







1.前言
参与了一个AI的SoC项目,一般AI处理器相关的SoC对内存带宽需求很大,往往使用HBM而不是DDR。项目组里旁听了供应商关于HBM以及其HBMC产品的基础介绍,因为主要领域不在HBM,简单记录。
2.关于HBM
一些扫盲贴子:
https://zh.wikipedia.org/wiki/%E9%AB%98%E9%A0%BB%E5%AF%AC%E8%A8%98%E6%86%B6%E9%AB%94
相关协议: IEEE1500
3. 一些笔记
HBM IO 位宽1024bits,DDR4: IO width 16bits,使用64个DDR颗粒才达成1个HBM吞吐能力。
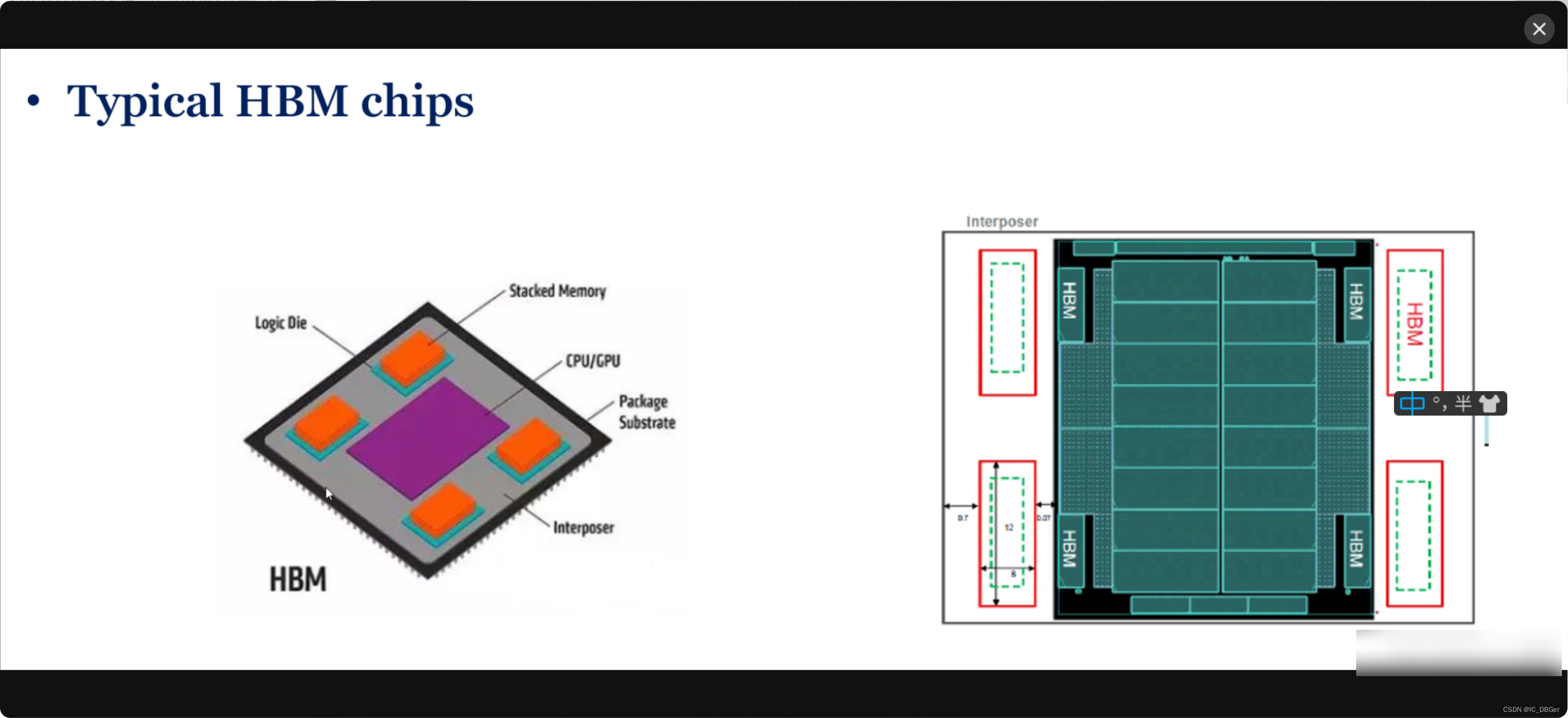
