







今天面试官问了一些协议的基本知识,FTP的传输模式没答上来,特总结一下,也衍生把以前接触的各种协议总结一下,包括:TCP/IP,SFTP,HTTPS,CIFS,HTTP。
1.什么是FTP协议;
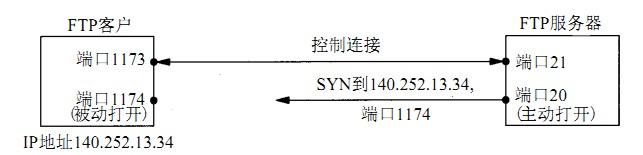
先简单理解就是:在主动模式下,客户端首先向服务器端发送IP地址和端口号,然后等待服务器端建立TCP链接。在被动模式下,客户端同样首先建立到服务器的链接,但服务器端会开启一个端口(1024到5000之间),等待客户端传输数据。
Port
Passive
为了跟了解FTP的工作机制,启用wireshark进行抓包得到如下的结果:
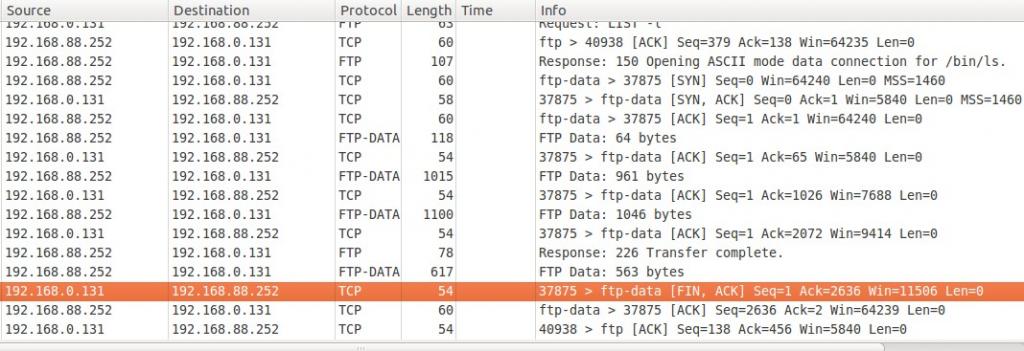
图中亮起的一行是本机37875端口向服务器的ftp-data(20)端口发送结束数据传输连接的【FIN,ACK】请求(在前面几行还可以见到连接同步请求SYN)。
控制连接的两个端口号分别是40938和ftp(21)。
此外,在百度百科中看见貌似启用数据连接时用的是控制连接的随机端口号+1,虽然在《TCP/IP详解》中所举例子都是符合这一说法,但是其在文中详细说明的时候并没有这样表述。而且从抓包实验中也可以看到,37875与40938貌似没有服从这种+1的关系。
-
FTP的IPv6扩展(EPRT和EPSV)
1.与防火墙工作不协调
在文件传输协议(FTP)诞生在网络地址转换(NAT)和防火墙之前,那时的网络还不存在恶意攻击。今天大多数最终用户的IPv4地址已不可路由,这是因为防火墙的使用和IPv4地址的短缺。
这对FTP意味着什么呢?这意味着如果FTP客户端IP地址不可路由,或者位于防火墙之后,那么就只能使用被动传输模式进行数据传输。
如果服务器端的IP地址也不可路由,或者位于防火墙之后呢?FTP将无法进行数据传输!
现在,许多防火墙适用于NAT环境,可以使用一些特殊的技巧(hacks)允许FTP在防火墙之后正常工作。当然,这需要对防火墙进行配置。
2.密码安全策略不完善
在互联网早期,文件传输协议(FTP)并没有对密码安全作出规定。在FTP客户端和服务器端,数据以明文的形式传输,任何对通讯路径上的路由具有控制能力的人,都可以通过嗅探获取你的密码和数据。
我们当然可以使用SSL封装FTP,但FTP是通过建立多次链接进行数据传输的,我们即便是保护了密码安全,也很难保护数据传输的安全性。
自文件传输协议(FTP)发布以来,安全的数据传输也经历了长足发展,推荐使用SCP取代FTP进行文件传输。
从FTP服务器上检索一个文件,包含繁复的交换握手步骤:
客户端建立到FTP服务器端控制端口的TCP Socket链接,并等待TCP握手完成
客户端等待服务器端发送回执
客户端向服务器端发送用户名并等待响应
客户端向服务器端发送密码并等待响应
客户端向服务器端发送SYST命令并等待响应
客户端向服务器端发送TYPE I命令并等待响应
如果用户需要在服务器端切换目录,客户端仍然发送命令并等待响应
主动模式下,客户端需要发送PORT命令到服务器端,然后等待响应(被动模式与主动模式相反)
建立数据传输链接(需要经过三次握手,建立一条TCP Socket连接)
通过链接传输数据
客户端等待服务器端从控制连接发送2xx指令,以确保数据传输成功
客户端发送QUIT命令,并等待服务器响应
同样的情形,我们来看看HTTP协议:
HTTP客户端向HTTP服务器端建立一条TCP Socket连接
HTTP客户端向HTTP服务器端发送GET命令,包含URL、HTTP协议版本、虚拟主机名等等,并等待响应
HTTP服务器端的响应包含了所有想要的数据,完成!
传输一个文件,FTP需要往复10次,而HTTP只需要2次!如果传输多个文件,FTP可以省略发送用户名和密码的步骤,而HTTP则可以使用固定的套接字(Socket),在相同的TCP连接中传输文件。
注:ACK 在数据通信中,接收站发给发送站的一种传输类确认控制字符
SYN (Synchronize)
标记的包
SYN (Synchronize)
标记的包
SYN (Synchronize) 标记的包总的归纳如下;
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG.
