






 TransPIM是一种针对Transformer模型的内存加速方案,通过软件和硬件协同设计提高性能和效率。它使用基于令牌的数据流减少数据移动,同时在HBM架构中加入轻量级硬件组件,如辅助计算单元(ACU),以加速计算密集型操作。实验表明,TransPIM在多种Transformer模型上比GPU快22.1到114.9倍,比ASIC加速器提供更高的吞吐量,且比仅PIM或NMC架构更高效。此外,TransPIM通过减少数据移动和优化数据通信架构,显著提高了内存带宽利用率和能效。
TransPIM是一种针对Transformer模型的内存加速方案,通过软件和硬件协同设计提高性能和效率。它使用基于令牌的数据流减少数据移动,同时在HBM架构中加入轻量级硬件组件,如辅助计算单元(ACU),以加速计算密集型操作。实验表明,TransPIM在多种Transformer模型上比GPU快22.1到114.9倍,比ASIC加速器提供更高的吞吐量,且比仅PIM或NMC架构更高效。此外,TransPIM通过减少数据移动和优化数据通信架构,显著提高了内存带宽利用率和能效。
(课程作业,故机翻上传方便自己查看)
摘要: 基于Transformer的模型在许多机器学习任务中都是最先进的。由于大的内存占用和低数据重用率,执行Transformer通常需要较长的执行时间,这会给内存系统带来压力,同时低效地利用计算资源。处理器内存(PIM)和近内存计算(NMC)等内存处理技术有望加速Transformer,因为它们提供高内存带宽利用率和广泛的计算并行性。然而,以前的基于内存的机器学习加速器主要针对计算密集型的机器学习模型(例如CNN),这些模型并不适合Transformer的内存密集特征。在这项工作中,我们提出了TransPIM,一种使用软件和硬件协同设计的基于内存的Transformer加速方案。在软件层面上,TransPIM采用基于令牌的数据流来避免先前基于层的数据流引入的昂贵的层间数据移动。在硬件层面上,TransPIM引入了对传统高带宽内存(HBM)架构的轻量级修改,以支持PIMNMC混合处理和高效的数据通信,以加速基于Transformer的模型。我们的实验表明,TransPIM比现有的基于内存的加速技术快3.7倍到9.1倍。与传统的加速器相比,TransPIM比GPU快22.1倍到114.9倍,并提供了比现有ASIC加速器更高的吞吐量。
Keywords-Processing in-memory; Near-data processing; Transformer; Domain-specific acceleration; Software-hardware co-design.
一、介绍
注意力机制已经成为序列数据建模中处理长期依赖的强大工具。基于注意力的模型,例如Transformer及其增强变种,已经显著提高了重要机器学习任务的准确性,如自然语言处理、计算机视觉和视频分析。但是,由于大内存占用和计算与内存比率低,这些优点付出了长时间的执行代价。现有的面向卷积计算的加速器是为计算密集型操作(例如卷积)而设计的,使它们在处理Transformer方面不够优化。为了加速Transformer模型,已经有一些专门领域的加速器,例如SpAtten和A3,它们将自注意力操作或整个Transformer从传统系统(例如GPU)卸载出来。然而,这些ASIC-based加速器仍然受制于有限的并行性和有限的离线存储器带宽,这束缚了加速器的性能。
基于内存的加速,包括内存中处理(PIM)和近存储计算(NMC),很有前途地加速Transformer模型,因为它支持广泛的并行性、低数据移动成本和可扩展的内存带宽。虽然有许多基于内存的神经网络加速器,但它们的数据流和硬件主要针对计算密集型CNN进行了优化,这可能与内存密集型Transformer不兼容。具体而言,现有的基于内存的加速器的数据流是以层级粒度确定的,要么利用整个内存一次处理一层,要么将互斥的内存资源分配给不同的层。这样的层级数据流在Transformer中引入了大量的非计算开销,因为需要加载或传输大量的输入数据和权重。在硬件方面,Transformer的复杂操作(如降维和Softmax)需要并行计算和细粒度的内存内数据重组,这将成为基于内存的加速器的性能瓶颈。我们的实验(第II-C部分)表明,在使用内存位串行加速器加速广泛使用的Transformer时,基于层级的数据流花费了超过60%的执行时间用于数据移动。此外,使用位串行行并行PIM操作进行降维需要花费约30%的执行时间,显示出比其他PIM算术操作低得多的计算吞吐量。结果表明,软件和硬件问题都可以显著限制基于内存的Transformer加速的效率。
在这项工作中,我们提出了TransPIM,一种基于新兴商品内存高带宽内存(HBM)的软件硬件协同设计,利用内存加速技术来加速Transformer模型。在软件方面,TransPIM采用基于标记的数据流,为不同层的计算分配内存资源,而不是为不同层分配内存。采用基于标记的数据流,每个内存银行处理和存储与特定标记集相关的中间结果。这样做可以显著减少跨层加载或传输的数据量,因为来自不同层的中间数据的增加局部性提高了数据重用率。 TransPIM只需要在计算跨内存(即不同标记集之间)信息时进行数据移动,可以通过利用HBM的大内部内存带宽高效处理。
尽管基于令牌的数据流显著改善了吞吐量,通过减少数据传输开销,但软件级别的解决方案无法解决Transformer中复杂操作的低效率问题。现有的基于内存的加速器支持PIM或NMC。然而,Transformer中的不同关键操作不共享类似的模式,不能通过单一类型的基于内存的技术有效地处理。此外,HBM中的原始数据路径严重依赖于共享总线。因此,用于传输数据的共享总线上的资源冲突可能成为需要高内部带宽的应用程序的瓶颈。为解决这些问题,我们提出了一套集成在HBM中的硬件,包括近存储辅助计算单元(ACU)和优化的数据通信架构。具体而言,ACU使内存能够利用PIM和NMC的优点,以有效加速不同的操作。优化的数据通信架构在HBM层次结构中添加缓冲区和专用链接,以卸载大量数据移动,实现比原始HBM更高的内存带宽利用率。
