






Lab page table(2020)
之前跟着大佬昨晚page table,有说法是2020年的实验内容更难一点,便翻了翻其他帖子,了解了一下2020年的page table的实验内容.(确实难,看得头大)
参考:博客
后面接着做2021的实验,冲!
A kernel page table per process
The kernel configures the layout of its address space to give itself access to physical memory and various hardware resources at predictable virtual addresses.(内核描述了进入物理存储和各种硬件资源的地址空间),从下图看出有的va到pa属于直接映射,这里简要介绍非直接映射的部分.
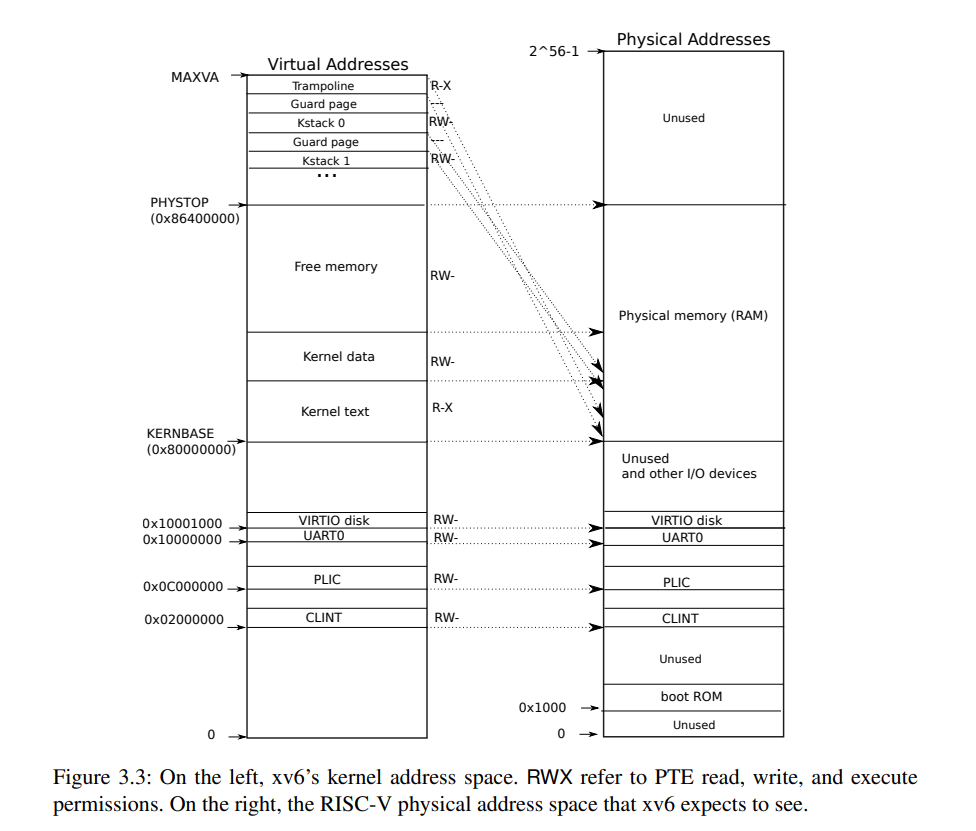
- The trampoline page. It is mapped at the top of the virtual address space; user page tables
have this same mapping.(这个下个实验会讲到) - The kernel stack pages. Each process has its own kernel stack, which is mapped high so
that below it xv6 can leave an unmapped guard page. The guard page’s PTE is invalid.(每个进程都有一个Kernel stack)目前理解是每个线程用来保存关于内核的一些信息,在这个实验中,不再于procinit()方法中为每个进程分配内核栈,而是在每个进程内核页表上分配内核栈.
--------2022.12.17(真看得一头雾水,把后面的实验做了再回来看吧)-----------
Lab traps
关于VScode调试xv6,一开始去大费周章地设置json文件配置调试环境然后又出现各种bug.