其中,对于我们日常的分析有用的就是前面的五个字段。
它们的含义是:
SYN表示建立连接,
FIN表示关闭连接,
ACK表示响应,
PSH表示有 DATA数据传输,
RST表示连接重置。
其中,ACK是可能与SYN,FIN等同时使用的,比如SYN和ACK可能同时为1,它表示的就是建立连接之后的响应,
如果只是单个的一个SYN,它表示的只是建立连接。
TCP的几次握手就是通过这样的ACK表现出来的。
但SYN与FIN是不会同时为1的,因为前者表示的是建立连接,而后者表示的是断开连接。
RST一般是在FIN之后才会出现为1的情况,表示的是连接重置。
一般地,当出现FIN包或RST包时,我们便认为客户端与服务器端断开了连接;而当出现SYN和SYN+ACK包时,我们认为客户端与服务器建立了一个连接。
PSH为1的情况,一般只出现在 DATA内容不为0的包中,也就是说PSH为1表示的是有真正的TCP数据包内容被传递。
TCP的连接建立和连接关闭,都是通过请求-响应的模式完成的。
-------------------------------存在即合理,FTP还是使用很广泛!
附录1其他协议之TCP/IP:
TCP/IP 三次握手 ---from: http://swiftlet.net/archives/1082
在面试的过程中,TCP的传输协议经常会出现。以前我参加面试的过程中就被问到过,现在轮到我面试其他人的时候,我也会问一些相关的问题。作为一名开发者,无论使用什么样的开发语言,最基本的网络知识一定要理解透彻,这样才能获得更好的职业发展。
TCP链接协议概述
建立TCP需要三次握手才能建立,而断开连接则需要四次握手。整个过程如下图所示:
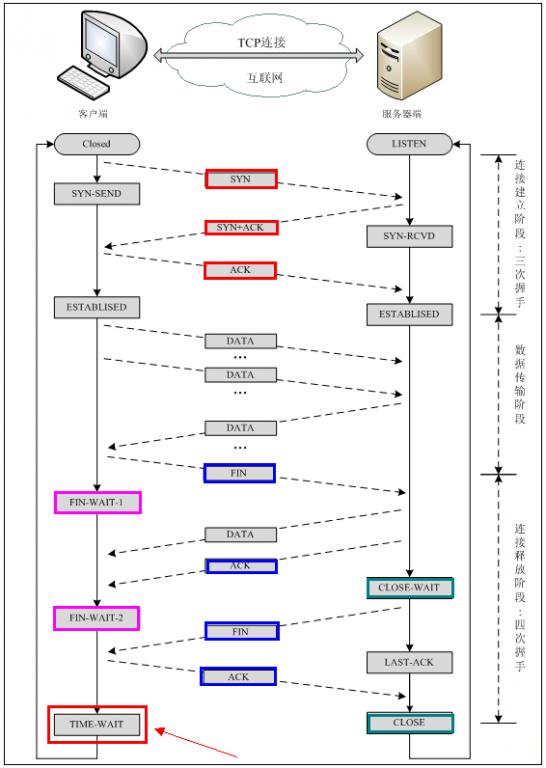
建立连接的过程
首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。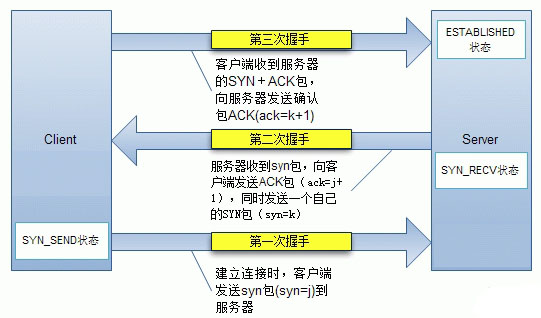
断开连接的过程
断开连接端可以是Client端,也可以是Server端。假设1.Client端发起中断连接请求,就先发送FIN报文。Server端接到FIN报文后,但是如果还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以2.服务器端先发送ACK,告诉Client端:请求已经收到了,但是我还没准备好,请继续等待停止的消息。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当3.Server端确定数据已发送完成,则向Client端发送FIN报文,告诉Client端:服务器这边数据发完了,准备好关闭连接了。4.Client端收到FIN报文后,就知道可以关闭连接了,但是他还是不相信网络,所以发送ACK后进入TIME_WAIT状态, Server端收到ACK后,就知道可以断开连接了。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,最后,Client端也可以关闭连接了至此,TCP连接就已经完全关闭了!关闭连接的过程如下图所示:

附录2:曾今实习用到的SFTP协议
注:SFTP ------S--+ ---FTP(其中S为SSH)
一、协议的含义
SFTP协议能够进行“远程文件获取,文件内容传输,文件管理”等操作,它的控制信号和数据信号的传输通过安全数据通道进行。一般情况下,这个安全数据通道由SSH连接提供,即SSH连接隧道作为安全数据通道。
跟只能进行简单文件内容传输的SCP协议相比,SFTP协议更像是一个远程文件系统协议。
SFTP协议工作于OSI七层体系的应用层。
二、协议的原理
SFTP协议分为两个端,分别是SFTP Client和SFTP Server。SFTP Client和SFTP Server之间的控制信号和文件内容的传输得通过安全数据通道进行,安全数据通道可由“Transport Layer Security(TLS)”,“SSH”等协议提供,一般情况下是由SSH协议提供。
一旦SFTP Client和SFTP Server之间的连接得以建立,就可以通过二者之间的控制信号和文件内容的传输实现远程文件系统的功能。
SFTP是SSH File Transfer Protocol的缩写,就是SSH文件传输协议。一般的FTP客户端比如Filezilla或者CuteFTP都支持SFTP。那么如何创建SFTP服务呢?我们使用OpenSSH,这个软件在Linux下是自带的软件包。往日传东西上服务器,因为搭建不是我搭建的架构,我用Filezilla来传提示失败,然后我就找原因以为服务器ftp服务没开就上服务器上找发现没找到有ftp的服务。我就纳闷平常看同事都是这样传上去。后来想想是不是用了SFTP呢,看了一下果然而且前几天自己刚刚改了ssh端口用同事原来设的22端口果断登不上去的。改了一下端口就可以。
一般来说两台机器间的文件传输,除了常用的ftp以外,还可以通过scp/sftp协议(就是本文介绍的sftp)进行。下面我们就来看看sftp协议与ftp协议之间的差别。
(1)和ftp不同的是sftp/scp传输协议默认是采用加密方式来传输数据的,scp/sftp确保传输的一切数据都是加密的。而ftp一般来说允许明文传输,当然现在也有带SSL的加密ftp,有些服务器软件也可以设置成“只允许加密连接”,但是毕竟不是默认设置需要我们手工调整,而且很多用户都会忽略这个设置。
(2)普通ftp仅使用端口21作为命令传输。由服务器和客户端协商另外一个随机端口来进行数据传送。在pasv模式下,服务器端需要侦听另一个口。假如服务器在路由器或者防火墙后面,端口映射。会比较麻烦,因为无法提前知道数据端口编号,无法映射。(现在的ftp服务器大都支持限制数据端口随机取值范围,一定程度上解决这个问题,但仍然要映射21号以及一个数据端口范围,还有些服务器通过UPnP协议与路由器协商动态映射,但比较少见)
(3)当你的网络中还有一些unix系统的机器时,在它们上面自带了scp等客户端,不用再安装其它软件来实现传输目的。
(4)scp/sftp属于开源协议,我们可以免费使用不像FTP那样使用上存在安全或版权问题。所有scp/sftp传输软件(服务器端和客户端)均免费并开源,方便我们开发各种扩展插件和应用组件。
小提示:当然在提供安全传输的前提下sftp还是存在一些不足的,例如他的帐号访问权限是严格遵照系统用户实现的,只有将该帐户添加为操作系统某用户才能够保证其可以正常登录sftp服务器。
附录3:曾今实习用到的HTTPS协议
from:http://www.jb51.net/network/68135.html
我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取。所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。
HTTPS简介
