







-
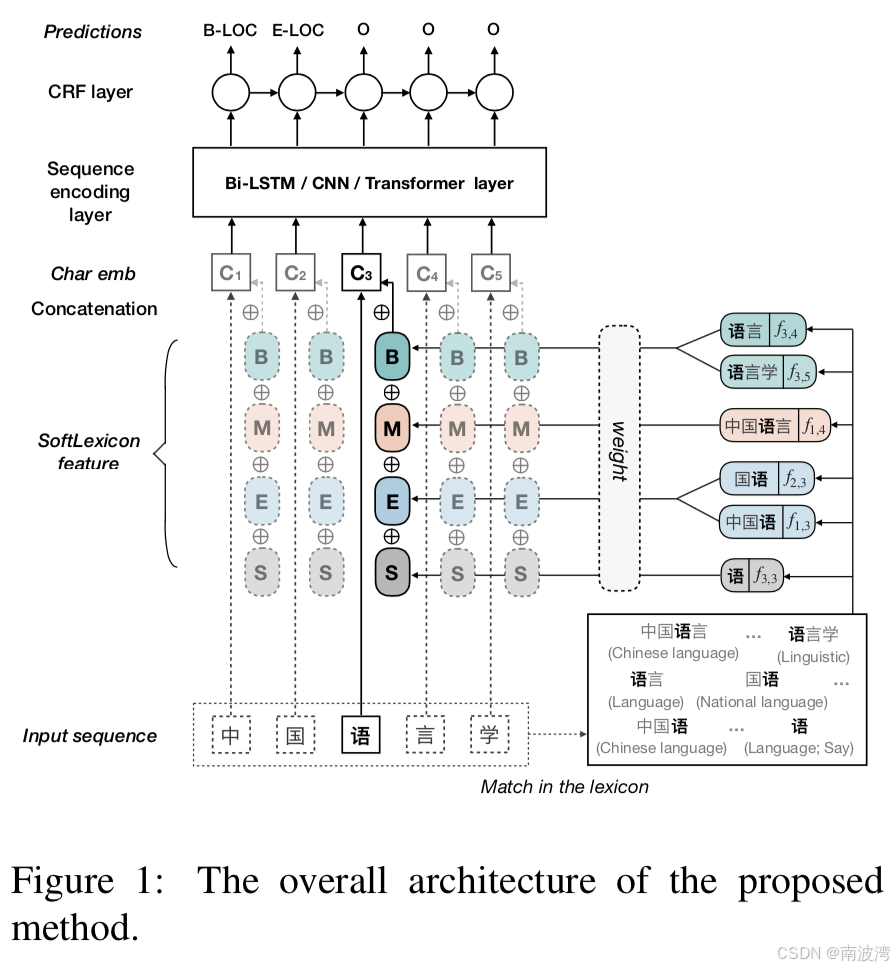
《Simplify the Usage of Lexicon in Chinese NER》论文的内容相对比较简单,在该论文中,作者首先讨论了一下经典的lattice,并讲明了lattice的优点和缺点,然后提出了使用词向量进行NER增强方法。论文中将词向量特征拼接在字符特征中,然后送入模型进行训练,整体模型结构如下。
-
作者首先将得到的字符 c i c_i ci转换成对应的字符向量 x i c x_i^c xic:
x i c = e c ( c i ) {x_i^c = e^c(c_i)} xic=ec(ci)
其中 e c {e^c} ec 表示用于字符嵌入的查找表。 同时作者还考虑了字符二元组的表示:
x i c = [ e c ( c i ) ; e b ( c i , c i + 1 ) ] {x_i^c = [e^c(c_i); e^b(c_i, c_{i+1})]} xic=[ec(ci);eb(ci,ci+1)]
-
然后作者讨论了 Softword 的不足。在 Softword 中,作者为每一个字符添加四类标签,B M E S,用于标记字符是开头、中间、结尾或者单个词组。然后将字符的标签 B M E S 转成 multi-hot 向量,再经过 embedding 得到特征,并拼接到字符特征上。但是这种方法的缺点在于BMES的标签解读存在歧义,例如下图中可以把 中(B)山(M)西(E) 错误的解读出词组 “中山西”。
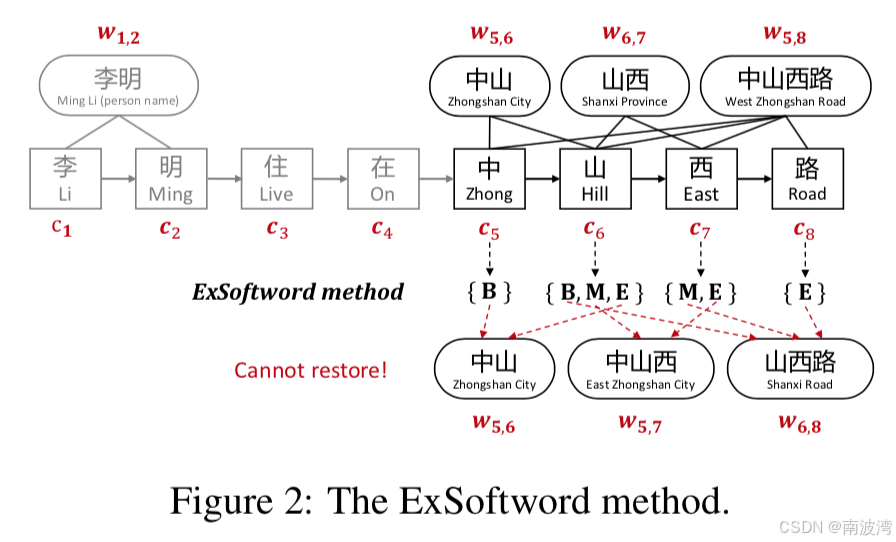
-
作者在 Softword 的基础上进行扩展,提出了 SoftLexicon,将B M E S 四个标签转化成四个集合,每个集合里面存放对应标签的词组。例如“山”字的B集合中存档以山开头的词语【山西】,而M集合中存放包含山字的词语【中山西路】。然后再对每一个单词进行 word embedding 编码,然后进行加权平均。
