







 本文介绍了如何使用PL/pgSQL语言创建和调用plproxy函数,实现对数据库集群的版本获取、分区查询以及配置读取。通过示例展示了如何在不同场景下使用plproxy进行分布式查询。
本文介绍了如何使用PL/pgSQL语言创建和调用plproxy函数,实现对数据库集群的版本获取、分区查询以及配置读取。通过示例展示了如何在不同场景下使用plproxy进行分布式查询。
plproxy能够在PostgreSQL上运行的一种过程语言,能够完成对远程数据库的调用,并能够完成数据切片的功能。数据流处理过程如下图所示:
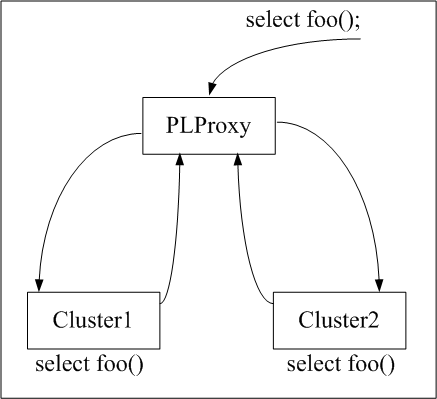
首先需要明确的是plproxy只能对用户自定的方法才有小,如果想达到对sql语句的无条件转发,plproxy是做不到的。比如希望所有的select * from tablename 都转发到cluster1上,所有的update语句都转发到cluster2上,是不能通过plproxy做到的。
plproxy能做到的是:在plproxy cluster上定义foo()函数,在cluster1和cluster2上也定义foo()函数,cluster1和cluster2上的foo()函数的定义是完全相同的,包括函数参数都是相同的;二者和plproxy cluster上的foo()定义均不同。
1. plproxy的关键函数
a. plproxy.get_cluster_version(cluster_name) 举例如下:
该函数返回的是当前plproxy的配置版本号,每当有请求时此函数都会调用。如果该函数的返回值和plproxy的缓存的配置版本号不同,则plproxy会认为配置已经更新,就会调用下面两个函数重新读取配置。
b. plproxy.get_cluster_partitions(cluster_name text) 举例如下:
该函数返回plproxy所设置的内容,当所访问的cluster名称为a_cluster时,返回RETURN NEXT所对应的远程主机配置。
c. plproxy.get_cluster_config(cluster) 举例如下:
该函数返回plproxy与cluser1和cluster2链接时的一些参数,如生命周期,超时时间,是否使用binary IO等。
2. foo()函数的定义:
在plproxy cluster上定义foo的内容如下:
在cluster1和cluster2上定义foo的内容如下:
可以看到,在plproxy上定义的foo()函数的language是“plproxy”,在cluster1和2上的foo()函数定义的language是“plpgsql”,这是最主要的区别。
3. 调用过程
a. 客户端发送select foo()的请求到plproxy cluster;
b. plproxy cluster发现foo()是用户自定义的函数,查找到该函数定义内容发现该函数是通过plproxy language定义的
c. plproxy cluster把控制权转交到plproxy language的handler,
d. 该handler执行foo()的内容,发现该函数需要使用名为"a_cluster"的配置
e. handler调用 plproxy.get_cluster_version("a_cluster"),发现配置版本号相符;
则继续调用 plproxy.get_cluster_partitions("a_cluster")获得四项远程cluster的链接配置;
然后继续调用 plproxy.get_cluster_config( in cluster_name text, out key text, out val text)获得链接时的配
置信息
f. 最后根据 RUN ON hashtext(i_username) & 1 把"select foo()"请求转发到cluster1或者2上。
hashtext(i_username) & 2 会返回一个0-1之间的值,根据这个值确定应该转发请求到哪个具体的cluster上.
g. 在cluster上执行"select foo()",把结果" user already exists"返回给plproxy cluster
h. plproxy cluster再把收到的结果返回给client.