HBM 总线宽度有1024bit, 需要1024个PAD,PAD数量非常非常多,平面封装工艺Hold不住, 为了解决这个问题。使用2.5D堆叠封装的方式。
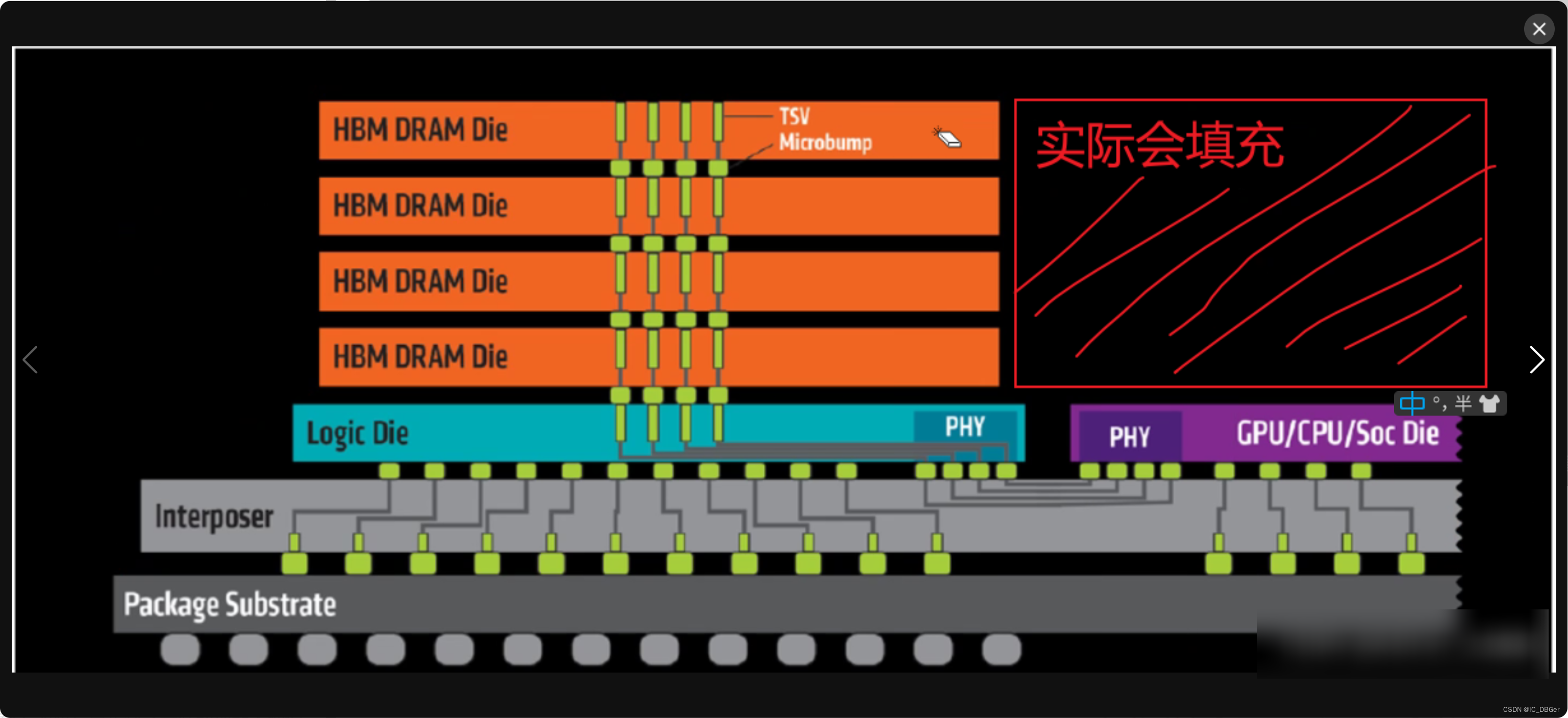
HBM training 过程没有内嵌的core, 使用纯逻辑的状态机实现。