在一个终端运行 make qemu-gdb,在另一个终端运行gdb-multiarch kernel/kernel 进入gdb环境再按如下命令配置gdbinit.我使用的vs remote target连接会有冲突,因此注释掉第三行.
set confirm off
set architecture riscv:rv64
@REM target remote 127.0.0.1:25000
symbol-file kernel/kernel
set disassemble-next-line auto
RISC-V assembly
这一块涉及汇编和调试,直接看大佬的视频,这里把大佬笔记里面很有用的一张命令表贴出来
| 命令 | 作用 |
|---|---|
| b | # 打断点 (e.g. b main |
| c | # continue |
| layout split | # view src-code & asm-code |
| ni | # 单步执行汇编(不进函数) |
| si | # 单步执行汇编(有函数则进入函数) |
| n | # 单步执行源码 |
| s | # 单步执行源码 |
| p | |
| p $a0 | # 打印a0寄存器的值 |
| p/x 1536 | # 以16进制的格式打印1536 |
| i r a0 | # info registers a0 |
| x/i 0x630 | # 查看0x630地址处的指令 |
| x/g 0x80000000 | # 查看0x80000000地址处的值(g表示值的长度有64位) |
一些qemu快捷键
实验中的问题
-
Which registers contain arguments to functions? For example, which register holds 13 in main’s call to printf?
A:a0-a7保留了函数的参数,从汇编文件中可以从命令行li a2 13(li命令表示加载立即数)得出a2寄存器持有13立即数; -
Where is the call to function f in the assembly code for main? Where is the call to g? (Hint: the compiler may inline functions.)
A:两个函数被内联优化了,从汇编代码中可以看出没有调用f和g的过程,g被内联到f中,f再被内联到main中; -
At what address is the function printf located?
A:根据汇编中的注释知道printf()函数地址在0x630. -
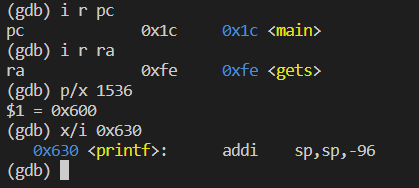
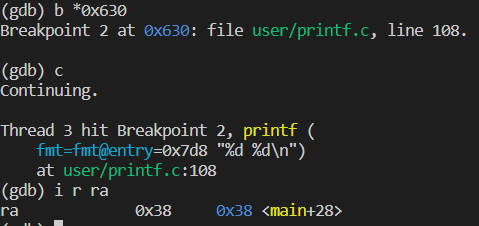
What value is in the register ra just after the jalr to printf in main?
A:由下面两幅图说明,0x630处为printf函数的入口地址,在该处打断点,由第二幅图可知,ra寄存器的值是0x38.
后面一个部分,运行下列代码
unsigned int i = 0x00646c72;
printf("H%x Wo%s", 57616, &i);
问输出是什么?A:He110 world.i的地址表示中0x64为d,0x6c为l,0x72为r.由于RISC-V为小端序,因此如果选择大端序的指令集,把i改成0x00726c64即可,57616无需改变.
再运行下列代码:
printf("x=%d y=%d", 3);
问y=会输出什么值,结果是运行报错,但如果要输出的话,看汇编得知寄存器a1存放参数值为3,则应将由之前随机的代码决定的a2的值赋给a2.
Backtrace
这个实验大致是将系统调用过的函数记录下来,在printf.c文件里添加一个backtrace()函数,打印调用信息.给出r_fp()函数用来读取fp寄存器中的值.
结合MIT课堂的笔记和大佬的笔记,主要有用的两张图如下:
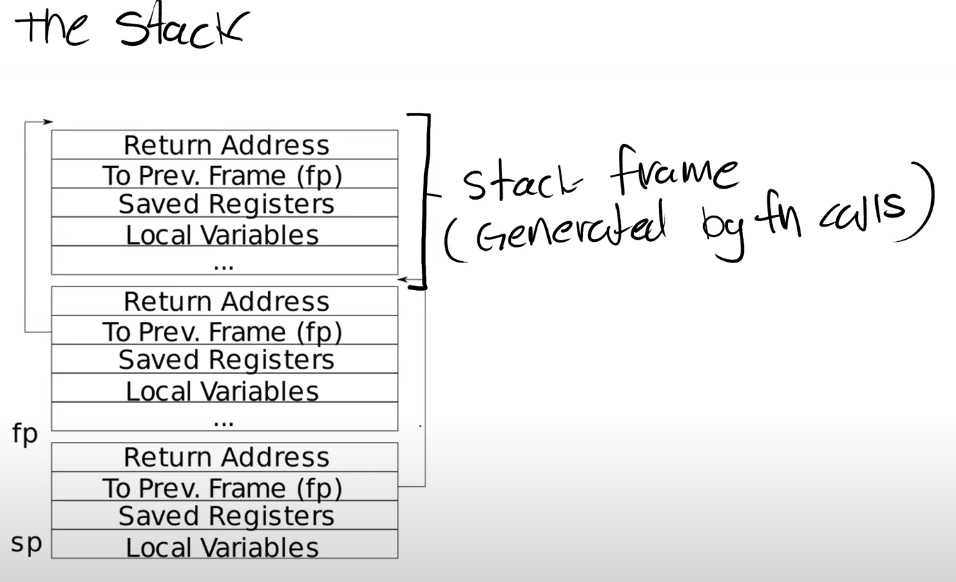
每次调用函数会创建stack frame从高到底;用r_fp()函数拿到fp,然后fp-8(偏移量)的地址是返回地址,fp-16得到上一个栈帧的指针.