总之,这项工作的贡献包括:
(1)与专门用于注意力机制的现有加速器相比,TransPIM是第一个通过利用新兴的基于内存的加速技术来加速整个Transformer推理过程的端到端内存加速器。
(2)所提出的软硬件共同设计显著优于现有平台,包括GPU、TPU和基于ASIC的加速器。具体而言,TransPIM在多种广泛使用的Transformer模型上比GPU快22.1倍到114.9倍。相对于基于ASIC的加速器,TransPIM提供了2.0倍的吞吐量。
(3)我们提出了一个基于令牌的数据流,适用于通用的基于Transformer的模型,通过利用整体数据重用来减少不必要的数据加载。我们的结果表明,在各种基于内存的加速器架构上,所提出的数据流比之前的方法快4.6倍。
(4)TransPIM在传统的HBM架构中引入了轻量级的硬件组件,以支持Transformer的高效计算和内存操作,同时不影响内存密度。我们的实验结果表明,与仅支持PIM或NMC的架构相比,TransPIM的性能显著提高了3.7倍和9.1倍。
二、背景和动机
本节首先介绍了Transformer和PIM加速的背景。然后,本节分析了现有基于内存技术加速Transformer模型的问题,这激发了新的软硬件协同设计的需求。
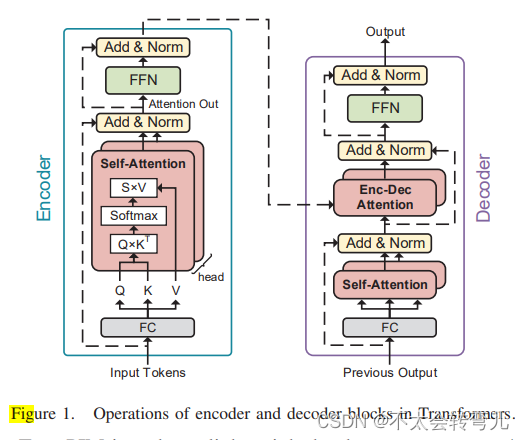
A、Transformer
Transformer是一种编码器-解码器架构,如图1所示。编码器和解码器均由相同的块堆叠而成。每个编码器块包含三个子层,包括一个全连接层(FC)、一个自注意层(SA)和一个前馈层(FFN)。对于一个具有L个标记的输入序列,FC层获取一个维度为L×de的嵌入矩阵,并通过将嵌入矩阵与不同的权重矩阵相乘来生成一个维度为L×dq的查询矩阵Q,一个维度为N×dk的键矩阵K,以及一个维度为L×dv的值矩阵V。为简单起见,我们使用D来表示dk,dq和dv。Q,K和V矩阵中的每个D维向量对应一个输入标记。编码器块然后将Q、K和V矩阵馈送到SA层。SA层中的关键操作是缩放点积注意力,它计算输入标记之间的依赖关系,如Softmax(QKT√D)V所示,其中Softmax(·)表示Softmax函数。QKT√D被定义为得分矩阵S。编码器块将注意力输出馈送到FFN层,以生成块输出,该输出可以用作下一个块(编码器或解码器)的输入,也可以用作特定任务的输出层(例如分类)。每个解码器块也有FC层、SA层和FFN层来处理前一层的输出。与编码器块不同,解码器块的输入和输出通常只包含一个或几个标记。此外,解码器插入另一个注意层,对前面的块进行注意力计算。Transformer执行许多内存密集型操作,这使得它适合于内存内和近内存的加速。
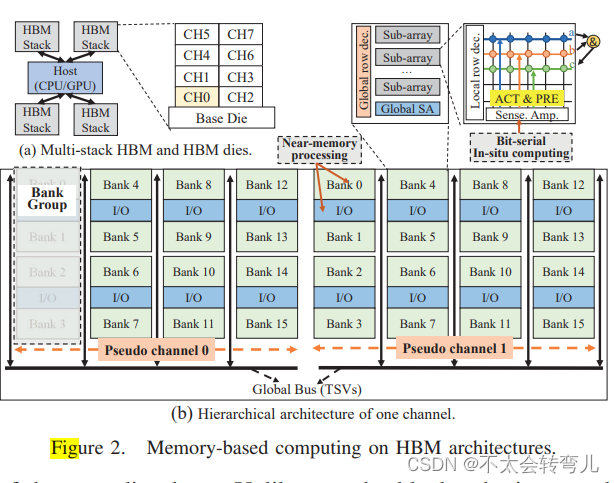
B、PIM Acceleration for Transformers
基于内存的计算因其广泛的并行性和最小化数据移动的能力而被广泛用于各种内存密集型和计算密集型应用中。本研究使用的基准内存架构是三星的高带宽内存(HBM),它已成为各种新兴平台的最先进内存解决方案。图2展示了4个HBM堆栈的总体架构。所有堆栈都连接到主机CPU/GPU,用于堆栈间通信。每个HBM堆栈是一个4层高的HBM芯片,具有多个DRAM片,位于基础芯片的顶部,通过许多通过硅穿孔(TSVs)连接,提供比传统DRAM更高的带宽和更低的访问延迟。
HBM中有两种处理数据的方式。第一种是近存储计算(NMC),其中计算逻辑被集成在近端的I/O或更激进的存储器芯片内的近端子阵电路中。例如,三星最近提出了一种新型的HBM,称为FIMDRAM,它在存储器芯片的I/O电路中集成了可编程计算单元(PCU)。这些非常规的PCU占用了一些存储器芯片的芯片面积,降低了存储器密度。第二种技术是内存中处理(PIM),它通过专门的激活和预充电命令或修改后的子阵结构支持在DRAM芯片(或子阵)中进行计算。PIM通常要求数据按列存储,并按位串行行并行方式处理计算。与NMC相比,PIM提供了更高级别的并行性,减少了数据移动,但只能支持有限的操作集,具有较高的延迟(因为是按位串行处理)。NMC支持更通用的操作,但吞吐量受NMC处理元素的数量以及数据链路的带宽限制。
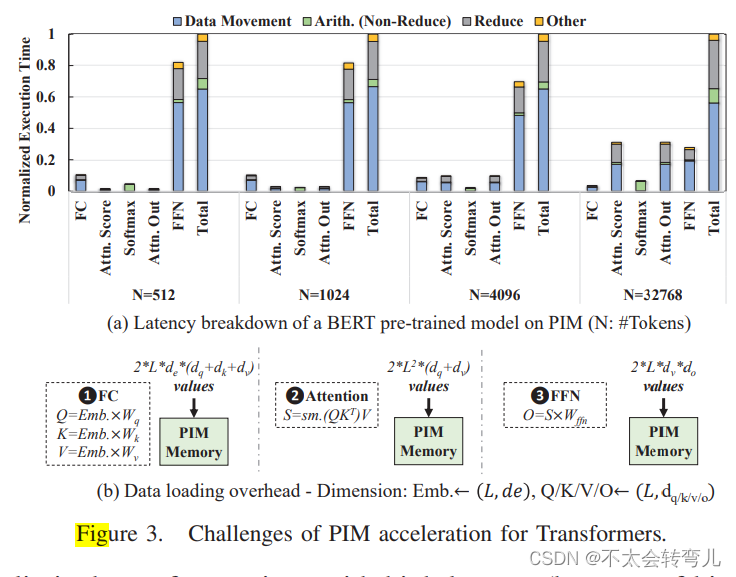
C、 Motivation of Software-hardware Co-Design
许多先前的研究表明,软件层面的调度(也称为数据流)和硬件设计在神经网络加速中都起着重要作用。为了最大化并行性,现有的基于内存的DNN加速器采用了一种层次数据流,它分配足够的内存资源以并行计算层中不同输出元素的结果。该层次数据流需要在处理每个层之前进行整个数据加载。我们对现有基于内存加速器在Transformer上的效率进行了调查。我们评估了使用RoBERTa Transformer模型进行文本分类任务的延迟分解,使用基于HBM的仅PIM系统,该系统具有88GB的HBM堆栈。PIM-only系统使用内存子阵列中的位串行行并行操作处理所有计算。图3(a)显示了分析结果。图3(b)显示了在使用基于层的数据流时每个层中加载数据的大小。