HTTPS其实是有两部分组成:HTTP + SSL / TLS(安全传输层协议(TLS)用于在两个通信应用程序之间提供保密性和数据完整性。该协议由两层组成: TLS 记录协议(TLS Record)和 TLS 握手协议(TLS Handshake)。)(SSL(Secure Sockets Layer 安全套接层),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层对网络连接进行加密。SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层: SSL记录协议(SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。 SSL握手协议(SSL Handshake Protocol):它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。),也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。具体是如何进行加密,解密,验证的,且看下图。

这个没什么好说的,就是用户在浏览器里输入一个https网址,然后连接到server的443端口。
2. 服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥。如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3. 传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4. 客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值。然后用证书对该随机值进行加密。就好像上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
5. 传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6. 服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7. 传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在客户端被还原。
8. 客户端解密信息
客户端用之前生成的私钥解密服务段传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
附录4:HTTP协议:
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。
HTTP协议的主要特点可概括如下:
1.支持客户/服务器模式。
2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3.灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
4.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
5.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
一、HTTP
1.1 HTTP协议详解之URL篇
http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连接的机制,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
HTTP URL (URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息)的格式如下:
http://host[":"port][abs_path]
http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或者IP地址;port指定一个端口号,为空则使用缺省端口80;abs_path指定请求资源的URI;如果URL中没有给出abs_path,那么当它作为请求URI时,必须以“/”的形式给出,通常这个工作浏览器自动帮我们完成。
eg:
1、输入:www.guet.edu.cn 浏览器自动转换成:http://www.guet.edu.cn/
2、http:192.168.0.116:8080/index.jsp
1.2 HTTP协议详解之请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
1、请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:
Method Request-URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
应用举例:
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
eg:POST /reg.jsp HTTP/ (CRLF)
Accept:image/gif,image/x-xbit,... (CRLF)
...
HOST:www.guet.edu.cn (CRLF)
Content-Length:22 (CRLF)
Connection:Keep-Alive (CRLF)
Cache-Control:no-cache (CRLF)
(CRLF) //该CRLF表示消息报头已经结束,在此之前为消息报头
user=jeffrey&pwd=1234 //此行以下为提交的数据
HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
2、请求报头后述
3、请求正文(略)
1.3 HTTP协议详解之响应篇
在接收和解释请求消息后,服务器返回一个HTTP响应消息。
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
1、状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
2、响应报头后述
3、响应正文就是服务器返回的资源的内容
1.4 HTTP协议详解之消息报头篇
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成。请求消息和响应消息都是由开始行(对于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行),消息报头(可选),空行(只有CRLF的行),消息正文(可选)组成。
HTTP消息报头包括普通报头、请求报头、响应报头、实体报头。
每一个报头域都是由名字+“:”+空格+值 组成,消息报头域的名字是大小写无关的。
1、普通报头
在普通报头中,有少数报头域用于所有的请求和响应消息,但并不用于被传输的实体,只用于传输的消息。
eg:
Cache-Control 用于指定缓存指令,缓存指令是单向的(响应中出现的缓存指令在请求中未必会出现),且是独立的(一个消息的缓存指令不会影响另一个消息处理的缓存机制),HTTP1.0使用的类似的报头域为Pragma。
请求时的缓存指令包括:no-cache(用于指示请求或响应消息不能缓存)、no-store、max-age、max-stale、min-fresh、only-if-cached;
响应时的缓存指令包括:public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、max-age、s-maxage.