v s ( S ) = 4 Z ∑ w ∈ S z ( w ) e w ( w ) {v^s(S) = \frac{4}{Z} \sum_{w \in S} z(w)e^w(w)} vs(S)=Z4∑w∈Sz(w)ew(w)
Z = ∑ w ∈ B ∪ M ∪ E ∪ S z ( w ) {Z=\sum_{w \in B \cup M \cup E \cup S} z(w)} Z=∑w∈B∪M∪E∪Sz(w)
这里的权重 z ( w ) {z(w)} z(w) 表示单词w在统计数据中出现的 频次。作者没有使用注意力,而是使用了事先计算好的静态词频,目的是为了提升计算效率(但是也有很多复现中,直接使用self-attention取代了静态词频)。Z 表示所有词组的频次加总,公式实际上是对所有的单词进行了权重归一化。此外,作者特意强调了,如果一个单词被另一个覆盖,则这个单词的频率不增加,也就是分词过程使用最长词语匹配。
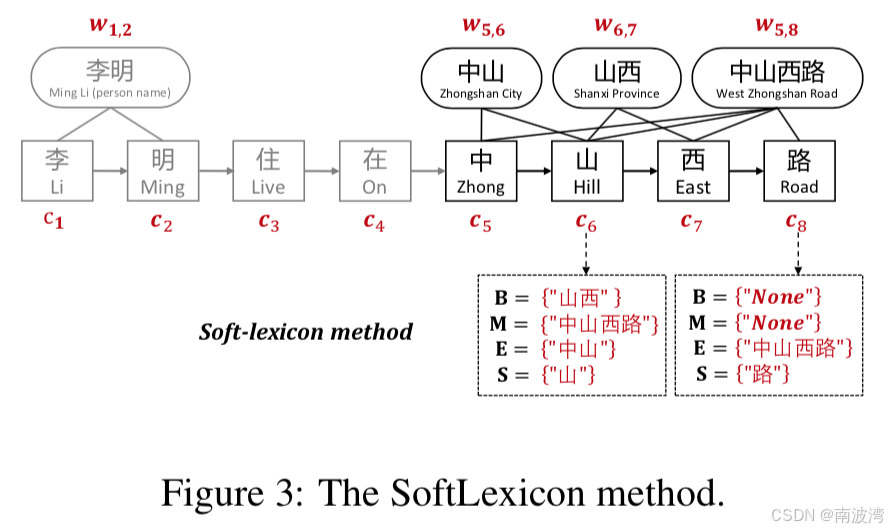
然后再将所得的词向量拼接给字向量。e s ( B , M , E , S ) = [ v s ( B ) ; v s ( M ) ; v s ( E ) ; v s ( S ) ] {e^s(B,M,E,S) = [v^s(B);v^s(M);v^s(E);v^s(S)]} es(B,M,E,S)=[vs(B);vs(M);vs(E);vs(S)]
x c ← [ x c ; e s ( B , M , E , S ) ] {x^c \gets [x^c;e^s(B,M,E,S)] } xc←[xc;es(B,M,E,S)]
公式中, v s v^s vs 表示上面的加权函数,注意这里在计算时,对每一个类别是分开计算的,但是计算中所除的Z是按照全部统计的。接下来就可以将拼接后所得的向量 x c x^c xc 送入LSTM或者CNN等网络进行模型训练。


















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