我们的实验表明,基于层的数据流动占据了大部分(约60%)的执行时间,即用于加载和重新组织数据的时间。长时间的数据移动是由两个方面造成的。首先,为了最大化并行性,基于层的数据流动需要在内存中进行数据复制以进行并行计算,从而增加了所加载数据的量。其次,大多数并行数据布局没有利用相邻层之间的数据重用。在这种情况下,我们需要为中间层(例如注意力层)加载所有数据。如图3(b)所示,对于注意力层,计算数据的大小随着序列长度的增加呈二次增长。因此,最小化加载数据的数量对于减少Transformer的总体执行时间至关重要。在本工作中,我们利用了不同Transformer层中所有操作都与输入序列中的标记相关联这一事实,从而可以通过在执行期间重复使用与标记相关的数据来改善数据局部性。
D、 Key Ideas of TransPIM
我们的研究表明,现有技术在Transformer上引入了很大的开销,需要在软件数据流和硬件支持上进行特定修改。因此,本工作提出了一种软硬件协同设计来加速Transformer。
数据流程: TransPIM采用高效的数据流程,利用基于令牌的分片机制将Transformer计算映射到基于内存的架构中。TransPIM将输入令牌分成不同的片段,并将这些片段分配给不同的内存分区。在加速过程中,每个内存分区独立地处理其相应的令牌片段,跨越不同的层。与基于层的数据流程相比,基于令牌的数据流程避免了重复数据的内存访问。我们还提出了一种高效的广播算法,通过利用HBM的大内部带宽加速相关数据的数据传输。
硬件加速: 在硬件方面,TransPIM对传统HBM架构进行轻量级修改,不仅加速各种Transformer操作,还有效地支持了提出的数据流。具体来说,TransPIM架构在每个存储器银行内实现了多个辅助计算单元(ACU),用于执行不能通过位串行行并行(PIM)操作高效处理的向量规约和Softmax函数。TransPIM利用PIM和NMC的优点实现高效率和吞吐量。此外,TransPIM通过专用数据缓冲区和通信链路增强了原始的HBM数据路径,以支持Transformer的各种数据操作和移动。
三、传输数据流
在本节中,我们介绍TransPIM数据流的详细过程。底层架构基于具备计算能力的HBM,如图2所示。
A、基于令牌的数据分片
TransPIM数据流的关键是基于输入token分配HBM bank的基于token的数据分片。基于token的数据分片提供的主要好处来自于通过保持相同内存位置的token计算来跨不同层进行数据重用。我们可以降低数据移动成本同时利用更多的内存级并行性,因为不同的bank可以独立处理分配的token的计算和数据移动。在token分片之后,每个bank在整个端到端的Transformer推断中处理其分片的计算。基于token的数据分片应用于第一个编码器块的全连接层之前的输入token。正如第二节中介绍的,输入token形成一个大小为L×D的矩阵,其中L是token的数量,D是嵌入向量的维度。输入token沿token维度均匀分割成“shards”,并分配到不同的内存bank中。在N个内存bank的情况下,每个bank分配L N个token。因此,每个bank接收一个大小为L N×D的输入矩阵。Figure4展示了将3个token分配到3个内存bank中的示例。
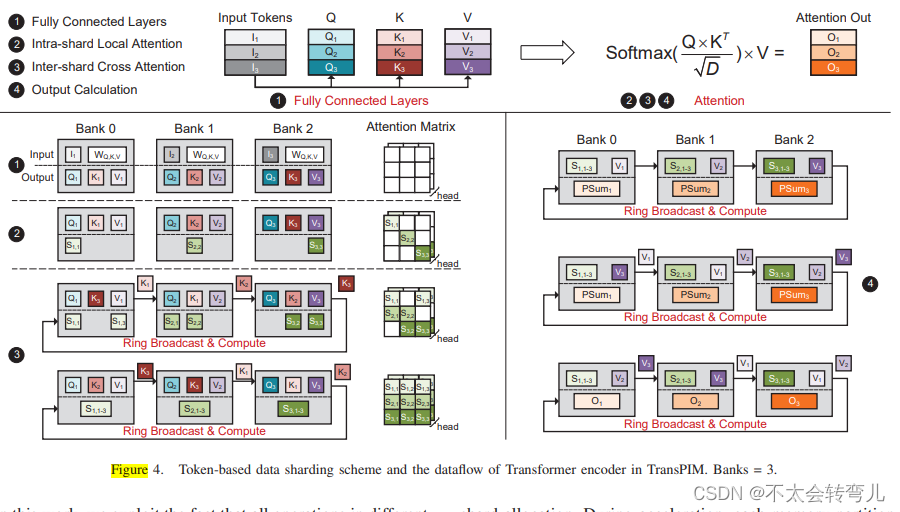
B、编码器块
在Transformer推理期间,每个内存分区执行其分配的令牌的FC(全连接层)、注意力和FFN层(Feed-Forward层)的计算。
(1)全连接层:全连接层从输入令牌生成查询(Q)、键(K)和值(V)矩阵。它涉及输入令牌和三个权重矩阵(WQ、WK和WV)之间的三个矩阵乘法。在TransPIM中,在FC计算之前,这三个FC权重矩阵的所有权重都被加载到每个内存bank中。然后,每个bank将分配的L/N×D子矩阵Ii与D×D权重矩阵相乘,如图4的1所示。然后,每个bank生成三个L/N×D子矩阵Qi、Ki和Vi。 Qi、Ki和Vi矩阵被保留在每个内存bank中,并用于接下来的attention层。
(2)注意力层:TransPIM中注意力层的计算包括三个步骤:(1)内部分片局部注意力,(2)跨片交叉注意力,以及(3)Softmax。
Intra-shard局部注意力: 在TransPIM中,Q和K矩阵是分布在内存银行中的。利用局部子矩阵,每个内存银行首先计算本地标记之间的注意力分数,如图4的2所示。每个内存银行使用来自FC层的本地Qi和Ki计算对角线上的局部L/N×L/N部分注意力分数矩阵。在intra-shard局部注意力期间,每个银行i可以独立地计算Si,i的部分注意力分数矩阵,而无需与其他银行通信。
跨片内部关注: 在计算完所有本地关注得分之后,TransPIM通过在不同的银行之间移动部分K矩阵来计算其他关注得分。如图4的3所示,跨片内部关注由多个环形广播和计算步骤组成。为了提高带宽利用率,我们提出了一个环形广播方案来在不同的银行之间传输Kj数据,其中每个Kj子矩阵通过一个抽象的银行环(例如,0→1→2…N→0)逐步发送到所有银行。在每个广播步骤中,每个银行将本地Qi与来自远程银行的接收Kj相乘,在块状关注矩阵的第i行和第j列生成一个L/N×L/N的局部关注得分。需要进行总共N个环形广播和计算步骤才能获取整个关注得分矩阵S。每个银行保留L N行关注得分矩阵Si,其形状为L/N×L。跨片内部关注的性能严重依赖于环形广播阶段的速度。在IV-B节中,我们提供了一种有效的硬件设计和调度方案,以充分利用HBM的内部存储带宽进行基于环形广播的数据传输。
Softmax层: Softmax层将与每个token相关的attention分数的指数归一化。每个bank使用其本地的L/N行注意力分数计算Softmax。由于注意力分数的数据局部性,不存在bank之间的数据移动。对于具有h个头的多头注意力,需要计算h个注意力矩阵的Softmax。因此,需要重复h次Softmax以获取所有结果。传统的Softmax需要复杂的指数函数、约简和除法。因此,在第IV-A2节中,我们设计了一种高效的方法来计算TransPIM硬件中的Softmax函数。