eg:为了指示IE浏览器(客户端)不要缓存页面,服务器端的JSP程序可以编写如下:response.sehHeader("Cache-Control","no-cache");
//response.setHeader("Pragma","no-cache");作用相当于上述代码,通常两者//合用
这句代码将在发送的响应消息中设置普通报头域:Cache-Control:no-cache
Date普通报头域表示消息产生的日期和时间
Connection普通报头域允许发送指定连接的选项。例如指定连接是连续,或者指定“close”选项,通知服务器,在响应完成后,关闭连接
2、请求报头
请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
常用的请求报头
Accept请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,表明客户端希望接受GIF图象格式的资源;Accept:text/html,表明客户端希望接受html文本。
Accept-Charset请求报头域用于指定客户端接受的字符集。eg:Accept-Charset:iso-8859-1,gb2312.如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。、
Accept-Encoding请求报头域类似于Accept,但是它是用于指定可接受的内容编码。eg:Accept-Encoding:gzip.deflate.如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language请求报头域类似于Accept,但是它是用于指定一种自然语言。eg:Accept-Language:zh-cn.如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。
Authorization请求报头域主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收到服务器的响应代码为401(未授权),可以发送一个包含Authorization请求报头域的请求,要求服务器对其进行验证。
Host请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的,发送请求时,该报头域是必需的,eg:我们在浏览器中输入:http://www.guet.edu.cn/index.html
浏览器发送的请求消息中,就会包含Host请求报头域,如下:Host:www.guet.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:www.guet.edu.cn:指定端口号
User-Agent我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息。User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。不过,这个报头域不是必需的,如果我们自己编写一个浏览器,不使用User-Agent请求报头域,那么服务器端就无法得知我们的信息了。
请求报头举例:
GET /form.html HTTP/1.1 (CRLF)
Accept:image/gif,image/x-xbitmap,image/jpeg,application/x-shockwave-flash,application/vnd.ms-excel,application/vnd.ms-powerpoint,application/msword,*/* (CRLF)
Accept-Language:zh-cn (CRLF)
Accept-Encoding:gzip,deflate (CRLF)
If-Modified-Since:Wed,05 Jan 2007 11:21:25 GMT (CRLF)
If-None-Match:W/"80b1a4c018f3c41:8317" (CRLF)
User-Agent:Mozilla/4.0(compatible;MSIE6.0;Windows NT 5.0) (CRLF)
Host:www.guet.edu.cn (CRLF)
Connection:Keep-Alive (CRLF)
(CRLF)
3、响应报头
响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。
常用的响应报头
Location响应报头域用于重定向接受者到一个新的位置。Location响应报头域常用在更换域名的时候。
Server响应报头域包含了服务器用来处理请求的软件信息。与User-Agent请求报头域是相对应的。下面是Server响应报头域的一个例子:Server:Apache-Coyote/1.1
WWW-Authenticate响应报头域必须被包含在401(未授权的)响应消息中,客户端收到401响应消息时候,并发送Authorization报头域请求服务器对其进行验证时,服务端响应报头就包含该报头域。
eg:WWW-Authenticate:Basic realm="Basic Auth Test!" //可以看出服务器对请求资源采用的是基本验证机制。
4、实体报头
请求和响应消息都可以传送一个实体。一个实体由实体报头域和实体正文组成,但并不是说实体报头域和实体正文要在一起发送,可以只发送实体报头域。实体报头定义了关于实体正文(eg:有无实体正文)和请求所标识的资源的元信息。
常用的实体报头
Content-Encoding实体报头域被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编码,因而要获得Content-Type报头域中所引用的媒体类型,必须采用相应的解码机制。Content-Encoding这样用于记录文档的压缩方法,eg:Content-Encoding:gzip
Content-Language实体报头域描述了资源所用的自然语言。没有设置该域则认为实体内容将提供给所有的语言阅读
者。eg:Content-Language:da
Content-Length实体报头域用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
Content-Type实体报头域用语指明发送给接收者的实体正文的媒体类型。eg:
Content-Type:text/html;charset=ISO-8859-1
Content-Type:text/html;charset=GB2312
Last-Modified实体报头域用于指示资源的最后修改日期和时间。
