello World From CPU\n");
helloFromGPU<<<1,10>>>(); //会被10个线程执行
cudaDeviceReset();
return 0;
}
- 编译
nvcc helloFromGPU.cu --output-file helloGPU
13. 获取线程索引
- 线程索引包含blockIdx和threadIdx
- 通过线程索引可以为线程分配数据
- 线程维度包含网格(grid)纬度gridDim、块(block)纬度blockDim定义
示例代码:
#include "common/common.h"
#include <stdio.h>
__global__ void helloFromGPU()
{
printf("blockDim:x=%d,y=%d,z=%d,gridDim:x=%d,y=%d,z=%d Current threadIdx:x=%d,y=%d,z=%d\n",blockDim.x,blockDim.y,blockDim.z,gridDim.x, gridDim.y, gridDim.z,threadIdx.x,threadIdx.y,threadIdx.z);
}
int main(int argc,char **argc)
{
printf("Hello World from CPU!\n");
dim3 grid;
grid.x = 2;
grid.y = 2;
dim3 block;
block.x = 2;
block.y = 2;
helloFromGPU<<<grid,block>>>();
cudaDeviceReset();
return 0;
}
14. CUDA错误处理
14.1. 错误代码
enum cudaError文档说明:
https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html
14.2. 错误处理函数
- cudaGetErrorName(cudaError_t error)
- cudaGetErrorString(cudaError_t errr)
15. 运行时GPU信息查询
文档:
https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__DEVICE.html#group__CUDART__DEVICE_1g18808e54893cfcaafefeab31a73cc55f
- 获取GPU数量:cudaGetDeviceCount
- 设置需要使用的GPU: cudaSetDevice
- 获取GPU信息: cudaGetDeviceProperties















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