(3)自注意力输出和前馈网络: 自注意力的最后一步是将 Softmax 后的注意力分数矩阵 S 乘以 V 矩阵。基于基于令牌的数据分片,每个存储器银行存储部分注意力分数和部分 Vi 矩阵。自注意力输出的计算方式(图4中的步骤4)类似于跨 shard 的交叉注意力。部分 Vi 矩阵通过银行进行广播,每个存储器银行计算 L/N×D 部分注意力输出 Oi。前馈网络(FFN)由两个连续的 FC 层组成。在图4的最后一步中,注意力输出(FFN 的输入)与输入 FC 层(1)具有相同的令牌分片方式。因此,每个 FFN-FC 层的过程类似于输入 FC 层。
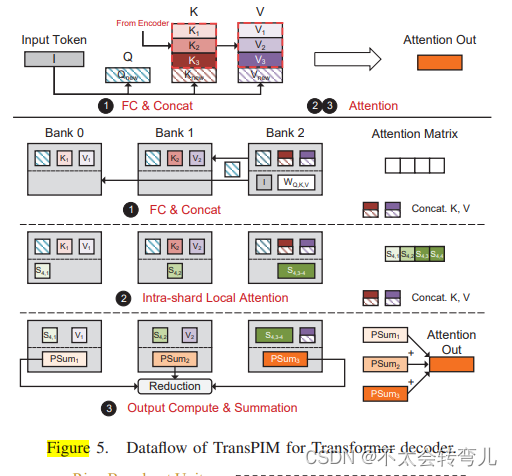
C、Decoder Blocks(解码器)
解码器块和编码器块之间的关键区别在于,每个解码器块只需要计算一个新令牌和新令牌与旧令牌之间的注意力操作。图5展示了解码器层的处理流程,与编码器块略有不同。在每个解码器块中,我们继续使用前一个块的数据分片,可以是上一个编码器或上一个解码器。我们将最后一个内存块分配给处理新的Q、K和V向量的FC层。在图5的1中,我们将Bank2分配给处理Qnew、Knew和Vnew。在FC层的末尾,TransPIM将生成的Qnew发送到所有其他内存块以计算注意力分数。此外,Knew和Vnew与上一个内存块的旧Ki和Vi连接。在图5的2中,每个内存块使用本地Qnew、Ki和Vi执行内部分片本地注意力。在2的末尾,每个块获得并保留新分数矩阵的L N列(对于最后一个块为L/N+1)。在输出计算和求和(3)中,每个内存块使用其本地Si和Vi向量计算新的注意力输出Onew的部分和PSumi。此方案需要进行一次规约操作以生成正确的输出。在第IV-B节中,我们介绍了如何在修改后的HBM架构中高效处理这种规约操作。解码器方案支持编码器-解码器和仅解码器的Transformer。这两种类型之间唯一的区别在于内存块是否预先存储了“上下文”向量,这些向量是来自编码器块的K和V向量。对于每个新令牌,我们分配具有最少令牌数量的内存块以平衡计算。

四、TRANSPIM 硬件加速
我们提出了一种基于内存的硬件加速方案,以解决加速Transformer模型所面临的挑战。图6显示了标准HBM2结构中的硬件定制,其中包括两个部分:1)内存中辅助计算单元(ACUs),2)数据通信架构,包括近存储器数据缓冲区和环形广播单元,这些单元被整合到原始的HBM数据路径中。
A、辅助计算单元
TransPIM增加了ACU以支持不适合进行内存位串行操作的操作。
(1)ACU设计:与之前的近存储器处理单元不同,对于传统的按行数据布局,所提出的ACU是针对按列位串行数据设计的,以支持内存操作。与以前的仅基于PIM的工作相比,其修改了单元数组结构并添加了额外的移位器,ACU则通过更轻量级的设计卸载了减少、Softmax和数据广播等操作。
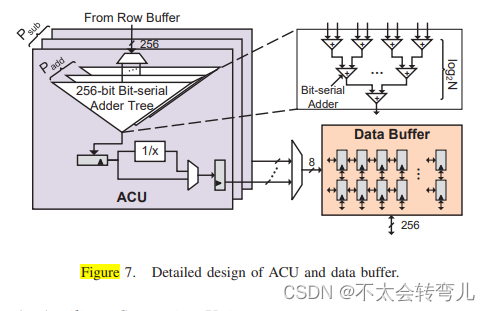
如图7所示,每个ACU都连接在子阵列后,以从行缓冲区接收256位数据,因为使用算术单元同时处理整个行缓冲区的数据(例如8Kb)成本过高。因此,从行缓冲区中为每个内存访问访问256个不同数字的相同位,以支持内存操作的位串数据布局。每个ACU中实现了总共Padd256位加法树,以充分利用内存银行的内部带宽并减少DRAM的行激活开销。每个加法树由面积效率高的255位串加器组成,以支持位串数据组织并减少开销。此外,位串加法树被分阶段管道化。实现了一个寄存器和一个除数来存储中间部分和并计算Softmax函数中的行累加的倒数。类似于encoder block中的Psub子阵列,每个内存bank中同时激活Psub个ACU以增加计算并行性。因此,为每个内存bank实现了Psub个ACU。
当点积向量乘积结果的向量长度小于加法树的宽度时,ACU减少可以使用单个位串加法树计算。对于b位数据,需要总共b个行访问来计算减少的结果。然而,减少的向量长度通常大于加法树的宽度。在这种情况下,ACU需要发出b×N/256行访问,其中N是向量长度(>256)。为了加速ACU减少和节省能量消耗,在每个ACU内并行实现Padd位串加法树。在预充电和激活新行之前,ACU在同一行内进行Padd次列访问,并连续将数据馈送到Padd加法树中。考虑到DRAM发出列访问命令的间隔tCCD远小于行访问tRC(即20倍),因此行激活时间和减少的延迟相对于只有一个加法树的情况下减少到约1/Padd。此外,所提出的设计通过寄存器能量交换过量的行激活能量。减少操作消耗的能量大大降低。
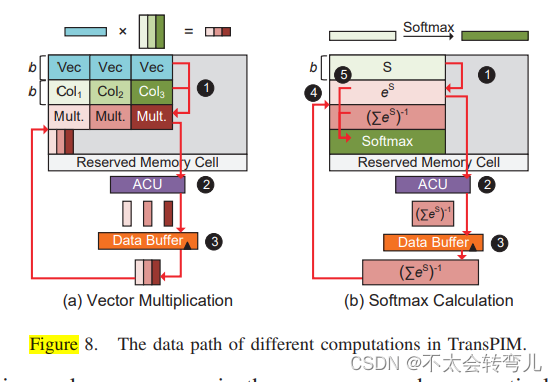
(2)TransPIM的计算:TransPIM采用混合内存和近存储计算范式,借助ACU和数据缓冲区支持Transformer的所有计算操作。具体而言,点积向量操作在存储单元中执行,因为DRAM原生支持此类操作,具有非常高的并行性。TransPIM将向量归约和部分Softmax函数从子阵列转移到ACU中,以提高效率。
向量计算: 图8(a)显示了TransPIM中向量乘法的数据路径。向量以位串格式组织,每个b位数据分配了b行相同的位线。对于向量乘法,它包括两个步骤:点乘和归约。TransPIM使用现有的方案在内存数组中计算点乘,采用布尔大多数函数来减少计算延迟。这些PIM操作利用DRAM时序违规,在标准DRAM架构中执行批量位运算。向量在b行中有三个副本以并行计算(1)。副本向量和矩阵的列之间的点乘同时计算。点乘后,需要进行向量归约以获得结果。连接到子阵列的ACU计算点乘结果的归约(2)。ACU从行缓冲区以位串格式连续接收数据,并将归约结果暂时存储在数据缓冲区中。最终的归约结果将作为3写回到内存单元中。
