







最近在做模型的时候,需要用到CRF,但是Tensorflow2里面没有相应的Layer可以使用,只能手写,所以需要先搞清楚CRF的原理。来来回回看了很多博客,发现大家写的都有些问题,比如很多文章联合概率,上来直接相加,而不是相乘,看的很迷糊。还有些文章没有考虑状态转移条件,只有分数。参考了很多文章以及CRF的论文后,决定自己总结一下,过程中有不对的地方,欢迎指正。
CRF 在 seq2seq 中的本质,其实是希望,数据在输出的过程中,不单单考虑本次的输入,同时考虑上一步的输出。例如在BIO实体标注中,输入一个字,这个字的输出是B(实体开头)、I(实体中间)、O(其他),除了要考虑当前输入的字,还要考虑上一个字的词性。下图中,输出label为 “4”,同时考虑了输入的数据 “1”,和上一步的输出数据 “4”。
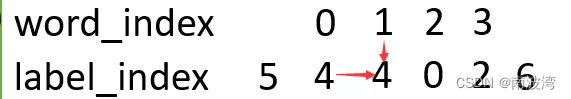
我们将 输入 1 → 输出 4 \color{red}{输入1 \rightarrow 输出4} 输入1→输出4的概率可能性,称为 “发射分数”,暂且记为 μ i , y i \color{red}{\mu _{i,y_i}} μi,yi,意思是第 i 个位置预测是 y i y_i yi 的可能性。将 上一步 4 → 当前步 4 \color{red}{上一步4 \rightarrow 当前步4} 上一步4→当前步4的概率可能性,称为 “转移分数”,暂且记为 λ y i − 1 , y i \color{red}{\lambda _{y_{i-1},y_i}} λyi−1,yi,意思是从位置 i-1 的状态 y i − 1 y_{i-1} yi−1,转移到位置 i 的状态 y i y_i yi 的概率可能性。那么,知道当前位置的输入 x i x_i xi,预测当前位置的输出为 y i y_i yi 的概率可以表示为 P ( y i ∣ x i ) = λ y i − 1 , y i ∗ μ i , y i \color{blue}{P(y_i|x_i) = \lambda _{y_{i-1},y_i} * \mu _{i,y_i}} P(yi∣xi)=λyi−1,yi∗μi,yi,也就是两者的联合概率。
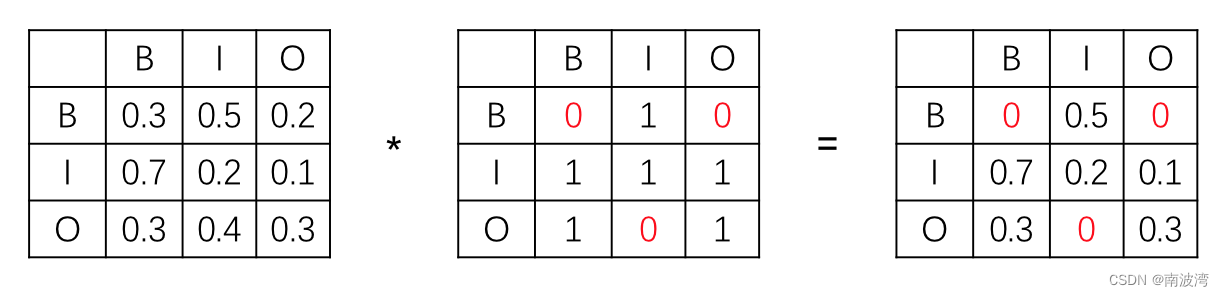
实际情况中,转移分数的分布并不是两两结合的,有些状态下并不能够互相转换。例如在BIO中,B不能转化成B,O不能直接转化成I等。所以我们需要在转移矩阵的前面,再乘以一个固定的条件矩阵,以满足某些情况下转移概率永远为0。转移分数的条件矩阵,使用 t k t_k tk 来表示,发射分数的条件矩阵,使用 s l s_l sl 来表示。(很多情况下,一般不设置 s l s_l sl,猜测情况应该是因为数据的长度不唯一,所以无法确定某个位置会不会出现某种情况,干脆就不设置了。)此时,公式可以进一步调整为 P ( y i ∣ x i ) = t k ∗ λ y i − 1 , y i ∗ s l ∗ μ i , y i \color{blue}{P(y_i|x_i) = t_k * \lambda _{y_{i-1},y_i} * s_l * \mu _{i,y_i}} P(yi∣xi)=tk∗λyi−1,yi∗sl∗μi,yi,记做 p i \color{red}{p_i} pi,这里的下标 k,l 分别代表 y i y_i yi 情况下 t,s 对应的限制条件。且实际机器学习中,t 和 s 应该是固定的,不参与学习过程。