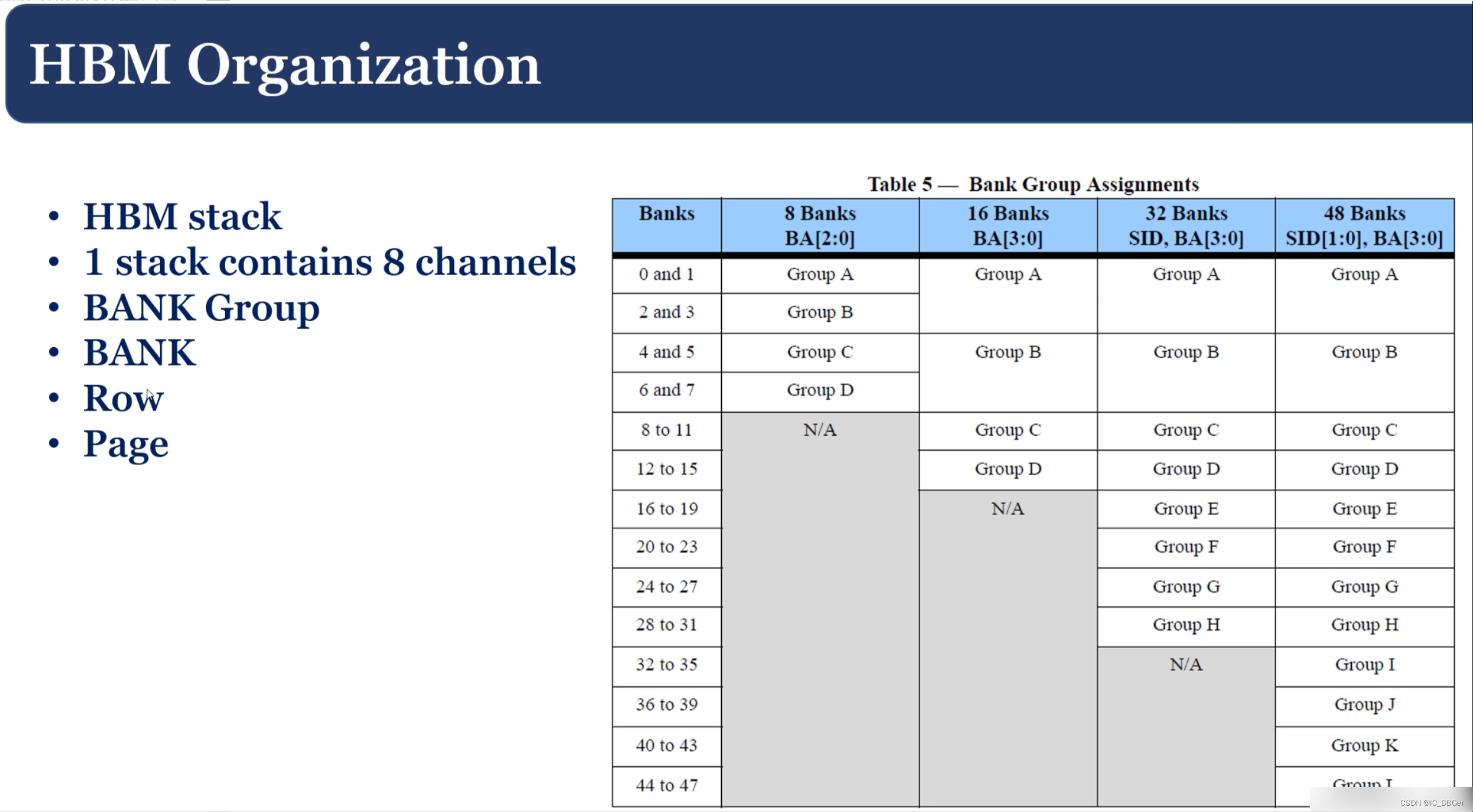
HBM的内部的组织方式,BANK和BANK之间,Bankgroup 和 bankgroup 之间是独立访问的。这为上层灵活控制提供了接口。
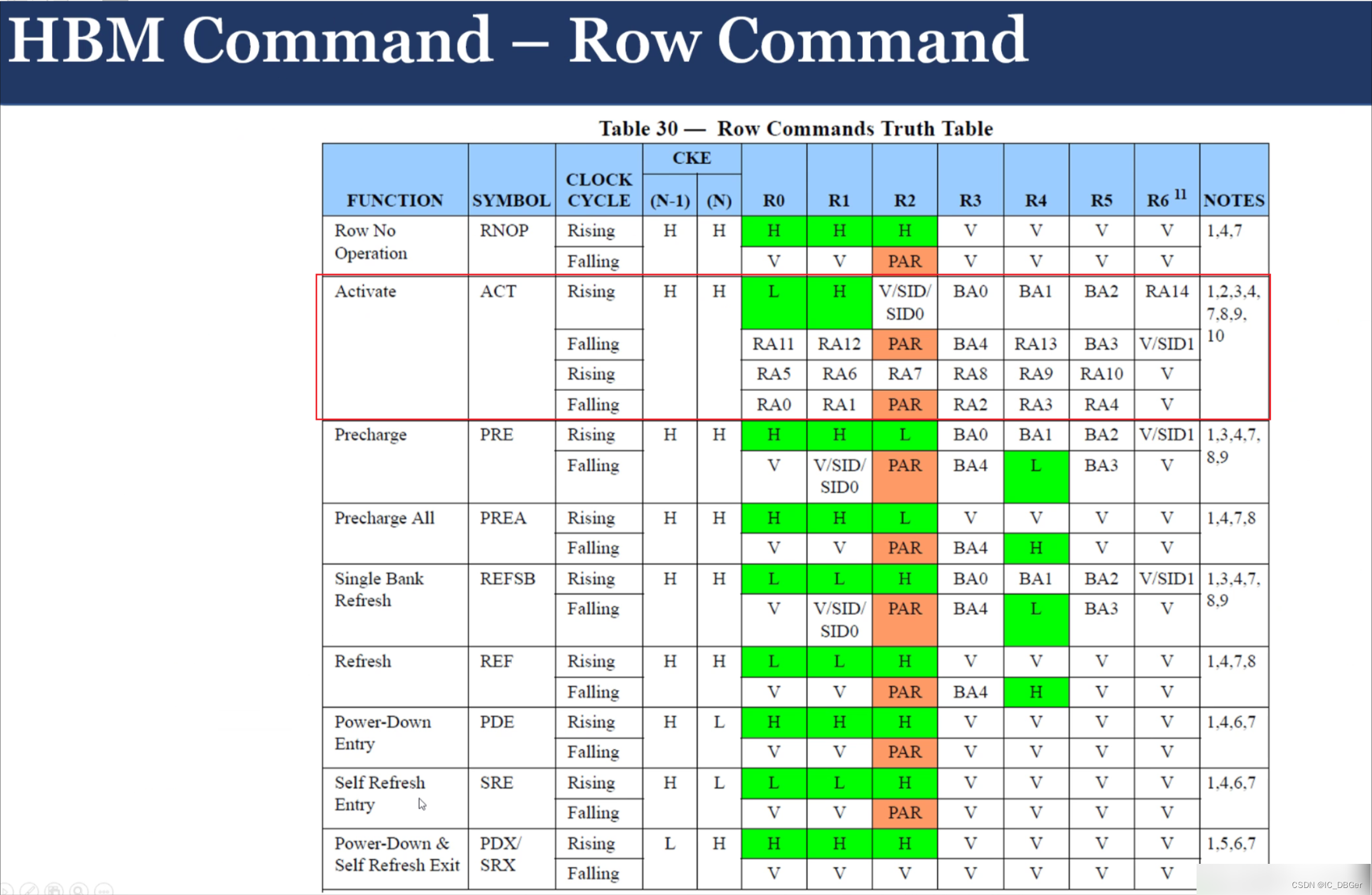