Softmax计算: PIM无法直接支持Softmax的复杂指数和除法运算。我们通过将行累积的倒数移到点积指数之外来解决这个限制,将Softmax重写为1∑N l=1e Si, j eSi, j。在这种情况下,Softmax变成了点积指数和相关行的倒数之间的乘法。首先需要计算注意力得分矩阵S的点积指数。然后最终的Softmax输出是指数和相关行的点积除法。如图8(b)所示,点积指数使用五阶泰勒级数展开进行近似,通过PIM乘法和加法进行计算。然后使用向量归约将行累积卸载到ACU中。同时,ACU中的除法器计算行归约的倒数(2)。一行的单个倒数值将被复制256次,并由数据缓冲器写回到内存单元组中(3和4)。最后,使用PIM操作在内存中计算倒数和指数的点积乘法(5)。
B、数据通信架构
TransPIM数据流利用内部内存带宽,以减少数据加载引起的数据移动开销。然而,标准HBM仍然不足以匹配高数据并行性和内部带宽要求。即使我们可以使用像RowClone这样的批量内存数据移动方法,内部带宽仍受共享数据总线的限制。此外,内存系统需要频繁进行内部银行和跨银行数据移动以进行基于内存的计算,其中数据复制和重新组织可能会显著降低性能。因此,我们提出了一种数据通信架构,以加速TransPIM中各种数据移动。
(1)定制化硬件组件:TransPIM引入了两个定制化的硬件组件用于在HBM架构中进行数据通信。
数据缓冲区: 对于大多数内部和跨越内存块的数据移动,我们可以使用RowClone的快速并行模式(FPM)来执行快速行复制。然而,这种方法有两个缺陷。首先,它无法为行提供细粒度的部分复制。其次,FPM要求源和目标行位于同一子阵列中。为了克服这两个限制,我们在每个内存块中实现了可重配置的数据缓冲区,以操作来自ACU或行缓冲区的数据,如图7所示,实现更灵活的数据移动。数据缓冲区是一个可配置的8×256b缓冲区,由8256位移位寄存器组成,支持数据复制和重新组织。数据缓冲区可以接收8位(来自ACU)或256位(来自感应放大器)的数据。
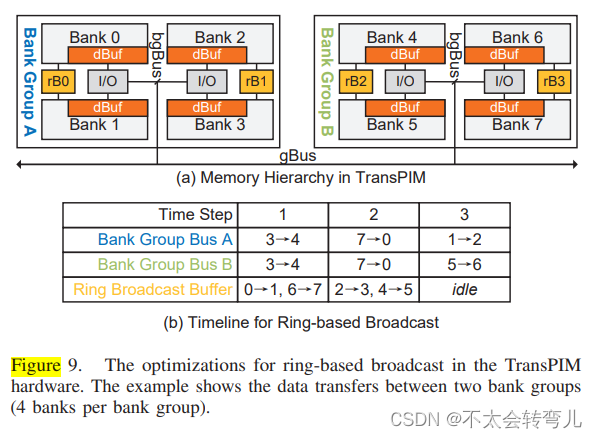
(图九:TransPIM硬件中的基于环形广播的优化。该示例展示了两个银行组之间(每个银行组有4个银行)的数据传输)
**Ring Broadcast Unit:(环形广播单元) ** 如第III节所述,TransPIM采用基于环的数据广播来减少处理注意力得分和自注意输出的数据加载开销。然而,原始的HBM不能有效支持这种基于环的数据广播,因为通道中的所有数据传输都需要使用共享的数据总线和控制器。TransPIM通过每个银行组的广播单元和两个相邻银行的广播单元之间的直接256位连接来有效地解耦不同银行组(甚至不同银行)之间的数据传输,如图9(a)所示。
(2)TransPIM 数据移动的优化:通过提出的通信架构,我们可以在运行 TransPIM 数据流时加速各种数据移动模式。
细粒度数据移动: 每个数据缓冲区配备了控制器,支持银行内的细粒度数据复制和复制。当需要进行细粒度部分复制时(例如图8(b)中的3和4),数据缓冲区通过8位输入从ACU读取数据并执行数据复制。复制的数据通过256位输出以位串方式写回到感应放大器中。数据缓冲区的另一个优点是它能够在不使用共享总线的情况下在不同子阵列之间移动数据。数据缓冲区支持并行访问,每个列访问周期读取256位数据从感应放大器中。它可以缓存最多2Kb数据,并将每个256位数据复制到位于不同子阵列中的感应放大器中。
Ring-based data broadcast:(基于环的数据广播): 图9展示了TransPIM体系结构中两个Bank组之间的基于环形数据广播(Section III-B2)的数据移动。正如在第III节中所示,环形广播的每个步骤都需要所有Bank将数据复制到环中的下一个Bank(例如,1→2→3…7→0在图中)。如果我们假设两个Bank之间的数据复制时间为T,则原始的HBM架构需要8T,因为每个数据复制都需要使用全局总线和控制器。对于TransPIM架构,这样的环形广播需要3T的时间,如图9所示。在第一步中,我们使用Bank组总线(BankGroup A和BankGroup B均可)执行Bank 3→4的传输。同时,我们还可以使用广播缓冲区之间的环形广播链接复制来自Bank 0→1和6→7的数据。在第二步中,我们使用Bank组总线将7→0传输,同时使用环形广播缓冲区将2→3和4→5传输。剩下的两个传输,1→2和5→6,可以在第三步并行处理。该算法可以在相同的时间复杂度下扩展到更多的Bank组,这比未经优化的架构的时间复杂度显着降低。
解码器块中的Token Reduction: 如第III-C节所介绍的那样,每个解码器块的输出Token需要对分布在不同bank中的所有部分和进行全局归约。TransPIM可以通过多步并行方式有效地减少所有部分和。具体而言,在每个归约步骤中,我们将带有部分和的bank分成多个双bank归约组,并通过将部分和从一个bank移动到另一个bank来减少每个归约组的部分和。所有的归约组都可以通过PIM操作并行地处理归约。TransPIM可以通过利用内部带宽(如ACU之间的链接、bank group总线和channel总线)有效地支持这种数据移动。
五、实验
在本节中,我们描述了评估所提出设计的好处的实验。

A、评价方法
TransPIM的硬件特性总结如表I所示。内存采用标准的HBM2。时序和能量参数是从先前发表的工作中提取的。TransPIM的硬件组件与原始HBM相同的面积和功率限制。使用22nm技术节点的分析工具CACTI-3DD估算了HBM的面积。我们假设最多可以将8个HBM堆栈通过硅中介层连接到主机CPU。主机-HBM带宽为256GB/s。