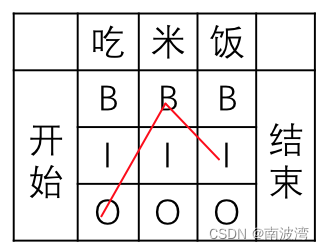
每个 Token 的概率知道了,那么一个序列的概率为 P ( Y ∣ X ) = P ( y 1 , y 2 . . . y n ∣ x 1 , x 2 . . . x n ) = p 1 ∗ p 2 ∗ . . . ∗ p n \color{blue}{P(Y|X) = P(y_1,y_2...y_n|x_1,x_2...x_n) = p_1 * p_2 * ... * p_n} P(Y∣X)=P(y1,y2...yn∣x1,x2...xn)=p1∗p2∗...∗pn。对于此处的 P(Y|X) 我们并不关心其实际的概率大小,而且是考虑其相对大小,也就需要去除量纲,使用 softmax。我们将正确路径记为 Y t r u e = e t k ∗ λ y i − 1 , y i ∗ e s l ∗ μ i , y i = e x p ( t k ∗ λ y i − 1 , y i + s l ∗ μ i , y i ) \color{blue}{Y_{true} = e^{t_k * \lambda _{y_{i-1},y_i}} * e^{s_l * \mu _{i,y_i}} = exp(t_k * \lambda _{y_{i-1},y_i} + s_l * \mu _{i,y_i})} Ytrue=etk∗λyi−1,yi∗esl∗μi,yi=exp(tk∗λyi−1,yi+sl∗μi,yi)(解决了在训练过程中,转移分数有可能是负数的情况。),所有的可能性分别记为 Y 1 . . . Y n Y_1 ... Y_n Y1...Yn。仍然以BIO为例,我们输入 “吃米饭”,期望输出结果为 “OBI”,但是实际输出有 3*3 = 9 种可能性。同时我们在状态上补充了 开始 和 结束 两种状态,以满足在运算时 y i − 1 y_{i-1} yi−1 的情况。此时对于预测正确的向量,就可以转换成 P t r u e = Y t r u e ∑ Y n = 1 Z ∗ e x p ( ∑ λ k ∗ t k + ∑ μ l ∗ s l ) \color{blue}{P_{true} = \frac {Y_{true}} {\sum Y_n} = \frac{1}{Z} * exp( \sum \lambda_k * t_k + \sum \mu_l * s_l)} Ptrue=∑YnYtrue=Z1∗exp(∑λk∗tk+∑μl∗sl),其中 Z = ∑ e x p ( ∑ λ k ∗ t k + ∑ μ l ∗ s l ) \color{blue}{Z = \sum exp( \sum \lambda_k * t_k + \sum \mu_l * s_l)} Z=∑exp(∑λk∗tk+∑μl∗sl),即所有可能性的加总。
我们的训练目标是,使得 P t r u e P_{true} Ptrue 最大,其最大可能性为1。则通过取 -log 就可以得到我们的损失函数 L o s s = − l o g ( P t r u e ) \color{blue}{Loss = -log(P_{true})} Loss=−log(Ptrue),将上述 P t r u e P_{true} Ptrue 代入即可,剩下的就交给梯度下降了。















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









