







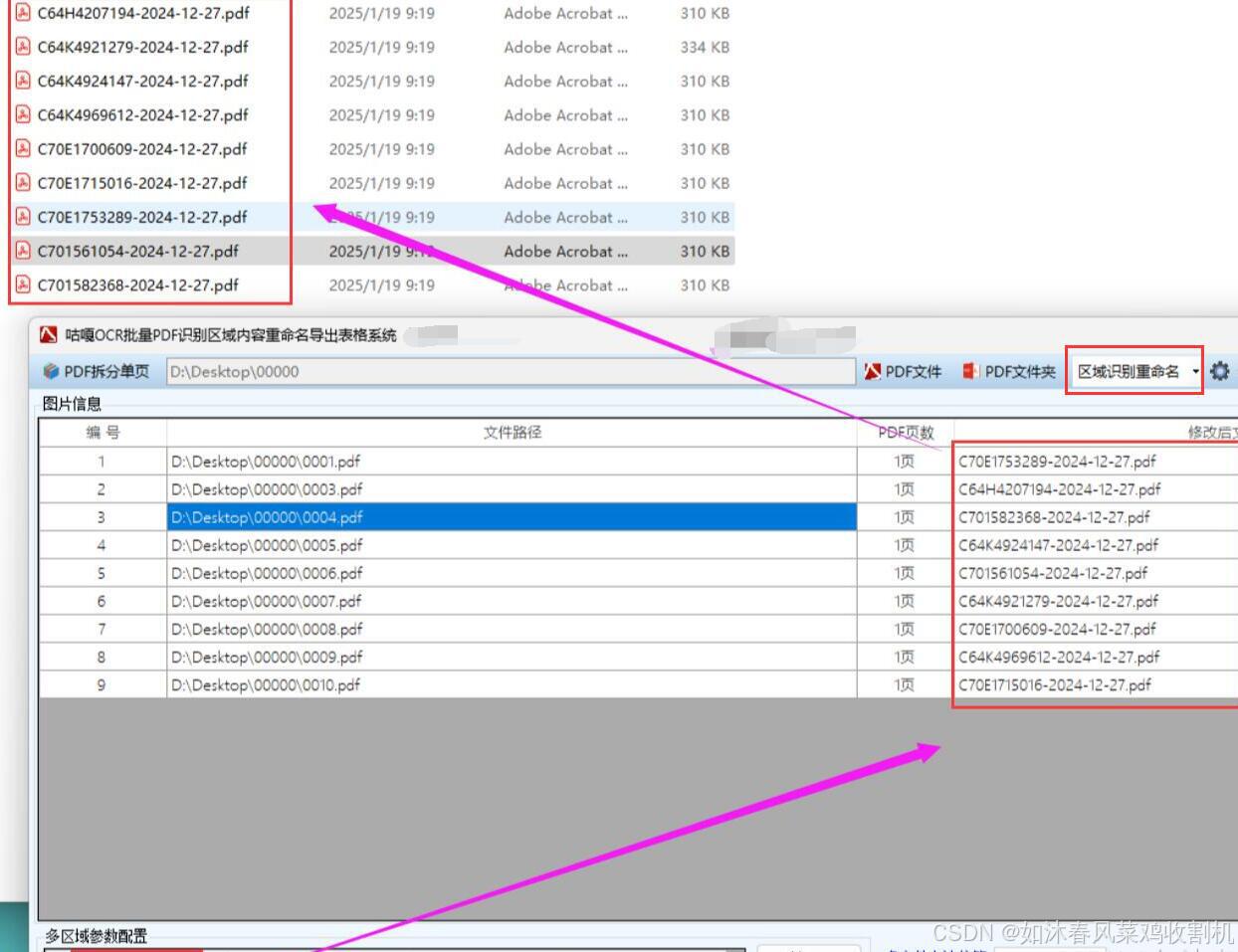
随着大数据技术的发展,企业希望从海量的PDF文件中挖掘有价值的信息用于业务决策。识别PDF文件中的内容、改名以及导出表格,是进行大数据分析的前置工作,这些整理后的文件将作为重要的数据源为分析提供支持。

以下是一个基于 Python 和腾讯 API 实现批量 OCR 识别提取 PDF 用户指定区域内容到 Excel 并根据 PDF 文件内容的标题来批量重命名的详细方案,包括思路和代码实现:
一、实现思路:
- PDF 转图像:
- 使用
pdf2image库将 PDF 文件转换为图像文件,因为 OCR 服务通常对图像进行操作。 - 对于多页的 PDF,将其每一页都转换为单独的图像文件。
- 使用
- 调用腾讯 OCR API:
- 注册腾讯 OCR 服务并获取 API 密钥。
- 对转换后的图像文件进行 OCR 识别。
- 根据腾讯 API 的要求,将图像文件编码为 Base64 格式并发送请求,同时添加必要的签名信息。
- 处理 API 的响应,解析 JSON 数据。
- 指定区域内容提取:
- 定义用户指定的区域(如
(x, y, width, height))。 - 从 OCR 结果中筛选出在指定区域内的文本内容,这可能需要根据 OCR 结果的坐标信息进行判断。
- 定义用户指定的区域(如
- Excel 导出:
- 使用
pandas库将提取的内容存储在 DataFrame 中。 - 将 DataFrame 导出为 Excel 文件。
- 使用
- 文件重命名:
- 从 OCR 结果中提取标题信息(可能需要根据 PDF 的布局,假设标题在特定位置或具有特定格式)。
- 根据提取的标题对 PDF 文件进行重命名。
二、代码实现:
python
import os
import json
import base64
import hashlib
import requests
import pandas as pd
from pdf2image import convert_from_path
# 腾讯 OCR API 信息
API_KEY = "your_api_key"
SECRET_KEY &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3326
3326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