我们使用Verilog HDL实现了TransPIM,并使用65nm库在Synopsys Design Compiler上合成了设计。合成的设计使用Synopsys IC Compiler进行布局和布线。此外,应用时钟门控以节省能量消耗。在每个ACU中实现了Padd=4位串行加法器树。用于计算1/x的常数除法器是三级流水线以满足时序约束。为了匹配列访问时间tCCD=2ns的速率,ACU被配置为以500MHz的时钟频率运行。ACU的得到的面积和功耗数据被缩放到22nm以匹配内存技术。我们考虑了逻辑和DRAM之间的工艺差异,采用了先前工作中类似的方法,在DRAM工艺中增加了大约50%的额外面积开销。
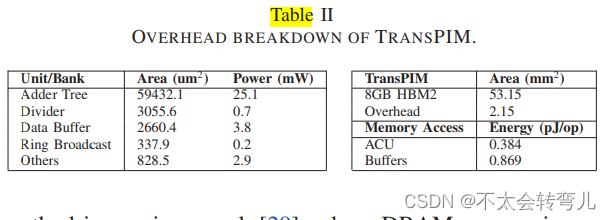
TransPIM的实现结果在表II中给出。4路并行的串行加法树占总面积的88%。TransPIM的每个存储器bank配备了Psub=16个ACUs。总计512个ACUs消耗了约2.15平方毫米的面积,相对于原始DRAM架构产生了4.0%的面积开销,远远低于25%的面积开销阈值,因此避免了DRAM密度损失。
(1)模拟:我们实现了一个内部模拟器,用于模拟TransPIM和所有PIM基准测试的详细性能和能量特性。模拟器的前端利用TensorFlow接口,提取模拟工作负载的形成。后端模拟器是Ramulator的修改版本。我们插入了额外的命令到TransPIM的模拟器中,以模拟给定DRAM配置的工作负载运行时行为。HBM的架构配置以及时序/能量参数如表I所示。
(2)硬件基准线:GPU和TPU:GPU平台为Nvidia RTX2080Ti。我们使用nvidia-smi测量GPU功耗。我们还将谷歌云TPUv3的一个8核作为基准线。我们使用JIT编译的TensorFlow模型,并从第二次迭代开始计算平均延迟以排除图形编译开销。
近存储处理(Near-bank processing,NBP): Newton是使用近存储器处理技术的基准,它是一种类似于HBM2E的DRAM,将大多数机器学习模型操作卸载到近存储器逻辑中。由于NBP基线已经修改了银行级逻辑,因此我们在NBP基线中启用广播缓冲区,用于公平比较。我们假设NBP基线使用与TransPIM相同的HBM架构。
原始的PIM: 原始的PIM架构是基本的HBM架构,仅支持使用专门的内存控制器进行内存中的位串操作,并根据先前的工作对子阵列进行修改。我们还假设PIM基线与TransPIM使用相同的HBM架构。
(3)工作负载:在这项工作中,我们评估了两种广泛使用的Transformer模型RoBERTa和Pegasus,用于各种重要的NLP任务,包括文本分类(IMDB)、摘要(Pubmed和Arxiv)和问答(TraviaQA)。分类和问答任务只有编码器块,而摘要任务有编码器和解码器块。我们还使用GPT-2-medium模型评估了一个仅解码器任务,语言建模(LM)。所有工作负载均使用TensorFlow 2和XLA实现。
B、TransPIM性能表现:
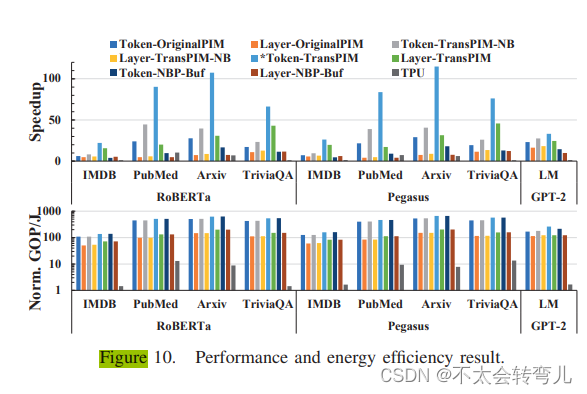
我们通过将TransPIM与GPU和具有基于层或基于令牌数据流的各种基于内存的体系结构进行比较,来评估TransPIM的效率。我们将每个系统表示为“dataflow-architecture”(例如,Token-TransPIM)。为了进行敏感性分析,我们测试了TransPIM的另一种体系结构配置,禁用了广播单元和数据缓冲区以进行通信,表示为“NB”,而“Buf”表示具有广播单元和数据缓冲区的体系结构。图10显示了所有体系结构的性能和能量效率与GPU基线的比较。所有基于内存的系统都使用8个HBM堆栈,总容量为64GB。性能以每批次的执行时间为度量,因为具有短令牌长度的工作负载(例如IMDB和TriviaQA)可能仅使用单个批次的内存不充分。 GPU系统使用每个工作负载支持的最大批处理大小运行。能量效率以不同系统的GOP/J为度量。所有值都归一化为GPU基线。所有基线都以FC和FFN层的8位精度运行,这对于Transformer模型来说已足够。我们在Softmax中使用16位以支持指数的范围。
与GPU/TPU的比较: 所提出的系统(Token-TransPIM)比GPU(TPU)快22.1×(8.7×)至114.9×(57.4×)。在IMDB上,TransPIM的性能提升不太明显,因为标记数太少,PIM系统无法充分利用并行性,因为标记基于PIM操作需要每个银行至少处理一个。对于更多标记的工作负载,基于标记的调度可以饱和PIM系统的计算能力,充分利用PIM操作的并行性。至于能源效率,TransPIM比GPU(TPU)更加能源效率,分别为138.1×(39.5×)至666.6×(376.7×)。与性能结果类似,当运行长标记序列的工作负载时,TransPIM实现了更好的效率。能源效率的提高来自快速执行和减少数据移动。
与之前基于内存的加速对比: 与先前的仅基于PIM的加速(layer allocation)相比,采用token分片的TransPIM速度提高了9.6倍。如果PIM-only加速也使用token分片处理,TransPIM仍然比它快3.7倍。此外,TransPIM分别比基于层级数据流和token分片的PIM-only加速更具能效性,提高了4.2倍和1.3倍。这些结果表明,TransPIM通过软件和硬件的定制改进了先前的PIM加速的性能和能效。
与NBP体系结构相比,使用基于令牌的数据流和基于层的数据流时,TransPIM分别快了9.1倍和6.4倍。但是,TransPIM在与具有相同数据流的NBP基线相比时并不更加能效(约少了0.2%)。这是由于比特串行原地操作消耗大量能量,需要所有内存子阵列进行大量并行行激活和预充电操作。