HBM ROW的指令操作(类似的还有colum的操作):
支持的Features:

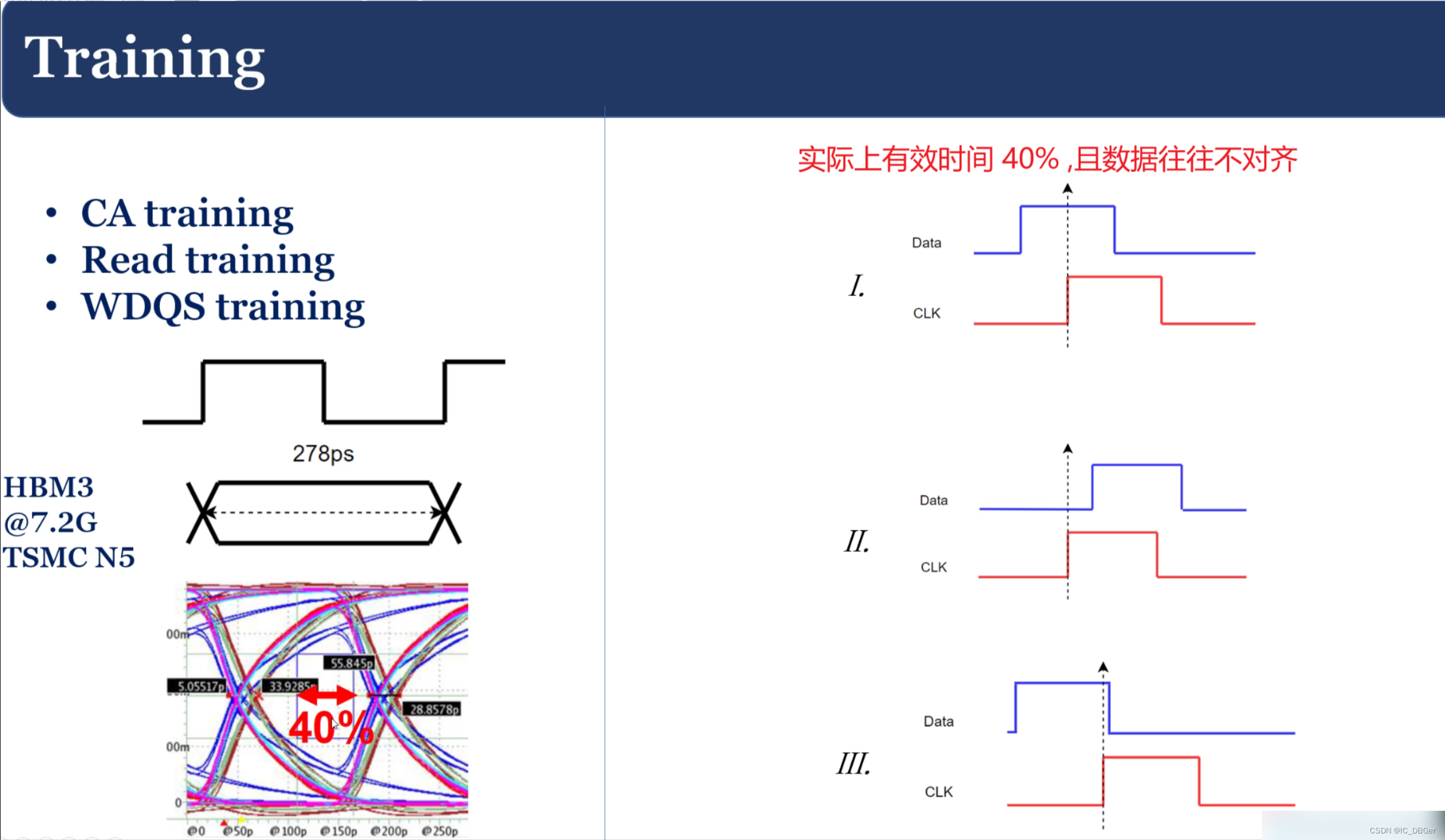
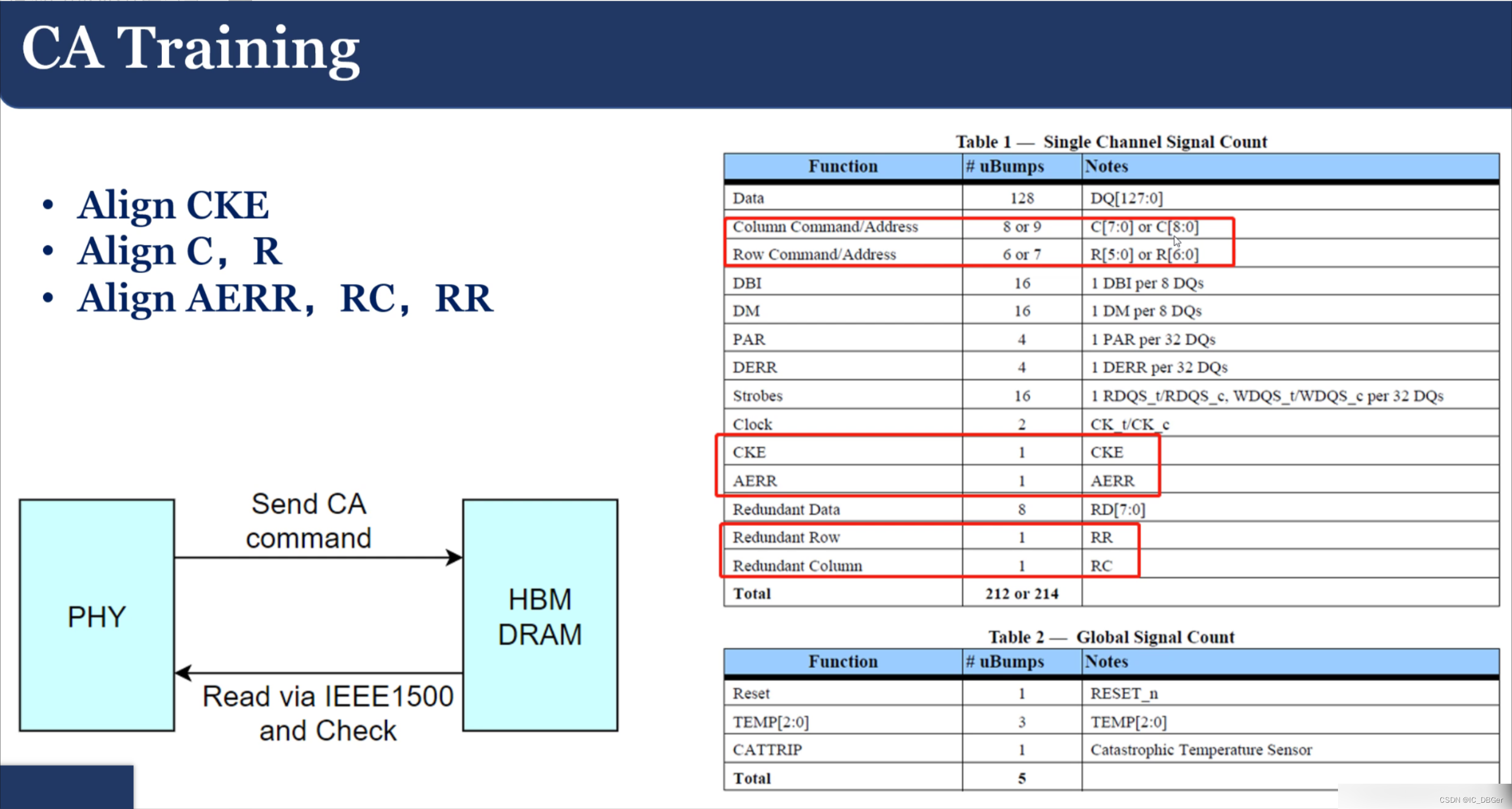
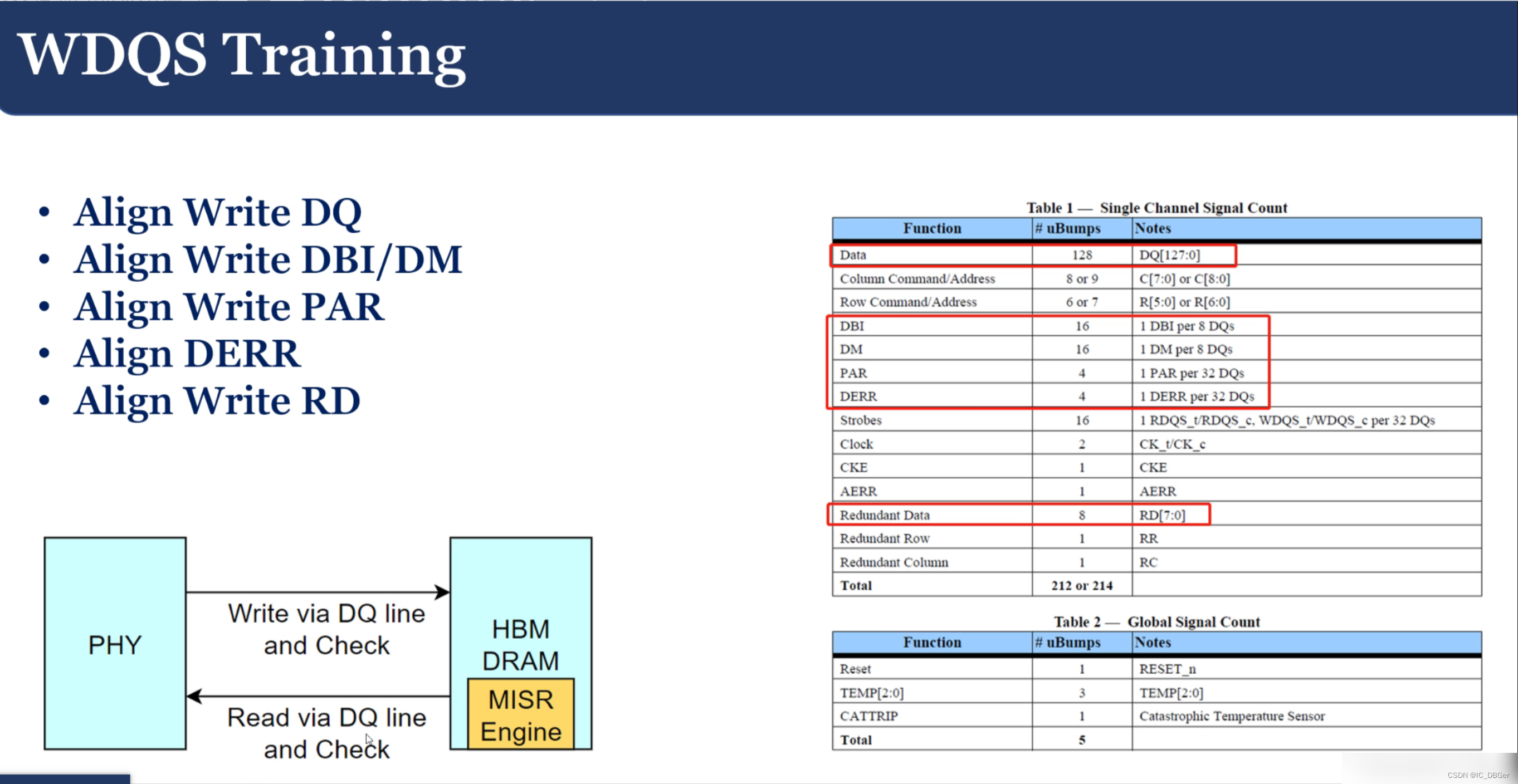
