







Hierarchical Attention Networks for Document Classifification
Title:Hierarchical Attention Networks for Document Classifification
Author:Zichao Yang, Diyi Yang, Chris Dyer , Xiaodong He, Alex Smola , Eduard Hovy
Institute:Carnegie Mellon University, Microsoft Research, Redmond
Motivation
可能很多刚接触深度学习做NLP项目时会使用RNN对用户评论进行分类。但刚使用RNN时会遇到一个问题,就是当处理的序列较长时就会导致网络容易忘记之前的东西,为解决这一问题,专家提出“注意力”机制,使得网络工作过程中可以像人一样将注意力放在不同部位,本篇论文针对文本分类问题提出了层级注意力模型结合双向RNN实现对文本的分类。
Model
层级“注意力”网络的网络结构可以被看作为两部分,第一部分为词“注意”部分,另一部分为句“注意”部分。整个网络通过将一个句子分割为几部分(例如可以用“,”将一句话分为几个小句子),对于每部分,都使用双向RNN结合“注意力”机制将小句子映射为一个向量,然后对于映射得到的一组序列向量,我们再通过一层双向RNN结合“注意力”机制实现对文本的分类。

-
基于GRU的词序列编码器
使用GRU的门机制来记录序列当前的状态。隐藏层有两个门(gate),重置门(reset gate)和更新门(update gate)。这两个门一起来控制当前状态有多少信息要更新。在时刻t,隐藏层状态的计算公式:
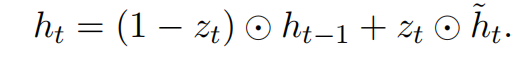
更新门是用来决定有多少过去的信息被保留,以及有多少新信息被加进来:

这里是在时刻t输入的单词的词向量,候选状态的计算方法和普通的RNN相似:
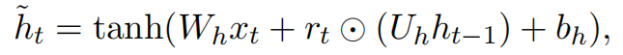
重置门决定有多少过去的信息作用于候选状态,如果是0,即忘记之前的所有状态:
![]()
2、层次化attention:
Word Encoder:
由词序列wit(t属于[0,T])组成的句子,首先把词转化成词向量xit=Wewit然后用双向的GRU网络,可以将正向和反向的上下文信息结合起来,获得隐藏层输出。

对于一个给定的词语wit,经过GRU网络后,我们获得了一种新的表示
![]() 包含了wit两个方向的信息
包含了wit两个方向的信息
Word Attention:
attention机制的目的是要把一个句子中,对句子的含义最重要,贡献最大的词语找出来。我们通过将hit输入到一个单层的感知机(MLP)中得到的结果uit作为hit的隐含表示。
为了衡量单词的重要性,我们用uit和一个随机初始化的上下文向量uw的相似度来表示,然后经过softmax操作获得了一个归一化的attention权重矩阵,代表句子i中第t个词的权重。其中uw是在训练网络的过程中获得的。
有了attention权重矩阵以后,我们可以将句子向量si看作组成这些句子的词向量的加权求和。

Sentence Encoder:
使用双向GRU对句子进行encode:
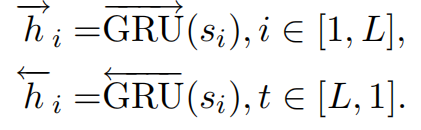
Sentence Attention:
和词级别的attention类似,提出一个句子级别的上下文向量us来衡量一个句子在整篇文档中的重要性。

最后使用softmax分类器对文本进行分类:
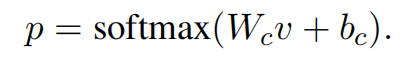
损失函数为:
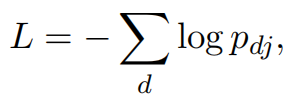
Result
作者分别对Yelp reviews、IMDB reviews、Yahoo answers、Amazon reviews进行实验。作者分别将该方法与其他方法进行对比


作者分别分析了模型对于单词“good”及“bad”的分配情况。图是对于单词“good”的权重分布情况,其中(a)是总体的分布情况,(b)-(f)分别是在由差评逐渐到好评的过度的过程中“good”的权重的变化情况。从图中可以看出,随着好评程度的不断上升,“good”所获得的权重越大,这说明,网络能够自动的将“注意力”放在和好评更相关的词汇上。
同样对“bad”做测试时,网络在差评的时候会更加将注意力放在“bad”词汇上。


作者对网络所分配的注意力结果进行可视化,从图中分析可以看出,像“delicious”、“terrible”、“amazing”这样的形容词会获得较大的权重,而其对应的句子也会获得较大的权重。因此该模型确实能够捕获到有助于对文本进行分类的词汇。

Conclusions
本文提出了一种基于层次化attention的文本分类模型,可以利用attention机制识别出一句话中比较重要的词语,利用重要的词语形成句子的表示,同样识别出重要的句子,利用重要句子表示来形成整篇文本的表示。实验证明,该模型确实比基准模型获得了更好的效果,可视化分析也表明,该模型能很好地识别出重要的句子和词语。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