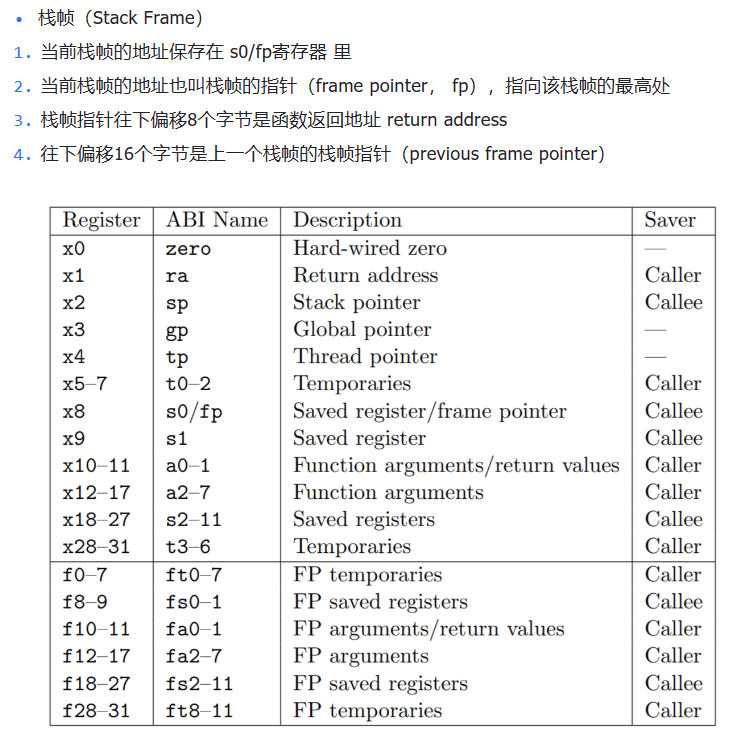
看了一些的帖子的写法大差不差,但是自己写总是会陷入死循环,仔细检查自己的代码及逻辑理解:fp是一个存放地址的寄存器,列出比较关键的两句代码:
printf("%p\n", *(uint64*)(fp - 8));//先转换成指针再引用得到地址
fp = *(uint64*)(fp - 16);//这里一开始写成fp=fp-16错了,fp-16这个地址里存的才是上一个函数的栈帧的地址,而不是上一个函数的栈帧的地址就是fp-16!
对栈的递归查询,实验中的说明:Xv6 allocates one page for each stack in the xv6 kernel at PAGE-aligned address. You can compute the top and bottom address of the stack page by using PGROUNDDOWN(fp) and PGROUNDUP(fp).xv6在内核中给每个栈分配一页,你可以通过UP和DOWN两个函数计算栈帧的顶部和底部的地址范围,从而确定递归的截止条件,即fp指针应在DOWN和UP之间.
Alarm
主要是实现两个函数,先是在proc结构体中添加字段,统计自从上次系统调用之后经过了多少ticks.
跟着大佬的视频把课件过了一遍然后copy了代码~
大佬的中断跳转之前保存寄存器信息略显麻烦,就参考了知乎这篇帖子,用一个指针保留了历史信息,等到sigreturn的时候再恢复寄存器内容,很丝滑只能说~
个人感觉这里的trap机制就和微机原理课上学的中断差不多,当触发中断时,要先保存现场,再跳转查询中断向量,执行中断之后再返回,恢复现场.