Expires实体报头域给出响应过期的日期和时间。为了让代理服务器或浏览器在一段时间以后更新缓存中(再次访问曾访问过的页面时,直接从缓存中加载,缩短响应时间和降低服务器负载)的页面,我们可以使用Expires实体报头域指定页面过期的时间。eg:Expires:Thu,15 Sep 2006 16:23:12 GMT
HTTP1.1的客户端和缓存必须将其他非法的日期格式(包括0)看作已经过期。eg:为了让浏览器不要缓存页面,我们也可以利用Expires实体报头域,设置为0,jsp中程序如下:response.setDateHeader("Expires","0");
作者:Jeffrey 转自:http://blog.csdn.net/gueter/article/details/1524447
工具类为HttpUtil.java
public class HttpUtil {
public static String httpGet(String httpUrl) {
String result = "";
DefaultHttpClient httpclient = new DefaultHttpClient();// 创建http客户端
HttpGet httpget = new HttpGet(httpUrl);
HttpResponse response = null;
HttpParams params = httpclient.getParams(); // 计算网络超时用
HttpConnectionParams.setConnectionTimeout(params, 15 * 1000);
HttpConnectionParams.setSoTimeout(params, 20 * 1000);
try {
response = httpclient.execute(httpget);
HttpEntity entity = response.getEntity();// 得到http的内容
response.getStatusLine().getStatusCode();// 得到http的状态返回值
result = EntityUtils.toString(response.getEntity());// 得到具体的返回值,一般是xml文件
entity.consumeContent();// 如果entity不为空,则释放内存空间
httpclient.getCookieStore();// 得到cookis
httpclient.getConnectionManager().shutdown();// 关闭http客户端
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
public static String httpPost(String httpUrl, String data) {
String result = "";
DefaultHttpClient httpclient = new DefaultHttpClient();
HttpPost httpPost = new HttpPost(httpUrl);
// httpclient.setCookieStore(DataDefine.mCookieStore);
HttpParams params = httpclient.getParams(); // 计算网络超时用
HttpConnectionParams.setConnectionTimeout(params, 15 * 1000);
HttpConnectionParams.setSoTimeout(params, 20 * 1000);
httpPost.setHeader("Content-Type", "text/xml");
StringEntity httpPostEntity;
try {
httpPostEntity = new StringEntity(data, "UTF-8");
httpPost.setEntity(httpPostEntity);
HttpResponse response = httpclient.execute(httpPost);
HttpEntity entity = response.getEntity();// 得到http的内容
response.getStatusLine().getStatusCode();// 得到http的状态返回值
result = EntityUtils.toString(response.getEntity());// 得到具体的返回值,一般是xml文件
entity.consumeContent();// 如果entity不为空,则释放内存空间
httpclient.getCookieStore();// 得到cookis
httpclient.getConnectionManager().shutdown();// 关闭http客户端
} catch (Exception e) {
e.printStackTrace();
}// base64是经过编码的字符串,可以理解为字符串
// StringEntity httpPostEntity = new StringEntity("UTF-8");
return result;
}
}附录5:CIFS协议
注:多用于windows系统
CIFS (Common Internet File System)通用Internet文件系统,属于微软公司的一种私有协议。
CIFS是一个新提出的协议,它使程序可以访问远程Internet计算机上的文件并要求此计算机的服务。CIFS使用客户/服务器模式。客户程序请求远在服务器上的服务器程序为它提供服务。服务器获得请求并返回响应。CIFS是公共的或开放的SMB协议版本,并由Microsoft使用。SMB协议现在是局域网上用于服务器文件访问和打印的协议。象SMB协议一样,CIFS在高级运行,而不象TCP/IP协议那样运行在底层。CIFS可以看做是现丰应用程序协议如文件传输协议和超文本传输协议的一个实现。
CIFS可以使您达到以下功能:
1. 访问服务器本地文件并读写这些文件
2. 与其它用户一起共享一些文件块
3. 在断线时自动恢复与网络的连接 (--interop, 往往会有error信息提示, 不了解可能以为是bug)
4. 使用西欧字符文件名 (--支持ASCII字符集, 西欧字符也在内..命名比MS OS下有个性多了:-))
一般来说,CIFS使用户得到比FTP更好的对文件的控制。它提供潜在的更直接地服务器程序接口,这比使用HTTP协议的浏览器更好。
CIFS是开放组标准而且已经被作为Internet应用程序标准被提交到IETF。
通用网际文件系统(CIFS)是微软服务器消息块协议(SMB)的增强版本,是计算机用户在企业内部网和因特网上共享文件的标准方法。CIFS 通过定义一种与应用程序在本地磁盘和网络文件服务器上共享数据的方式相兼容的远程文件访问协议使之能够在因特网上进行协作。CIFS 在 TCP/IP 上运行,利用因特网上的全球域名服务系统(DNS)增强其可扩展性,同时为因特网上普遍存在的慢速拨号连接优化。CIFS 利用重定向包可以通过网络发送至远端设备,而重定向器也利用 CIFS 向本地计算机的协议栈发出请求。