4. plproxy的局限
plproxy并不能完成无条件的转发,只能在自定义的函数上实现此功能。这就要求在实际的应用中,需要把大量的业务逻辑放到PostgreSQL服务器端来完成,降低了灵活度。
一点体会:使用PostgreSQL,需要改变思路,需要适应把业务逻辑通过服务器端编程实现的过程。这是与MySQL的很大不同。
plproxy官方链接
例子: PostgreSQL cluster: partitioning with plproxy (part I)
PostgreSQL cluster: partitioning with plproxy (part II)
plproxy能做到的是:在plproxy cluster上定义foo()函数,在cluster1和cluster2上也定义foo()函数,cluster1和cluster2上的foo()函数的定义是完全相同的,包括函数参数都是相同的;二者和plproxy cluster上的foo()定义均不同。
1. plproxy的关键函数
a. plproxy.get_cluster_version(cluster_name) 举例如下:
- CREATE OR REPLACE FUNCTION plproxy.get_cluster_version(cluster_name text)
- RETURNS int4 AS $$
- BEGIN
- IF cluster_name = 'a_cluster' THEN
- RETURN 1;
- END IF;
- RAISE EXCEPTION 'Unknown cluster';
- END;
- $$ LANGUAGE plpgsql;
b. plproxy.get_cluster_partitions(cluster_name text) 举例如下:
- CREATE OR REPLACE FUNCTION plproxy.get_cluster_partitions(cluster_name text)
- RETURNS SETOF text AS $$
- BEGIN
- IF cluster_name = 'a_cluster' THEN
- RETURN NEXT 'dbname=part00 host=127.0.0.1';
- RETURN NEXT 'dbname=part01 host=127.0.0.1';
- RETURN;
- END IF;
- RAISE EXCEPTION 'Unknown cluster';
- END;
- $$ LANGUAGE plpgsql;
c. plproxy.get_cluster_config(cluster) 举例如下:
- CREATE OR REPLACE FUNCTION plproxy.get_cluster_config(
- in cluster_name text,
- out key text,
- out val text)
- RETURNS SETOF record AS $$
- BEGIN
- -- lets use same config for all clusters
- key := 'connection_lifetime';
- val := 30*60; -- 30m
- RETURN NEXT;
- RETURN;
- END;
- $$ LANGUAGE plpgsql;
2. foo()函数的定义:
在plproxy cluster上定义foo的内容如下:
- CREATE OR REPLACE FUNCTION foo(i_username text)
- RETURNS text AS
- $BODY$
- CLUSTER 'a_cluster'; RUN ON hashtext(i_username) & 1;
- $BODY$
- LANGUAGE 'plproxy' VOLATILE
- COST 100;
- CREATE OR REPLACE FUNCTION foo(i_username text)
- RETURNS text AS
- $BODY$
- BEGIN
- RETURN 'user already exists';
- END;
- $BODY$
- LANGUAGE 'plpgsql' VOLATILE SECURITY DEFINER
- COST 100;
3. 调用过程
a. 客户端发送select foo()的请求到plproxy cluster;
b. plproxy cluster发现foo()是用户自定义的函数,查找到该函数定义内容发现该函数是通过plproxy language定义的
c. plproxy cluster把控制权转交到plproxy language的handler,
d. 该handler执行foo()的内容,发现该函数需要使用名为"a_cluster"的配置
e. handler调用 plproxy.get_cluster_version("a_cluster"),发现配置版本号相符;
则继续调用 plproxy.get_cluster_partitions("a_cluster")获得四项远程cluster的链接配置;
然后继续调用 plproxy.get_cluster_config( in cluster_name text, out key text, out val text)获得链接时的配
置信息
f. 最后根据 RUN ON hashtext(i_username) & 1 把"select foo()"请求转发到cluster1或者2上。
hashtext(i_username) & 2 会返回一个0-1之间的值,根据这个值确定应该转发请求到哪个具体的cluster上.
g. 在cluster上执行"select foo()",把结果" user already exists"返回给plproxy cluster
h. plproxy cluster再把收到的结果返回给client.
4. plproxy的局限
plproxy并不能完成无条件的转发,只能在自定义的函数上实现此功能。这就要求在实际的应用中,需要把大量的业务逻辑放到PostgreSQL服务器端来完成,降低了灵活度。
一点体会:使用PostgreSQL,需要改变思路,需要适应把业务逻辑通过服务器端编程实现的过程。这是与MySQL的很大不同。
plproxy官方链接
例子: PostgreSQL cluster: partitioning with plproxy (part I)
PostgreSQL cluster: partitioning with plproxy (part II)















 4141
4141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