Lab lazy page allocation(2020)
2020年才有的一个实验,主要涉及内存管理中的懒分配.xv6中解释如下:lazy allocation主要分为两部分:
First, when an application calls sbrk, the kernel grows the address space, but marks the new
addresses as not valid in the page table. Second, on a page fault on one of those new addresses, the kernel allocates physical memory and maps it into the page table.
具体的工作原理看课件对应章节就行,比较关键的是第二步,当应用程序使用到一个大于p->sz又小于p->sz+n的地址时,触发page fault的的handler参数中,通过kalloc函数分配一个内存page,初始化page内容为0,将这个page映射到user page table中,最后重新执行指令.
Eliminate allocation from sbrk()
将sbrk()内存分配函数中删除分配内存部分,但保留p->sz+n的操作,则以运行echo hi命令为例,page fault报错会报not mapped错,如下:
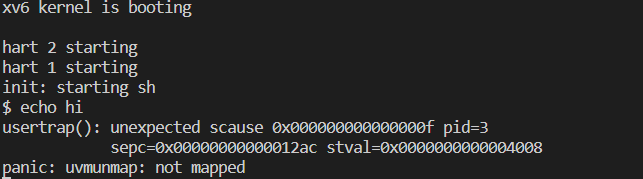
课件中解释如下:
之所以会得到一个page fault是因为,在Shell中执行程序,Shell会先fork一个子进程,子进程会通过exec执行echo.在这个过程中,Shell会申请一些内存,所以Shell会调用sys_sbrk,然后就出错了.
Lazy allocation
这一块就是在上述将内存分配步骤省去之后,再根据page fault报错修改trap.c中的代码,使得报错位置的地址空间被分配内存,再返回到用户空间使得程序成功运行.结果使得echo hi成功运行.
课件中有一个案例实现了echo hi中的lazy allocation.跟着敲一遍这一块应该就算结束.但是这个初步代码还有很多问题,要进一步修改才能通过下一部分的tests.
Lazytests and Usertests
r_stval() returns the RISC-V stval register, which contains the virtual address that caused the page fault.
进一步改进lazy allocation代码解决下列问题:
- sbrk()传入负数问题:sbrk()在扩张内存时使用lazy策略,但在释放内存时是立即执行,因此在sbrk()函数那里根据n的正负判断修改执行即可.
- Kill a process if it page-faults on a virtual memory address higher than any allocated with sbrk().这里用va判断不能大于p->sz,否则是一个非法的虚拟地址,设置p->killed = 1.
- Handle the parent-to-child memory copy in fork() correctly.处理fork()过程中内存复制中的问题,将uvmcopy()中的两个panic修改即可.
- Handle out-of-memory correctly: if kalloc() fails in the page fault handler, kill the current process.这里使用kalloc()的一个非空判断已经解决.
