







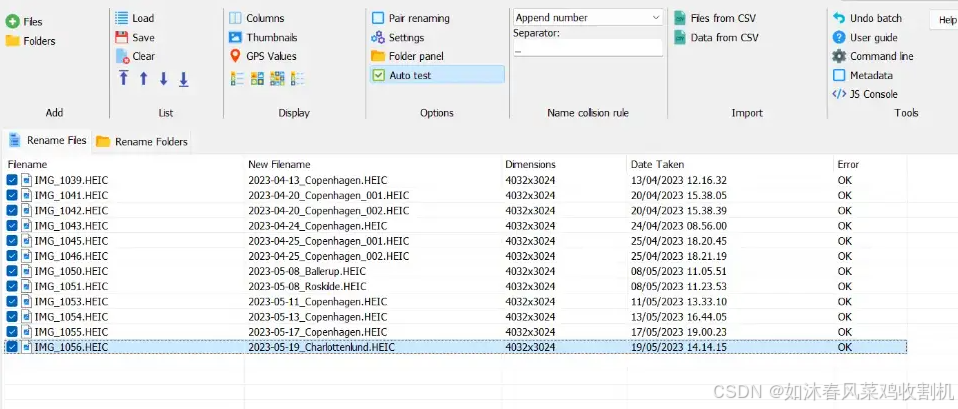
在一家大型企业的文档管理部门,存储着海量的 PDF 文件,这些文件涵盖了各种类型的文档,如报告、合同、技术文档、会议纪要等。然而,现有的文件命名方式混乱无序,文件名称通常是一些无意义的编号或随机字符串,给文件的查找、检索和管理带来了极大的困难。为了提高文档管理的效率,决定开发一个自动化工具,能够将 PDF 文件按页拆分,并根据 PDF 页面中的内容对拆分后的文件进行有意义的重命名。
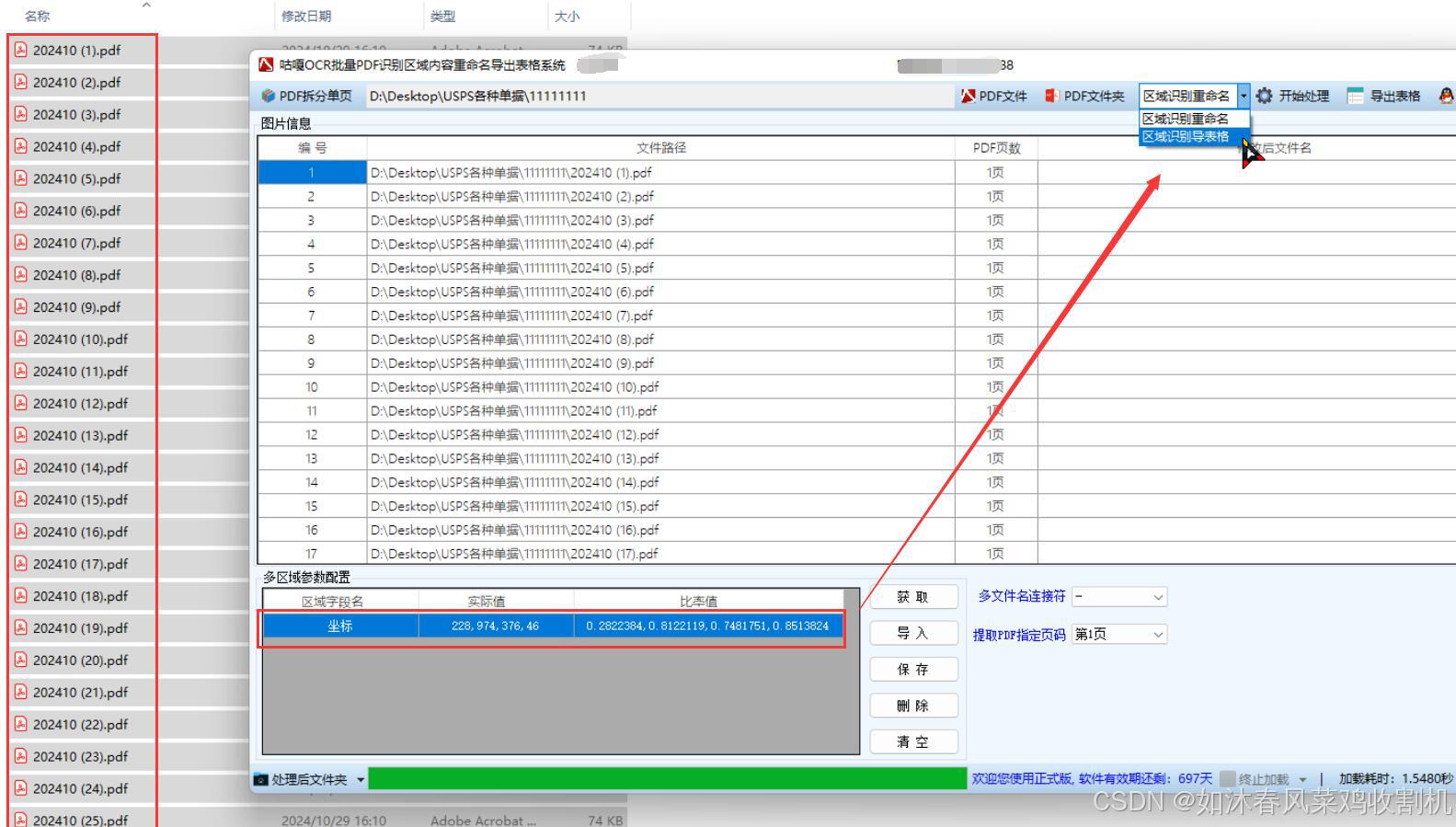
以下是使用 Java 和飞桨(PaddleOCR)实现批量将 PDF 按页拆分并根据 PDF 中的文字对文件进行批量重命名的完整步骤:
一、整体思路:
- 使用 Java 程序遍历目录下的 PDF 文件。
- 使用 Apache PDFBox 库将 PDF 文件按页拆分成多个单独的 PDF 文件。
- 使用飞桨的 OCR 功能对拆分后的 PDF 页面内容进行识别。
- 根据识别出的文字内容对拆分后的 PDF 文件进行重命名。
二、环境搭建
1. 安装 Apache PDFBox 库:
在你的 pom.xml 文件中添加 Apache PDFBox 依赖:
xml
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.27</version>
</dependency>
2. 安装飞桨和 PaddleOCR:
- 首先,安装飞桨库:
bash
pip install paddlepaddle - 然后,安装 PaddleOCR:
bash
pip install paddleocr
三、Java 代码实现
1. 导入所需的包:
java
import org.apac 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