CIFS 提供如下关键特点:
l 文件访问的完整性:CIFS 支持一套通用的文件操作:打开、关闭、读,写以及搜索。CIFS 也支持文件和记录的锁定和解锁。CIFS 允许多个客户端访问和更新同一个文件,它通过提供文件共享和文件锁定功能来避免发生冲突。
l 为慢速链接优化:CIFS 已被优化过,使之能在慢速拨号线路上良好运行,结果就是为使用调制解调器访问因特网的用户提供了改善的性能。
l 安全性:CIFS 服务器既支持匿名传输,也支持对于指定文件的安全的、需要验证的访问。同时,也易于管理文件和目录的安全策略。
l 高性能和可扩展性:CIFS 服务器和操作系统高度集成,为最大化系统性能而优化。CIFS 支持 Windows 95 之后的所有微软平台。它也支持其它流行的操作系统,如 UNIX、VMS、Macintosh 、IBM LAN server等。
l 使用统一码(Unicode)文件名:文件名可以使用任何字符集,而不局限于为英语或西欧语言设计的字符集。
l 全局文件名:用户不必挂载远程文件系统也能直接查阅到全局有效名称,而不是只有本地意义的那些名称。
协议结构
CIFS 和 SMB 定义了许多客户端和服务器端的命令和消息。这些命令和消息大致可分为如下几类:
l 连接建立消息:包括开始或结束一个到服务器上共享资源的重定向连接的命令。
l 命名空间和文件处理消息:重定向器利用这个消息获得对服务器上文件的访问并对其进行读写操作。
l 打印消息:重定向器利用此消息向服务器上的打印队列发送数据和获得打印队列的状态信息。
l 其它消息:重定向器利用这些消息向邮槽和命名管道写入信息。
附录6:网关协议
CGI
注:vs java
| 各有各的用途。 Java用的这么广泛,感觉最大原因是有庞大的各种各样的框架和库,让开发人员专注业务,不用花太多时间考虑技术实现问题。 而CGI也不是一个客户端对应一个进程了,性能也不差。区别还是上面,做嵌入式小型web server很不错,做大业务肯定不方便。 顺便一提,发现python 的tornado类似的web server,比传统的cgi方便多了。 |
CGI即通用网关接口(Common Gateway Interface),是外部应用程序(CGI程序)与Web服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的规程。CGI规范允许 Web服务器执行外部程序,并将它们的输出发送给Web浏览器,CGI将Web的一组简单的静态超媒体文档变成一个完整的新的交互式媒体。通俗的讲CGI 就像是一座桥,把网页和WEB服务器中的执行程序连接起来,它把HTML接收的指令传递给服务器的执行程序,再把服务器执行程序的结果返还给HTML页。 CGI 的跨平台性能极佳,几乎可以在任何操作系统上实现。
CGI方式在遇到连接请求(用户请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程。这就是fork- and-execute模式。所以用cgi方式的服务器有多少连接请求就会有多少cgi子进程,子进程反复加载是cgi性能低下的主要原因。当用户请求数 量非常多时,会大量挤占系统的资源如内存,CPU时间等,造成效能低下。
CGI脚本工作流程:
- 浏览器通过HTML表单或超链接请求指向一个CGI应用程序的URL。
- 服务器收发到请求。
- 服务器执行所指定的CGI应用程序。
- CGI应用程序执行所需要的操作,通常是基于浏览者输入的内容。
- CGI应用程序把结果格式化为网络服务器和浏览器能够理解的文档(通常是HTML网页)。
- 网络服务器把结果返回到浏览器中。
FastCGI
FastCGI是一个可伸缩地、高速地在HTTP server和动态脚本语言间通信的接口。多数流行的HTTP server都支持FastCGI,包括Apache、Nginx和lighttpd等,同时,FastCGI也被许多脚本语言所支持,其中就有PHP。
FastCGI是从CGI发展改进而来的。传统CGI接口方式的主要缺点是性能很差,因为每次HTTP服务器遇到动态程序时都需要重新启动脚本解析 器来执行解析,然后结果被返回给HTTP服务器。这在处理高并发访问时,几乎是不可用的。FastCGI像是一个常驻(long-live)型的CGI, 它可以一直执行着,只要激活后,不会每次都要花费时间去fork一次(这是CGI最为人诟病的fork-and-execute 模式)。CGI 就是所谓的短生存期应用程序,FastCGI 就是所谓的长生存期应用程序。由于 FastCGI 程序并不需要不断的产生新进程,可以大大降低服务器的压力并且产生较高的应用效率。它的速度效率最少要比CGI 技术提高 5 倍以上。它还支持分布式的运算, 即 FastCGI 程序可以在网站服务器以外的主机上执行并且接受来自其它网站服务器来的请求。
FastCGI是语言无关的、可伸缩架构的CGI开放扩展,其主要行为是将CGI解释器进程保持在内存中并因此获得较高的性能。众所周知,CGI解 释器的反复加载是CGI性能低下的主要原因,如果CGI解释器保持在内存中并接受FastCGI进程管理器调度,则可以提供良好的性能、伸缩性、 Fail-Over特性等等。FastCGI接口方式采用C/S结构,可以将HTTP服务器和脚本解析服务器分开,同时在脚本解析服务器上启动一个或者多 个脚本解析守护进程。当HTTP服务器每次遇到动态程序时,可以将其直接交付给FastCGI进程来执行,然后将得到的结果返回给浏览器。这种方式可以让 HTTP服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能。
FastCGI的工作流程:
- Web Server启动时载入FastCGI进程管理器(PHP-CGI或者PHP-FPM或者spawn-cgi)
- FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待来自Web Server的连接。
- 当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
- FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在Web Server中)的下一个连接。 在CGI模式中,php-cgi在此便退出。
FastCGI 的特点
- 打破传统页面处理技术。传统的页面处理技术,程序必须与 Web 服务器或 Application 服务器处于同一台服务器中。这种历史已经早N年被FastCGI技术所打破,FastCGI技术的应用程序可以被安装在服务器群中的任何一台服务器,而通 过 TCP/IP 协议与 Web 服务器通讯,这样做既适合开发大型分布式 Web 群,也适合高效数据库控制。