- Handle faults on the invalid page below the user stack.这里va不能进入保护页的位置,因此不能小于p->trapframe->sp.
结合课件中的用户空间地址分布理解上述操作.
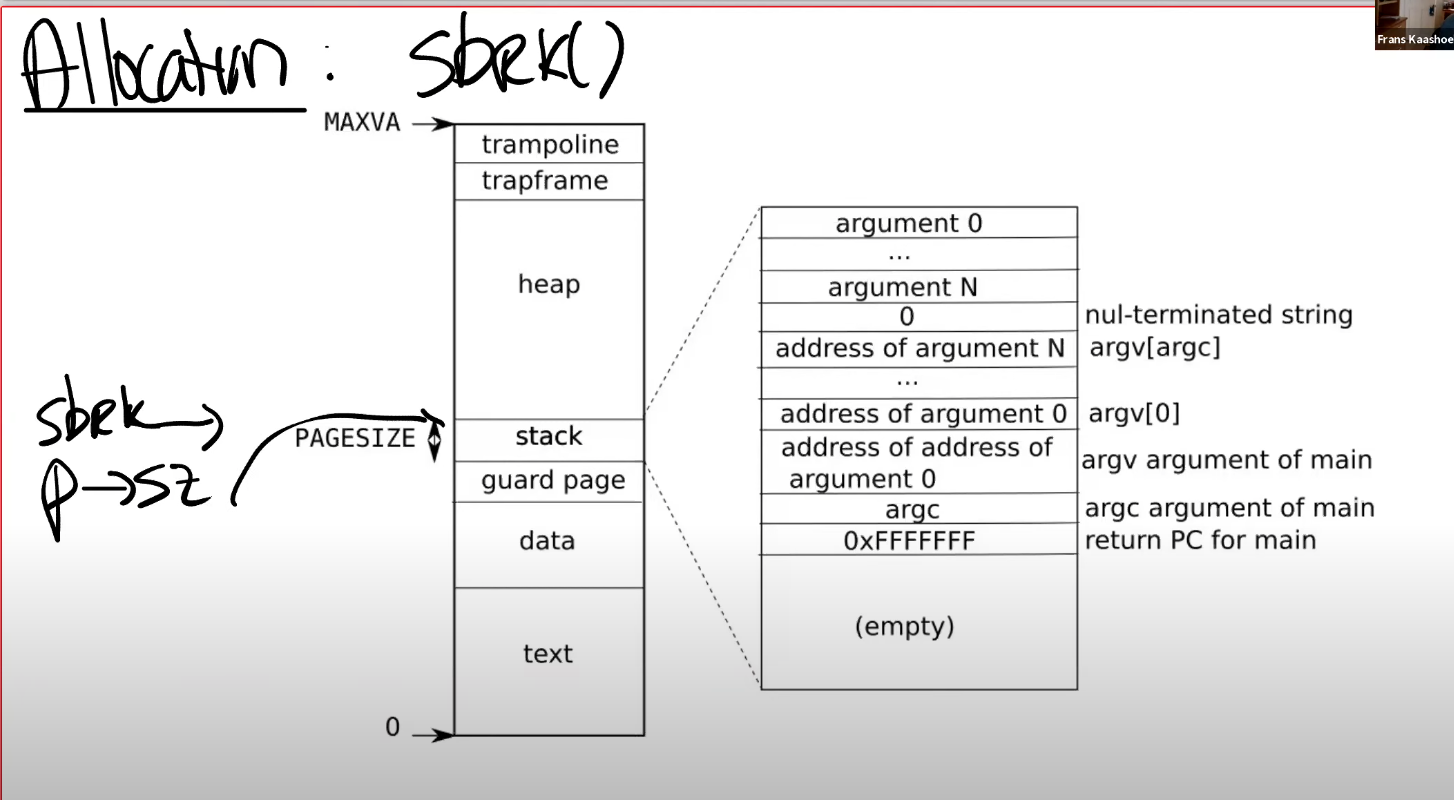
- Handle the case in which a process passes a valid address from sbrk() to a system call such as read or write, but the memory for that address has not yet been allocated.这一块最难完善,尤其是在usertests中一些用例过不了,不是很理解,就看了其他大佬的帖子,跟着视频改了一下.大致意思是sbrkarg会涉及到内核与用户地址之间的内存拷贝,在拷贝之前需要完成内存的分配(from大佬的帖子).因此在walkaddr函数里要做一个懒分配的判断.
Lab Copy-on-Write Fork
我们创建子进程时,与其创建,分配并拷贝内容到新的物理内存,其实我们可以直接共享父进程的物理内存page.The goal of copy-on-write (COW) fork() is to defer allocating and copying physical memory pages for the child until the copies are actually needed, if ever.这个想法和懒分配类似~COW fork() marks all the user PTEs in both parent and child as not writable.(将父进程和子进程的页表标记为只读,当其中任一个进程要写page的时候,触发一个page fault.The kernel page-fault handler detects this case, allocates a page of physical memory for the faulting process, copies the original page into the new page, and modifies the relevant PTE in the faulting process to refer to the new page, this time with the PTE marked writeable. When the page fault handler returns, the user process will be able to write its copy of the page.(具体步骤就是给进程分配内存,并将原来的内存页复制到新的内存页,修改页表指向新的内存页,并将PTE设置可写.然后当page fault句柄返回时,用户进程就可以写复制的页表了).
实验指导给出了实现的几个步骤.其中几个比较关键的设计,在课件中也有学生提问提到:
如何判断page fault是一个COW fault?
当内核在管理这些page table时,对于copy-on-write相关的page,内核可以设置相应的bit位,这样当发生page fault时,我们可以发现如果copy-on-write bit位设置了,我们就可以执行相应的操作了。否则的话,比如说lazy allocation,我们就做一些其他的处理操作
但是对于这里的物理内存page,现在有多个用户进程或者说多个地址空间都指向了相同的物理内存page,举个例子,当父进程退出时我们需要更加的小心,因为我们要判断是否能立即释放相应的物理page。如果有子进程还在使用这些物理page,而内核又释放了这些物理page,我们将会出问题。那么现在释放内存page的依据是什么呢?
