







问题描述
点此链接
Given a 2D board and a list of words from the dictionary, find all words in the board.
Each word must be constructed from letters of sequentially adjacent cell, where “adjacent” cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.
For example,
Given words = [“oath”,”pea”,”eat”,”rain”] and board =
[
['o','a','a','n'],
['e','t','a','e'],
['i','h','k','r'],
['i','f','l','v']
]
Return [“eat”,”oath”].
问题分析
目标就是在一个字符“面板”上判定指定字符串组中存在的所有非重复字符串。在之前做过在字符“面板”上判定一个字符串是否存在,它的核心思想就是回溯,只要找到一个匹配字符串即可满足条件。而这里是对多组字符串判定,要求有比较好的时间复杂度。所以要把查找过的字符串作为历史信息存储起来,从而如果后续字符串有前缀和之前的历史信息相同,则可以节省一大部分时间。这里使用的是字典树,同时为了维护好历史信息,需要认真设计好字典树结点。
举个例子来说明结点需要记录的信息:board为{“ab”,”aa”},当前判定字符串为”aabb”。记录结果如下图所示:
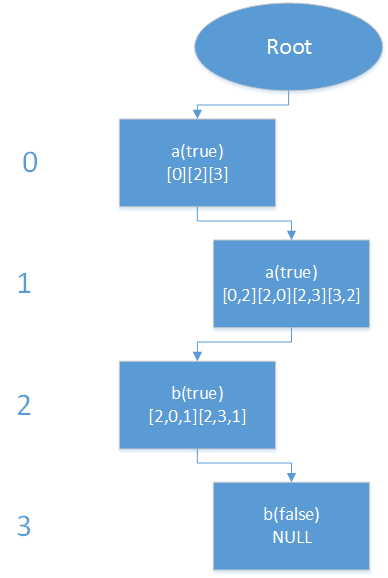
注:字符在二维数组中的位置我用了i*n+j来进行存储,n为数组列大小。board中各个字符的位置分别为0,1,2,3.
说明:
- true/false表示到该节点时的字符串前缀是否存在于board中,如第三层b为false,表示“aabb”在board中不存在;
- []表示到该节点时的字符串前缀存在的一种可能性的各个字符的位置。
这样存储后我们如果在后面的字符串数组中带有”a*”,”aa*”,”aab*”,”aabb*”都可以从前缀的后一个字符开始判定,同时我们可以明显看出aabb*不要要继续判定,因为查找到第3层(0层开始)时,已经判定为false!
综上,结点设计如下:
class TrieNode {
public:
//数据
char data;
//子结点
TrieNode *m[26];
//该结点的高度
int cur_idx;
//到达该字母时的字符串是否在board中
bool isExist;
//在isExist==true的前提下存储到目前为止的候选集合
vector<vector<int>> cand;
public:
// Initialize your data structure here.
TrieNode() {
for (int i = 0; i < 26; i++){
m[i] = NULL;
}
cur_idx = 0;
}
TrieNode(char d, bool isEx, int idx){
data = d;
isExist = isEx;
for (int i = 0; i < 26; i++){
m[i] = NULL;
}
cur_idx = idx;
}
};
其他部分的实现(字符串判定)在之前已经实现,全部代码可以参考我commit的github代码。















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









