







 本文介绍了堆数据结构的概念,包括大根堆和小根堆,并重点讲解了Python中的heapq模块,包括heappush、heapreplace、merge、nlargest和nsmallest等方法的使用。还提供了一个堆排序的例子,并讨论了在不同场景下如何选择合适的方法来查找最小或最大的N个元素。heapq模块为处理数据提供了高效的解决方案。
本文介绍了堆数据结构的概念,包括大根堆和小根堆,并重点讲解了Python中的heapq模块,包括heappush、heapreplace、merge、nlargest和nsmallest等方法的使用。还提供了一个堆排序的例子,并讨论了在不同场景下如何选择合适的方法来查找最小或最大的N个元素。heapq模块为处理数据提供了高效的解决方案。
堆的定义
堆是一种特殊的树形数据结构,每个节点都有一个值,通常我们所说的堆的数据结构指的是二叉树。堆的特点是根节点的值最大(或者最小),而且根节点的两个孩子也能与孩子节点组成子树,亦然称之为堆。
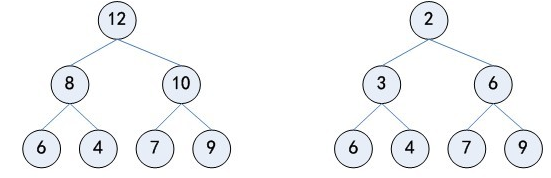
堆分为两种,大根堆和小根堆是一颗每一个节点的键值都不小于(大于)其孩子节点的键值的树。无论是大根堆还是小根堆(前提是二叉堆)都可以看成是一颗完全二叉树。下面以图的形式直观感受一下:
heapq模块
在Python中也对堆这种数据结构进行了模块化,我们可以通过调用heapq模块来建立堆这种数据结构,同时heapq模块也提供了相应的方法来对堆做操作。 heapq模块有以下方法:
__all__ = ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge',
'nlargest', 'nsmallest', 'heappushpop']
heap = [] #创建了一个空堆
heappush(heap,item) #往堆中插入一条新的值
def heappush(heap, item):
"""Push item onto heap, maintaining the heap invariant."""
heap.append(item)
_siftdown(heap, 0, len(heap)-1)
heappop(heap) #从堆中弹出最小值
def heappop(heap):
"""Pop the smallest item off the heap, maintaining the heap invariant."""
lastelt = heap.pop() # raises appropriate IndexError if heap is empty
if heap:
returnitem = heap[0]
heap[0] = lastelt
_siftup(heap, 0)
return returnitem
return lastelt
item = heap[0] #查看堆中最小值,不弹出 heapify(x) #以线性时间讲一个列表转化为堆
def heapify(x):
"""Transform list into a heap, in-place, in O(len(x)) time."""
n = len(x)
# Transform bottom-up. The largest index there's any point to looking at
# is the largest with a child index in-range, so must have 2*i + 1 < n,
# or i < (n-1)/2. If n is even = 2*j, this is (2*j-1)/2 = j-1/2 so
# j-1 is the largest, which is n//2 - 1. If n is odd = 2*j+1, this is
# (2*j+1-1)/2 = j so j-1 is the largest, and that's again n//2-1.
for i in reversed(range(n//2)):
_siftup(x, i)
item = heapreplace(heap,item) #弹出并返回最小值,然后将heapqreplace方法中item的值插入到堆中,堆的整体结构不会发生改变。这里需要考虑到的情况就是如果弹出的值大于item的时候我们可能就需要添加条件来满足function的要求
def heapreplace(heap, item):
"""Pop and return the current smallest value, and add the new item.
This is more efficient than heappop() followed by heappush(), and can be
more appropriate when using a fixed-size heap. Note that the value
returned may be larger than item! That constrains reasonable uses of
this routine unless written as part of a conditional replacement:
if item > heap[0]:
item = heapreplace(heap, item)
"""
return item = heap[0] # raises appropriate IndexError if heap is empty
heap[0] = item
_siftup(heap, 0)
return returnitem
heappushpop() #将值插入到堆中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