我们需要对于每一个物理内存page的引用进行计数,当我们释放虚拟page时,我们将物理内存page的引用数减1,如果引用数等于0,那么我们就能释放物理内存page。所以在copy-on-write lab中,你们需要引入一些额外的数据结构或者元数据信息来完成引用计数。
根据实验提示, Set a page’s reference count to one when kalloc() allocates it. Increment a page’s reference count when fork causes a child to share the page, and decrement a page’s count each time any process drops the page from its page table. kfree() should only place a page back on the free list if its reference count is zero. 在kalloc.c文件中设计一个数组,数组长度为所有可能的page数量,这里对根据pa映射到对应的数组下标不是很会写,直接copy来自这篇帖子大佬的kalloc.c中的代码.
最后关于kernel page通过copyout()复制到user page,page到用户态空间要求都是可读写的因此也要做相应page fault跳转.
这里贴一下判断是否为写时复制以及执行的两个函数:
//COW judgement
int judgecow(pagetable_t pagetable,uint64 va){
pte_t *pte = walk(pagetable,va,0);
if(pte == 0 || ((*pte) & PTE_V) == 0 || ((*pte) & PTE_U)==0){
printf("usertrap: pte not exist\n");
return -1;
}
return ((*pte)&PTE_RSW)!=0;
}
//COW
int cow(pagetable_t pagetable,uint64 va){
pte_t *pte;
uint64 pa;
uint flags;
char* mem;
pa = walkaddr(pagetable, va);
pte = walk(pagetable, va, 0);
if((mem = kalloc()) == 0){
printf("usertrap(): memory alloc fault\n");
return -1;
}
memmove(mem, (char*)pa, PGSIZE);
//set the new flags
flags = PTE_FLAGS(*pte);
flags|=PTE_W;
flags&=~PTE_RSW;
if(mappages(pagetable, va, PGSIZE, (uint64)mem, flags) != 0){
kfree(mem);
return -1;
}
kfree((void*) pa);
return 0;
}
最后在执行test时会报mappages:remap是因为触发COW的va已经分配了pte只需修改判定语句如下:
if(*pte & PTE_V&&((*pte&PTE_RSW)==0))
panic("mappages: remap");
后续copyout()的修改只需添加如下语句:
if(va0 >= MAXVA){
//printf("copyout(): va is greater than MAXVA\n");
return -1;
}
if(judgecow(pagetable,va0)==1){
if(cow(pagetable,va0)!=0){
printf("cow in copyout() failed!\n");
return -1;
}
}
后面如果在test出现一些panic大多和虚拟地址越界有关,参考大佬的帖子修改一下最终通过测试.
关于大佬帖子里的物理内存引用数的修改,最好加个锁:
void
addref(void *pa){
acquire(&kmem.lock);
reference[getrefindex(pa)]++;
acquire(&kmem.lock);
}
void
subref(void *pa){
int index = getrefindex(pa);
if(reference[index] == 0)
return;
acquire(&kmem.lock);
reference[index]--;
release(&kmem.lock);
}
刚好下一个实验做多线程,关于xv6处理并发问题会有进一步研究,冲~
Lab Multithreading
先把指导书相关章节看一下,复习一下几个概念:
竞态条件
(A race condition is a situation in which a memory location is accessed concurrently, and at least one access is a write.)多个线程竞争同一个资源,对访问顺序敏感(例如test and set)
死锁
(Suppose thread T1 executes code path 1 and acquires lock A, and thread T2 executes code path 2 and acquires lock B. Next T1 will try to acquire lock B, and T2 will try to acquire lock A. Both acquires will block indefinitely, because in both cases the other thread holds the needed lock, and won’t release it until its acquire returns.)两个线程互相持有对方需要的锁造成同时堵塞的僵局.