关于Training的过程:
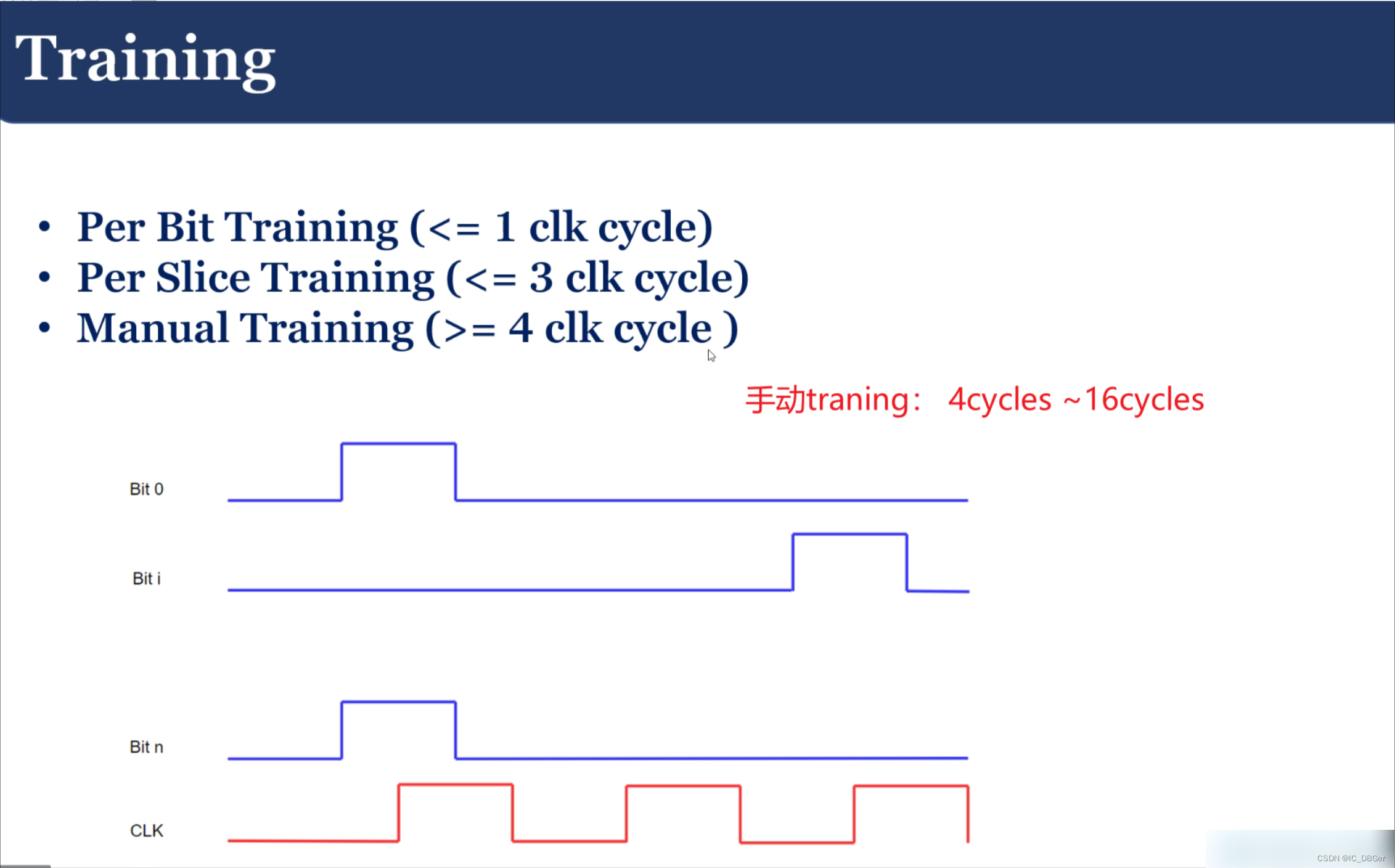
先CA traning, train clk, 接着train read;,最后train write, write training耗时最长,有80-90us,频繁training 会损耗带宽 。