与ASIC的比较: 之前的ASIC设计A3和SpAtten采用剪枝技术来减少计算复杂度,主要集中在加速自注意力层方面。TransPIM针对Transformer模型的端到端执行目标是减少数据移动开销和提高计算效率。由于以前的ASIC对存储器面积没有特别的关注,我们假设所有系统都使用8GB HBM作为存储器。每个8GB HBM芯片的TransPIM的额外面积为2.15mm2,接近A3(2.08mm2)和SpAtten1/8(1.55mm2)。SpAtten报告在GPT-2模型的生成阶段(解码器)中与GPU相比的35倍端到端性能提升。相比之下,TransPIM在两个类似的工作负载(Pubmed和Arxiv与Pegasus)上实现了83.9×和114.9×的加速。此外,TransPIM的平均吞吐量为734GOP/s,约为A3(221GOP/s)和SpAtten(360GOP/s)峰值吞吐量的2.0-3.3倍。这种增益来自于三个方面。基于令牌的数据分片避免了冗余的数据移动,从而提高了计算效率。此外,内存中和接近内存的高数据并行计算提供了更高的峰值性能。TransPIM的优化数据路径利用了HBM的大内部带宽来减少数据移动开销。相比之下,ASIC的性能受限于有限的计算资源和芯片外存储器带宽。
解码器模型: 对于仅解码器工作负载(GPT2-LM),TransPIM比第二好的系统(Layer-TransPIM)快1.4倍,能效高2.1倍。TransPIM相对于其他系统的速度提升和能效改善都比其他工作负载小。这是因为解码器模型每次迭代只处理1个标记,因此需要加载的内存计算数据比编码器模型少得多。
C. 详细的性能分析:
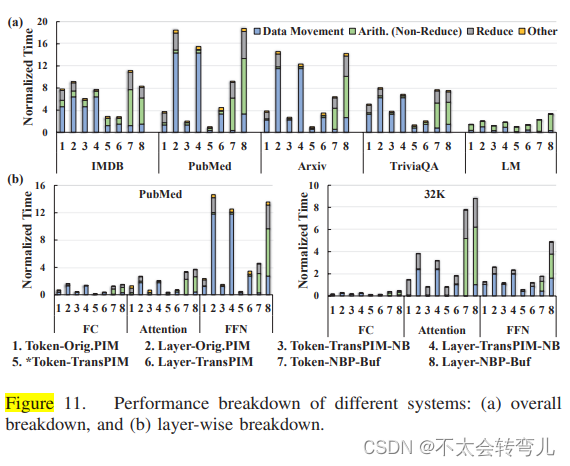
我们还调查了所有基于内存的系统操作的详细分类,如图11所示。该图显示了四个重要操作类别的细分,包括数据移动(加载和内存内复制)、非降维算术、降维和其他操作,包括读和写。
对以前加速的改进: 与PIM-only系统相比,TransPIM通过高效的数据路径显著减少了数据移动开销(基于层和基于token-sharding数据流的改进分别为18.2×和4.1×)。此外,TransPIM的定制ACU有效地加速了昂贵的缩减操作,其中TransPIM在缩减方面花费的时间比PIM和NBP-only系统分别少了35.3×和56.1×。与NBP基线相比,缩减操作的性能改进更大,因为NBP基线的并行度要低得多。NBP基线的有限并行度显著增加了其他算术操作的延迟,而PIM实现要快13.2×。
token-sharding的影响: 本文中的详细分析还揭示了token-sharding的性能优势。对于所有系统而言,采用token-sharding可以将数据移动延迟降低4.8倍、4.5倍和4.5倍。这种改进取决于工作负载,我们观察到在IMDB、PubMed、Arxiv和TriviaQA中分别提高了1.3倍、10.1倍、5.0倍和1.9倍。这些结果表明,在较大的工作负载(较长的序列)中,token-sharding的效果更好,因为对于注意力层,分配方案的数据加载时间随序列长度的增加呈二次方增长。而对于token-sharding,传输数据的大小仅线性增长。
数据移动优化的影响: 尽管令牌分片数据流可以显著降低数据移动开销,但TransPIM可以通过广播和复制缓冲区的定制数据路径进一步降低它。与没有缓冲区的TransPIM相比,这种定制的数据路径可以使数据移动减少4.1倍。
Layer-wise breakdown:(逐层细分):: 图11(b)展示了使用Peagasus进行PubMed(4K)和具有32K序列长度的合成数据的摘要的分层分解结果。所有结果都标准化为所提出的Token-TransPIM系统的总时间。基于令牌的数据分片减少了FC和FFN层中数据移动的开销,因为它需要比分配数据流更少的数据复制用于计算(但并行性较少)。在注意层中,TransPIM由于使用基于环的广播的高带宽利用率以及使用令牌分片减少了数据移动而显着降低了数据移动开销。
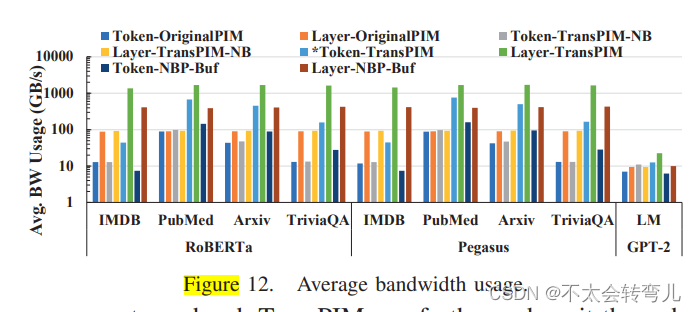
资源利用率: 我们使用计算所占时间百分比来衡量存储器银行的利用率。如图11所示,Token-TransPIM的平均利用率为45.8%,比Layer-TransPIM(30.8%)高1.5倍,因为基于令牌的数据流显著减少了数据移动的开销。然而,Token-OriginalPIM和Token-NBP提供了更高的计算利用率,分别为47.7%和89.5%。这是由于PIM-only和NBP-only解决方案中计算非常缓慢。图12显示了平均带宽利用率,即读写数据大小除以延迟时间。使用基于层的数据流的系统消耗的带宽比使用基于令牌的数据流的系统更多。例如,Layer-TransPIM的平均带宽使用率高达1699GB/s,而Token-TransPIM只有高达762GB/s。考虑到总延迟时间,结果表明,基于层的数据流需要比基于令牌的数据流更多的数据移动。即使我们的8层HBM系统提供了足够的带宽(BWaggregated=8×256=2T B/s),当增加工作负载大小或减小系统带宽时,基于层的数据流可能会变成带宽受限的。在硬件方面,TransPIM中数据缓冲区和环形广播的使用增加了特定数据流的带宽使用率,因为延迟较低,这表明TransPIM的缓冲区架构始终是有效的。
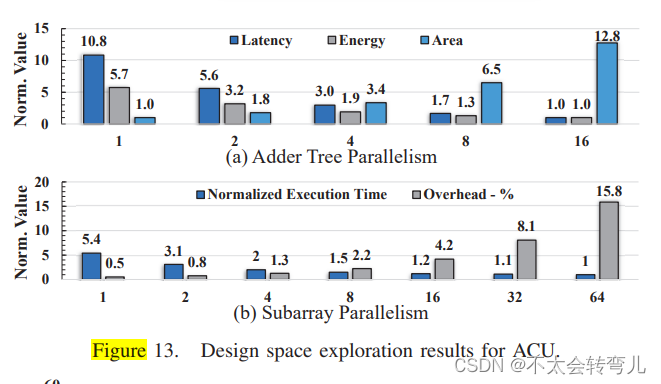
D、硬件定制探索