死锁的必要条件
- 互斥条件:一个资源每次只能被一个进程使用
- 不可剥夺条件:在进程所获得的资源未使用完毕之前,不可被其他进程获得,只能由进程自己释放
- 请求与保持条件:进程保持至少一个资源,但又提出了新的资源请求,而该资源被其他进程持有,此时请求被阻塞,但对自己已获得的资源保持不放
- 循环等待条件:存在循环等待链,链中的每一个进程已获得的资源同时被下一个进程请求
解决死锁的办法
- 预防死锁:例如"先释放后申请"
- 避免死锁:例如线程按照一定的顺序加锁、获取锁时加上一定时限,超时则放弃对锁的请求
自旋锁:循环判断对象的锁是否被持有
while(1){ if(l->locked==0){ //当锁没有被持有 l->locked = 1; return; } }
线程
我们认为线程就是单个串行执行代码的单元,它只占用一个CPU并且以普通的方式一个接一个的执行指令.线程状态包括三个部分:
- 程序计数器,表示当前线程执行指令的位置
- 保存变量的寄存器
- 程序的Stack:记录函数的调用,反应当前程序的执行点
Uthread: switching between threads
第一块实验实现一个用户态的线程切换,在uthread.c函数中写好了示例,补全创建线程以及线程调度的代码,同时在汇编文件中添加thread_switch代码,实现寄存器内容的存储与恢复.提示了可以在thread结构体中添加寄存器内容.
thread_create()函数参数传入了一个函数指针,实验指导中提示One goal is ensure that when thread_schedule() runs a given thread for the first time, the thread executes the function passed to thread_create(), on its own stack.意思是要让这个传入的函数运行在对应thread自己的栈上(这一步能理解但是不会写~)其实只要添加如下语句即可.
t->ra = (uint64)func;
t->sp = (uint64)(t->stack)+STACK_SIZE;
然后switch函数照着课件里的汇编写就行,我直接把thread改成如下:
struct thread {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
};
//然后修改switch函数声明的参数格式
extern void thread_switch(struct thread*, struct thread*);
就可以实现最终的输出效果.
Using threads
这个实验大致是在Linux实验环境下,手册给出了ph.c文件中一个hashtable的实现,但没有考虑多线程下的安全性.运行./ph 1的时候没有key会发生missing,但是用多线程时会发生key missing,因此要修改put()和insert()函数,通过加锁的机制实现线程的安全.同时进阶版不仅要考虑安全性(保证通过ph_safe)还要求考虑锁的效率,争取通过ph_fast.
基于本人对锁粗浅的理解直接在get()函数中拿到key的操作下套了两个锁如下:
if(e){
// update the existing key.
pthread_mutex_lock(&lock); // acquire lock
e->value = value;
pthread_mutex_unlock(&lock); // release lock
} else {
// the new is new.
pthread_mutex_lock(&lock);
insert(key, value, &table[i], table[i]);
pthread_mutex_unlock(&lock);
}
实验也通过了ph的两个测试,可能是我的云服务器太垃了运行要100多秒.

Barrier
旨在通过类似于xv6中的sleep和wakeup机制的条件量实现一个barrier.设定n个线程,每个线程执行一个循环(见thread()),每次迭代都先执行barrier(),然后睡眠一段随即设定的时间.通过barrier()的阻塞机制,使得每个线程在所有其他线程都调用barrier()之前都处于等待状态,才能保证assert()成功.
看了手册和讲义感觉懂了但是不好下手~然后看了大佬视频条件变量的视频茅塞顿开.理解了wait和broadcast两个函数的用法所在.实验的两个issues第一个很好理解,第二个要想一想:
You have to handle the case in which one thread races around the loop before the others have exited the barrier. In particular, you are re-using the bstate.nthread variable from one round to the next. Make sure that a thread that leaves the barrier and races around the loop doesn’t increase bstate.nthread while a previous round is still using it.我的理解是当第n轮的nthread正在退出barrier()函数时,已经退出的thread已经开始下一轮的barrier(),因此不能在barrier()函数上来就nthread++,否则会导致混乱.我的解决方法是直接改barrier传参barrier(i),然后再barrier里面执行while(i!=bstate.round)的spinlock,不过这段可有可无示例照样通过好像~
static void barrier(){
pthread_mutex_lock(&bstate.barrier_mutex);
bstate.nthread++;
if(bstate.nthread<nthread){
pthread_cond_wait(&(bstate.barrier_cond),&(bstate.barrier_mutex));
}else{
pthread_cond_broadcast(&bstate.barrier_cond);
bstate.nthread = 0;
bstate.round++;
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}















 9802
9802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