traning 原理,使用“DE”找到每个信号的latency:
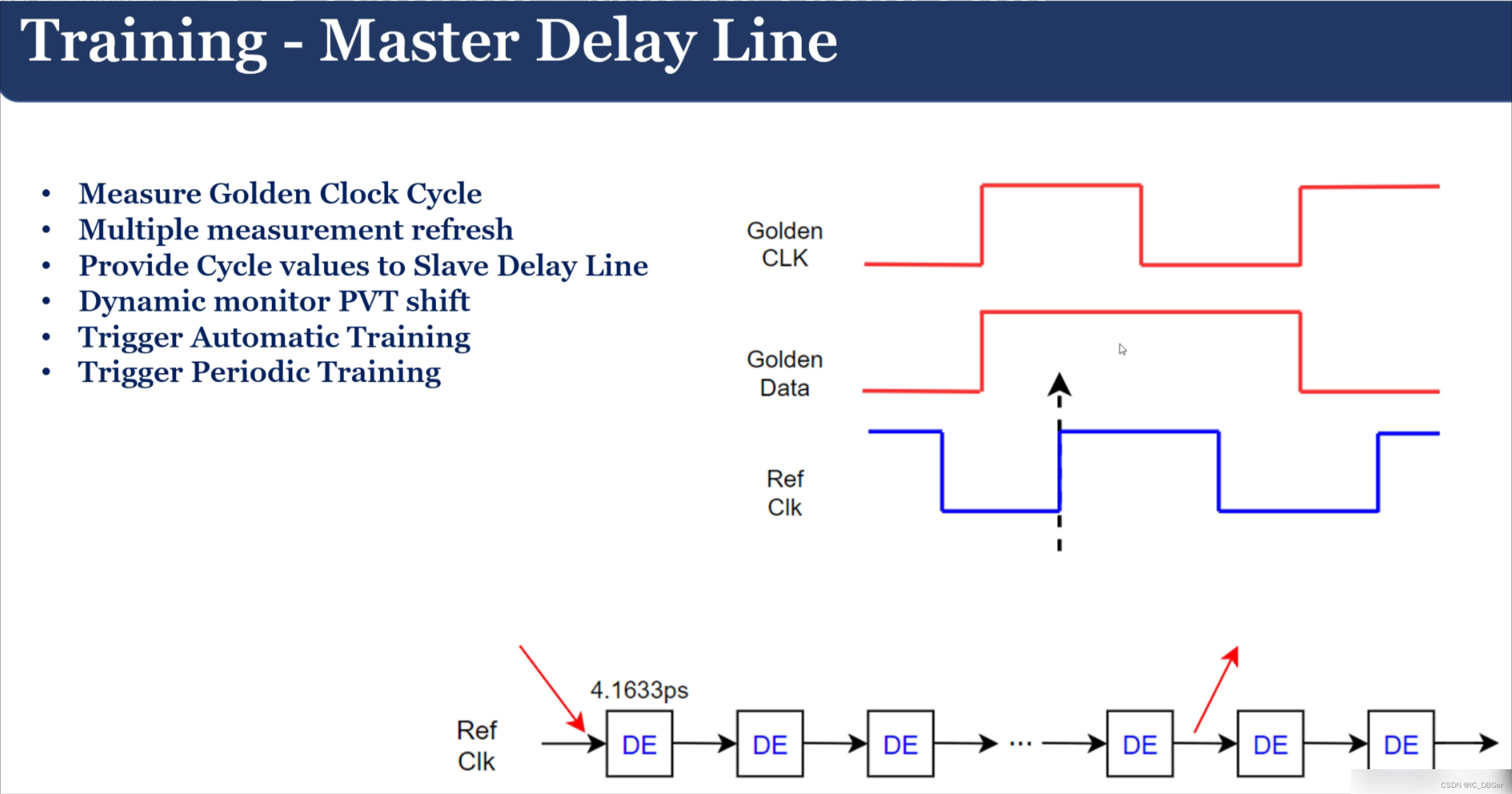
Train sequence 由PHY 自己做的,内部有状态机,用户只需要给一个trigger信号。
一些用于测试的机制:环回测试,内环回,外环回。 