







A Co-Matching Model for Multi-choice Reading Comprehension
Title:A Co-Matching Model for Multi-choice Reading Comprehension
Author:Shuohang Wang,Mo Yu,Shiyu Chang2,Jing Jiang,School of Information System, Singapore Management University IBM Research
Motivation
多项选择式阅读理解有三个句子成分:passage、question、choice,以往的做法用句子匹配的方式,比如把(question,choice)连在一起看成一个句子,然后与passage做匹配,如果这个choice是正确答案,那么匹配结果为1。但是question和choice之间没有交互的信息。或者先让passage和question做匹配,匹配出一个向量,然后让这个向量和choice做匹配,计算出一个分数,代表预测这个选项为正确答案的概率,然后重复其他三个选项,计算出四个分数。Choice和question应该是同等重要程度,仅仅让question和question做匹配没有意义。本文采用co-matching的方法,将question和choice看出两个句子,让passage既和question做匹配也和choice做匹配,这样passage中的每个单词同时关注到question和choice。
Model
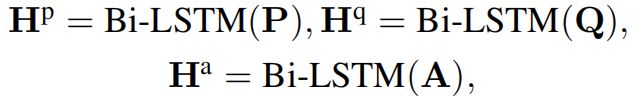
其中Hp,Hq,Ha是经过双向LSTM后的上下文向量,分别代表passage、question、choice。

Gq表示passage中每个单词对question中每个单词的注意力,Ga表示passage中每个单词对choice中每个单词的注意力,分别对问题和选项进行加权求和。得到![]() 和
和![]()

分别对![]() 和Hp做element_wise减法和element_wise乘法,然后向量拼接,通过一个relu激活函数得到Mq。
和Hp做element_wise减法和element_wise乘法,然后向量拼接,通过一个relu激活函数得到Mq。![]() 是passage中每个单词新得到的特征,这个特征是注意到question得到的,编码question方面的信息,而Hp是passage中每个单词的上下文表示,编码的是passage的信息,那么这种减法和乘法将这两方面的信息进行比较,更好的构造出交互的特征。将Mq和Ma两个向量拼接得到C。同理passage和choice之间的交互如此。
是passage中每个单词新得到的特征,这个特征是注意到question得到的,编码question方面的信息,而Hp是passage中每个单词的上下文表示,编码的是passage的信息,那么这种减法和乘法将这两方面的信息进行比较,更好的构造出交互的特征。将Mq和Ma两个向量拼接得到C。同理passage和choice之间的交互如此。

每个Ci的shape是不一样的,因为每个句子长度不一样。
![]()
对于每个Ci通过BiLSTM,BiLSTM的输出shape=(batch_size,sentence_i_length,dim),然后在句子长度这一维度做最大池化,得到固定长度(batch_size,dim)
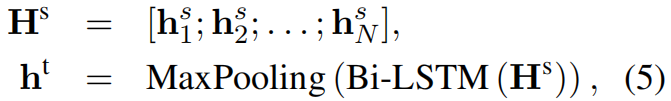
将上面的每个向量连接,得到Hs,将每个his通过BiLSTM后再做maxpooling得到的ht就是document即文章层面的语义。
Baselines
用RACE的数据集对本文的模型进行测试,RACE-M的数据集是来自初中考试,RACE-high的数据集是来自高中考试。将本文的model与以下的baselines进行对比,Sliding window,Standford attentive Reader,GA,ElimiNet,HAF,MUSIC。得出model的结果是art-
Conclusions
本文采用co-matching的方法解决多项阅读理解的问题,将question和choice看作是两个句子,让passage既和question做匹配也和choice做匹配,因此叫做co-matching,这样之后passage中的每个单词同时关注question和choice。在未来,将把协同匹配和层次聚合的思想应用到标准的开放域问答集中,用于候选答案重新排序。还将进一步研究如何在race数据集上显示的建模推理。















 2607
2607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