- 明确的请求模式。CGI 技术没有一个明确的角色,在 FastCGI 程序中,程序被赋予明确的角色(响应器角色、认证器角色、过滤器角色)。
ISAPI
ISAPI(Internet Server Application Program Interface)是微软提供的一套面向WEB服务的API接口,它能实现CGI提供的全部功能,并在此基础上进行了扩展,如提供了过滤器应用程序接 口。ISAPI应用大多数以DLL动态库的形式使用,可以在被用户请求后执行,在处理完一个用户请求后不会马上消失,而是继续驻留在内存中等待处理别的用 户输入。此外,ISAPI的DLL应用程序和WEB服务器处于同一个进程中,效率要显著高于CGI。(由于微软的排他性,只能运行于windows环境)
ISAPI服务器扩展为使用 Internet 服务器的通用网关接口(CGI) 应用程序提供了另一种选择。与 CGI 应用程序不同,ISA 在 HTTP服务器所在的同一地址空间运行,并且可以访问可由 HTTP 服务器使用的所有资源。ISA 的系统开销比 CGI 应用程序低,因为它们不要求创建其他进程,也不执行需要越过进程边界的通信,而这种通信非常耗时。如果内存被其他进程所需要,扩展和筛选器DLL 都可能被卸载。ISAPI 允许在一个 DLL 中有多个命令,这些命令作为 DLL 中CHttpServer对象的成员函数来实现。CGI 要求每个任务有一个单独的名称和一个到单独的可执行文件的 URL 映射。每个新的 CGI 请求启动一个新进程,而每个不同的请求包含在各自的可执行文件中,这些文件根据每个请求加载和卸载,因此系统开销高于 ISA。
PHP-CGI
PHP-CGI是PHP自带的FastCGI管理器。PHP-CGI的不足:
- php-cgi变更php.ini配置后需重启php-cgi才能让新的php-ini生效,不可以平滑重启
- 直接杀死php-cgi进程php就不能运行了。(PHP-FPM和Spawn-FCGI就没有这个问题,守护进程会平滑从新生成新的子进程。)
Spawn-FCGI
Spawn-FCGI是一个通用的FastCGI管理服务器,它是lighttpd中的一部份,很多人都用Lighttpd的Spawn-FCGI 进行FastCGI模式下的管理工作,不过有不少缺点。而PHP-FPM的出现多少缓解了一些问题,但PHP-FPM有个缺点就是要重新编译,这对于一些 已经运行的环境可能有不小的风险),在php 5.3.3中可以直接使用PHP-FPM了。Spawn-FCGI的代码很少,全部才630行,用c语言编写,最近一次提交是5年前。代码主 页:https://github.com/lighttpd/spawn-fcgi
Spawn-FCGI代码分析如下:
- spawn-fcgi 首先create socket,bind,listen 3步创建服务器socket,(把这个socket叫做 fcgi_fd)
- 用dup2,把fcgi_fd 交换给 FCGI_LISTENSOCK_FILENO (FCGI_LISTENSOCK_FILENO数值上等于0,这是fastcgi协议当中指定用来listen的socket id)
- 执行execl ,replaces the current process image with a new process image. process image 进程在运行空间的代码段
很显然,Spawn-FCGI也是 pre-fork 模型,只是用了上古C语言编写,充满了N多 unix下暗黑编程技巧。
Spawn-FCGI功能很单一:
- 只管fork进程,子进程挂了,主进程仅仅log记录一次,根本不会重新fork。在2009年一段时间内,我曾经用spawn-fcgi部署php-cgi,当跑一段时间就会全挂掉,只能用crontab定时重启spawn-fcgi
- 不负责子进程中的网络IO,把socket放到指定位置就完了,接下来的事情由被spawn的程序处理
Spawn-FCGI是一个很早期的程序,瞻仰一下即可。另外有:1996年的一段代码:http://www.fastcgi.com/om_archive/kit/cgi-fcgi/cgi-fcgi.c,和spawn-fcgi一个风格
PHP-FPM
PHP-FPM是一个PHP FastCGI管理器,是只用于PHP的,可以在 http://php-fpm.org/download下载得到。PHP-FPM其实是PHP源代码的一个补丁,旨在将FastCGI进程管理整合进 PHP包中。必须将它patch到你的PHP源代码中,在编译安装PHP后才可以使用。FPM(FastCGI 进程管理器)用于替换 PHP-CGI 的大部分附加功能,对于高负载网站是非常有用的。它的功能包括:
- 支持平滑停止/启动的高级进程管理功能;
- 可以工作于不同的 uid/gid/chroot 环境下,并监听不同的端口和使用不同的 php.ini 配置文件(可取代 safe_mode 的设置);
- stdout 和 stderr 日志记录;
- 在发生意外情况的时候能够重新启动并缓存被破坏的 opcode;
- 文件上传优化支持;
- “慢日志” – 记录脚本(不仅记录文件名,还记录 PHP backtrace 信息,可以使用 ptrace或者类似工具读取和分析远程进程的运行数据)运行所导致的异常缓慢;
- fastcgi_finish_request() – 特殊功能:用于在请求完成和刷新数据后,继续在后台执行耗时的工作(录入视频转换、统计处理等);
- 动态/静态子进程产生;
- 基本 SAPI 运行状态信息(类似Apache的 mod_status);
- 基于 php.ini 的配置文件。
WSGI
Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口。自从WSGI被开发出 来以后,许多其它语言中也出现了类似接口。WSGI是作为Web服务器与Web应用程序或应用框架之间的一种低级别的接口,以提升可移植Web应用开发的 共同点。WSGI是基于现存的CGI标准而设计的。
WSGI区分为两个部份:一为“服务器”或“网关”,另一为“应用程序”或“应用框架”。在处理一个WSGI请求时,服务器会为应用程序提供环境资 讯及一个回呼函数(Callback Function)。当应用程序完成处理请求后,透过前述的回呼函数,将结果回传给服务器。所谓的 WSGI 中间件同时实现了API的两方,因此可以在WSGI服务和WSGI应用之间起调解作用:从WSGI服务器的角度来说,中间件扮演应用程序,而从应用程序的 角度来说,中间件扮演服务器。“中间件”组件可以执行以下功能:
- 重写环境变量后,根据目标URL,将请求消息路由到不同的应用对象。
- 允许在一个进程中同时运行多个应用程序或应用框架。
- 负载均衡和远程处理,通过在网络上转发请求和响应消息。