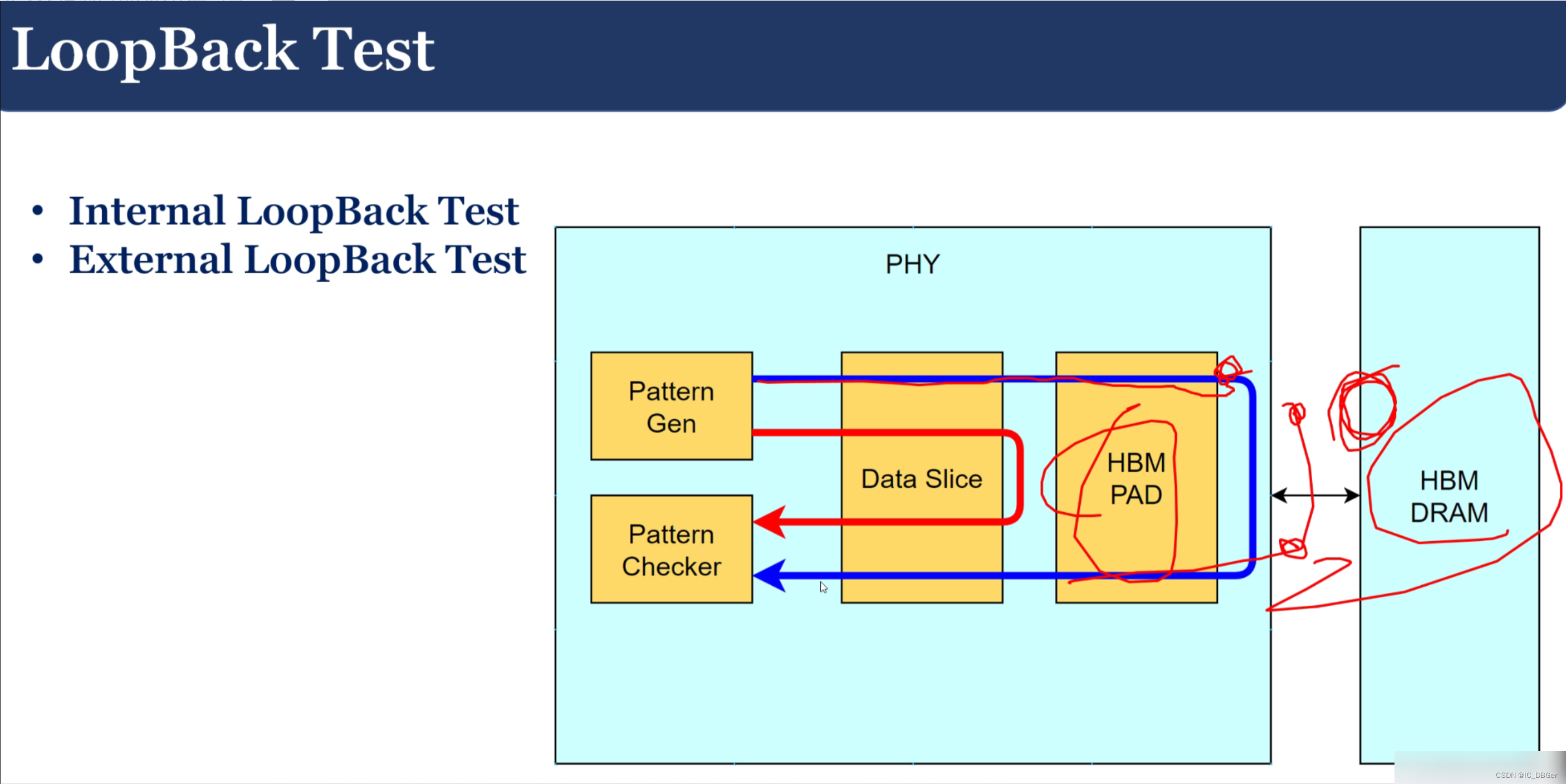
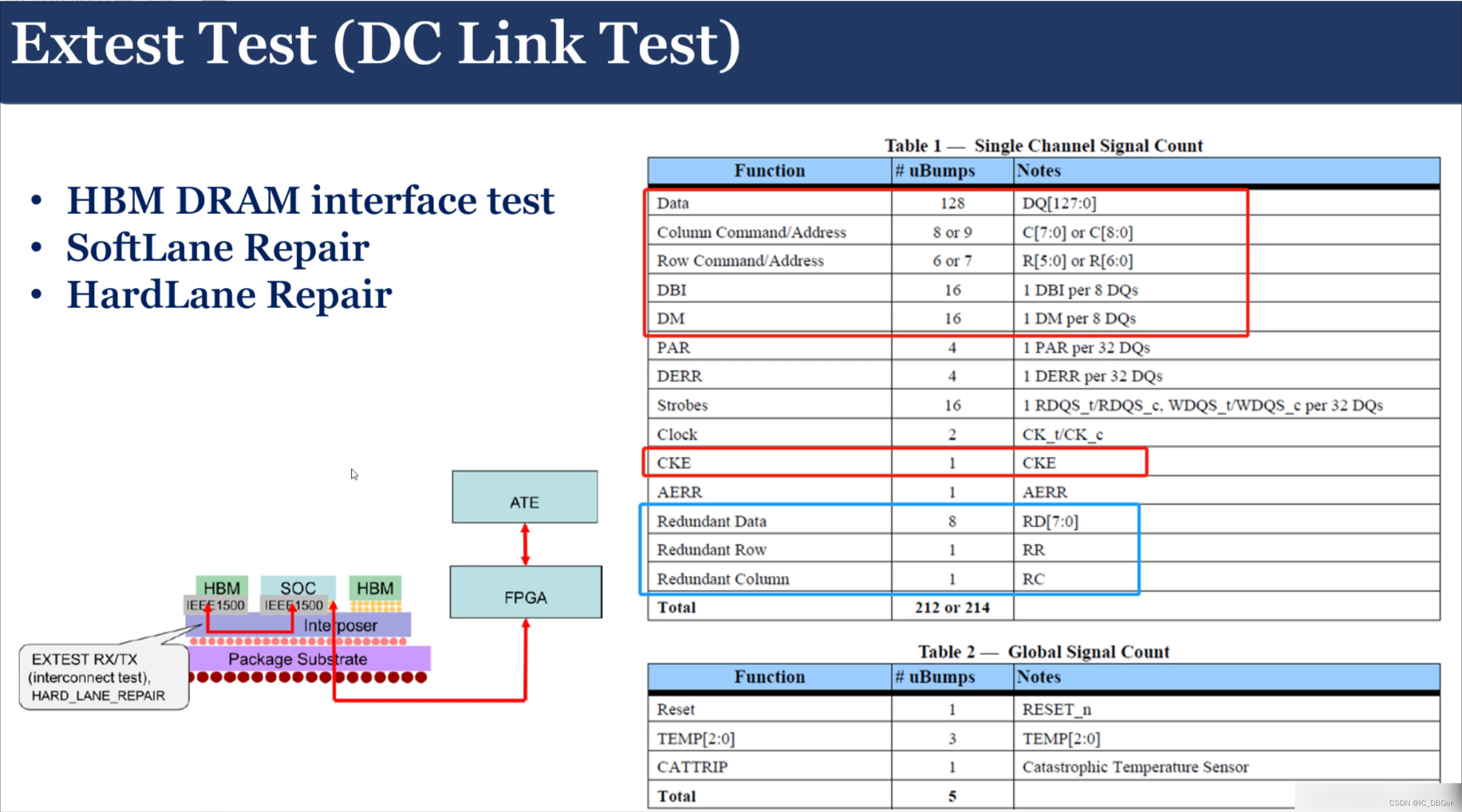
上下电Sequence:


















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