比特串加法树的并行性和数据缓冲区大小是ACU的两个设计参数。我们需要探索不同的参数以找到最佳的权衡成本和性能的方案。我们通过在BERT模型中改变加法树的并行性Padd从1到16来进行设计空间探索。结果如图13所示。增加加法树的并行性增加了每行激活的列数,从而减少了向量缩减过程中重复激活的行数。因此,向量缩减的延迟和能耗最多减少了10.8倍和5.7倍。此外,ACU通过寄存器访问能量将大部分DRAM访问能量降低,如图13(a)所示。最后,我们选择Padd = 4作为ACU中加法树的最佳并行性,因为它在附加ACU区域和性能之间保持了良好的平衡。
我们可以通过同时激活一个存储器 bank 中的 Psub 个子阵列来实现更高的并行性,其中每个子阵列包含一个独立的 ACU。然而,在一个 bank 中添加更多的 ACU 会增加面积开销。图13(b)展示了在不同的 ACU 数量下添加 ACU 的执行时间和面积开销。每个子阵列添加一个 ACU(parallelism=Psub=64)仅会将性能提高5.4×,而引入15.8%的面积开销。我们选择Psub=8,以更好地平衡开销和性能。
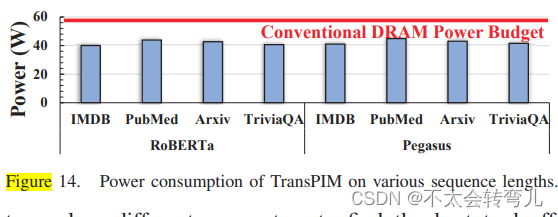
E、Power analysis 功率分析
本文中给出了测试工作负载下TransPIM的功耗估计,如图14所示。在相同的序列长度下,Pegasus模型在TransPIM上的功耗约高出RoBERTa模型的2%。随着输入序列从128(IMDB)增加到4096(PubMed),这两个模型的功耗增加了约4W,这是由更多的计算引起的。总的来说,TransPIM的功耗仍然低于传统DRAM系统的60W功耗预算。因此,TransPIM满足传统的热管理限制,可以在现有商用DRAM系统中集成,无需进行额外的功率和冷却方面的修改。
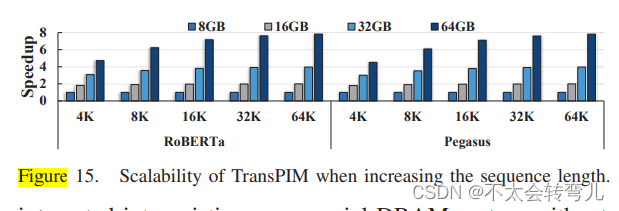
F、可扩展性
在先前的研究中已经表明,对于更长的序列,Transformer会变得更具挑战性。基于内存的加速可以通过同时增加内存带宽(具有低内存访问延迟)和计算并行性来提供可扩展性。图15展示了在处理不同序列长度的工作负载时,使用更多的HBM堆栈时的加速比。速度提升是对所有工作负载进行平均的结果。结果表明,TransPIM为长序列工作负载提供了良好的可扩展性(几乎是线性的)。由于GPU解决方案由于内存容量有限而受到序列长度的限制,因此我们的实验表明,TransPIM是扩展Transformer模型用于长序列应用的有希望的解决方案。
六、相关工作
Transformer 加速器: 提出了一种名为 TurboTransformer 的基于 GPU 的服务系统和运行时,通过最大化计算和内存资源的利用来处理长序列。但是 TurboTransformer 的可扩展性较差,因为它无法支持多个 GPU。相比之下,TransPIM 可以通过堆叠多个 HBM 芯片来轻松扩展,从而获得更大的内存空间并支持更长的序列长度。SpAttn、A3 和 GOBO 是专用于加速注意力模块的最先进的 ASIC 处理器。A3 和 SpAttn 都实现了排序单元以修剪冗余头部并缩小内存占用,从而适应有限的芯片缓冲区大小。SpAttn 和 GOBO 提出了低精度量化和流水线架构以提高效率。此外,在其中使用了近似 Softmax 计算。但是 GOBO 和 A3 无法本地支持整个 Transformer 的端到端加速。此外,它们需要在计算之前从离芯片存储器中加载数据。离芯片存储器带宽将成为 Transformer 的内存密集层的瓶颈。相反,TransPIM 通过将所有数据保存在内存中避免了昂贵的离芯片数据传输。
PIM加速器: 为了减少大量数据传输的开销并支持高并行数据,已经提出了各种PIM加速器。Newton、FIMDRAM和McDRAM采用相似的近存储体系结构和水平数据组织方式。它们将位并行算术单元级联到DRAM存储器中,以执行矩阵向量乘法。然而,复杂的位并行和笨重的缓冲器会产生大量的开销并降低内存密度。为了减少附近存储器中算术单元的开销,BFree在存储器单元中存储了与计算兼容的查找表。然而,查找表需要细粒度优化来节省所消耗的空间。以前的内存加速器也优化了复杂的约减。Drisa在子阵列中添加了额外的移位器,而NeuralCache则依靠缓存I/O外设来对数据进行多级层次约减。这两种方法要么显著增加面积开销,要么引入大的I/O延迟。FloatPIM通过以比特串方式组织约减数据来支持约减,以避免额外的数据移动。但是,这种方案牺牲了Transformer中通常具有长向量约减的并行性。与以往的工作不同,TransPIM结合了内存和附近存储计算的优点。所提出的ACU是比特串的,以最小化外围电路的开销。与现有的PIM加速器相比,所提出的PIM-NMC组合计算范例提供了更好的效率,而不会影响内存密度。MAT是一个基于PIM的处理框架,用于处理长序列输入的基于注意力的机器学习模型。它将长序列输入分成不同大小的片段,并以管道方式处理这些片段。但是,MAT仅针对单个编码器块,与加速整个Transformer的TransPIM不同。
七、总结
本工作提出了一种基于新兴HBM架构的Transformer端到端加速方案TransPIM。TransPIM采用软硬件协同设计原则来加速各种Transformer模型。与以前的加速器相比,TransPIM通过利用与输入标记相关的计算中的数据局部性,显著降低了数据加载的开销。 TransPIM还在HBM中包含轻量级硬件修改,以提高计算和数据通信的硬件效率。通过在各种工作负载上的评估,TransPIM比各种平台(包括GPU、TPU、ASIC和最先进的基于内存的加速器)实现了显着更好的性能和能源效率。
致谢和引用省略…















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