- 进行内容后处理,例如应用XSLT样式表。
以前,如何选择合适的Web应用程序框架成为困扰Python初学者的一个问题,这是因为,一般而言,Web应用框架的选择将限制可用的Web服务 器的选择,反之亦然。那时的Python应用程序通常是为CGI,FastCGI,mod_python中的一个而设计,甚至是为特定Web服务器的自定 义的API接口而设计的。WSGI没有官方的实现, 因为WSGI更像一个协议。只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行, 反之亦然。WSGI就是Python的CGI包装,相对于Fastcgi是PHP的CGI包装。
WSGI将 web 组件分为三类: web服务器,web中间件,web应用程序, wsgi基本处理模式为 : WSGI Server -> (WSGI Middleware)* -> WSGI Application 。

1、WSGI Server/gateway
wsgi server可以理解为一个符合wsgi规范的web server,接收request请求,封装一系列环境变量,按照wsgi规范调用注册的wsgi app,最后将response返回给客户端。文字很难解释清楚wsgi server到底是什么东西,以及做些什么事情,最直观的方式还是看wsgi server的实现代码。以python自带的wsgiref为例,wsgiref是按照wsgi规范实现的一个简单wsgi server。它的代码也不复杂。

- 服务器创建socket,监听端口,等待客户端连接。
- 当有请求来时,服务器解析客户端信息放到环境变量environ中,并调用绑定的handler来处理请求。
- handler解析这个http请求,将请求信息例如method,path等放到environ中。
- wsgi handler再将一些服务器端信息也放到environ中,最后服务器信息,客户端信息,本次请求信息全部都保存到了环境变量environ中。
- wsgi handler 调用注册的wsgi app,并将environ和回调函数传给wsgi app
- wsgi app 将reponse header/status/body 回传给wsgi handler
- 最终handler还是通过socket将response信息塞回给客户端。
2、WSGI Application
wsgi application就是一个普通的callable对象,当有请求到来时,wsgi server会调用这个wsgi app。这个对象接收两个参数,通常为environ,start_response。environ就像前面介绍的,可以理解为环境变量,跟一次请求相 关的所有信息都保存在了这个环境变量中,包括服务器信息,客户端信息,请求信息。start_response是一个callback函数,wsgi application通过调用start_response,将response headers/status 返回给wsgi server。此外这个wsgi app会return 一个iterator对象 ,这个iterator就是response body。这么空讲感觉很虚,对着下面这个简单的例子看就明白很多了。
3、WSGI MiddleWare
有些功能可能介于服务器程序和应用程序之间,例如,服务器拿到了客户端请求的URL, 不同的URL需要交由不同的函数处理,这个功能叫做 URL Routing,这个功能就可以放在二者中间实现,这个中间层就是 middleware。middleware对服务器程序和应用是透明的,也就是说,服务器程序以为它就是应用程序,而应用程序以为它就是服务器。这就告 诉我们,middleware需要把自己伪装成一个服务器,接受应用程序,调用它,同时middleware还需要把自己伪装成一个应用程序,传给服务器 程序。
其实无论是服务器程序,middleware 还是应用程序,都在服务端,为客户端提供服务,之所以把他们抽象成不同层,就是为了控制复杂度,使得每一次都不太复杂,各司其职。
参考资料:
- http://blog.csdn.net/on_1y/article/details/18803563
- http://blog.kenshinx.me/blog/wsgi-research/
- http://blog.ez2learn.com/2010/01/27/introduction-to-wsgi/
uWCGI
uWSGI 项目旨在为部署分布式集群的网络应用开发一套完整的解决方案。uWSGI主要面向web及其标准服务,已经成功的应用于多种不同的语言。由于uWSGI的 可扩展架构,它能够被无限制的扩展用来支持更多的平台和语言。目前,你可以使用C,C++和Objective-C来编写插件。项目名称中的“WSGI” 是为了向同名的Python Web标准表示感谢,因为WSGI为该项目开发了第一个插件。uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。 uWSGI,既不用wsgi协议也不用FastCGI协议,而是自创了一个uwsgi的协议,uwsgi协议是一个uWSGI服务器自有的协议,它用于定 义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,它与WSGI相比是两样东西。据说该协议大约是fcgi协议的10倍那么快。
- uWSGI的主要特点如下:
- 超快的性能。
- 低内存占用(实测为apache2的mod_wsgi的一半左右)。
- 多app管理。
- 详尽的日志功能(可以用来分析app性能和瓶颈)。
- 高度可定制(内存大小限制,服务一定次数后重启等)。
另一篇文章用类比的方法帮助理解:http://sunxiunan.com/?p=1778
总结
从CGI、FastCGI、WSGI、uWSGI,它们的主要功能就是CGI的作用—HTTP服务器与你的或其它机器上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上,是从远到近逐步完善的过程。CGI是基础,fastCGI解决了其性能低下、占用系统和内存高的缺点。WSGI相比较于fastCGI,解决了Web应用框架的选择将限制可用的Web服务器的选择这一问题,只要遵照WSGI协议,WSGI应用(Application)都可以在任何服务器(Server)上运行。基于Python的Web项目部署时用wsgi和fastcgi很麻烦,所以像php-cgi一样监听同一端口,进行统一管理和负载平衡的uWSG便应运而生,它相较于fastCGI和WSGI的性能要高,占用的内存要少很多。

















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









