






把特征放在同一尺度上
1.决策树和随机森林是两种少有的不必担心特征比例调整的机器学习算法(这两种算法不随特征比例的影响)
2.大多数其他的机器学习算法和优化算法,在相同特征比例的情况下表现优异。
3.两个例子:
a.假设有两个特征,一个是1到10的范围,另一个是1到100000范围。Adaline的平方误差函数,算法主要忙于优化误差较大的第二个特征的权重。
b.利用欧氏距离度量k–近邻(KNN)算法,样本之间的计算距离将由第二个特征轴支配
A.归一化: 通常是把特征的比例调整到【0,1】区间,这是最小最大比例调整的一种特殊情况。 公式:
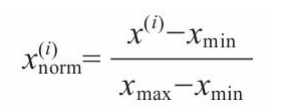
B.标准化:可以把特征列中心设在均值为0且标准差偏差为1的位置,这样特征列呈现正态分布,可以使得权重学习更容易。此外标准化保持了关于离群值的有用信息,使得算法对离群值不太敏感。
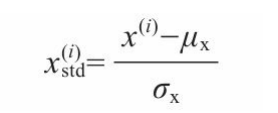
选择有意义的特征
解决问题:如果模型在训练集上表现得远比在测试集合要好,那么很有可能是发生了过拟合,过拟合意味着模型在拟合参数过程中对训练集合某些特征的适应性过强,但却不能很好地概括新数据,因为模型的方差较大。
(化误差是用来衡量一个学习机器推广未知数据的能力,根据从样本数据中学习到的规则能够应用到新数据的能力.)
过拟合的原因:与给定的训练数据相比,我们的模型太复杂。减少泛化误差常见的解决方案:
1.收集更多训练数据
2.通过正则化引入对复杂性的惩罚
3.选择参数较少的简单的模型
4.减少数据维数
正则化实现对模型复杂度的惩罚
L1和L2正则化:
L2正则化:通过惩罚权重大的个体来降低模型复杂度的一种方法
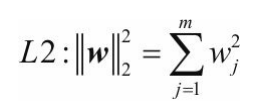
几何意义:假设空间上有个点,如果不加正则化,他就会像黑色箭头一样,愉快地直奔圆心的怀抱。加上正则化这堵墙以后,就是这条绿色的箭头,走着走着就碰壁了,蹭着墙只能挪到离圆心最近的地方,和正则化等值线相切以后,方向就不改变了。
【转载自:https://blog.csdn.net/zhangjiali12011/article/details/89163925】


L1正则化:会产生大部分特征权重为0的稀疏特征向量,某种意义上说L1正则化是一种特征选择技术

几何解释:L1唯一的区别就是几何图像是个矩形,其他都一样


这里交点在w1=0处,这也是产生权重为0的稀疏权重的原因。
降维:另一种避免过拟合的方法
两类降维技术:特征选择和特征提取
特征选择:从原始数据中选择子集
特征提取:从特征集合中提取信息以构造新的特征子空间
区别:特征选择是保持原始特征,特征提取方法是将数据转化或投影到新的特征空间。
在降维背景下可以把特征提取看作是数据压缩方法
特征提取作用:不仅可以优化机器学习算法的存储空间或者计算效率,而且还可以通过减少维数提高预测性能(尤其对于非正则化模型)也可以方便可视化。
无监督数据压缩的主成分分析法PCA
PCA实现逻辑:PCA旨在寻找高维数据中存在最大方差的方向,并且将其投影到维数等于或者小于原始数据的新空间
PCA降维方法:
1.标准化d维数组(必须要标准化,PCA对数据比例尺度很敏感)
2.构建协方差矩阵
3.将协方差矩阵分解为特征向量和特征值
4.通过降序对特征值进行排序,对相应的特征向量排序
5.选择对应k个最大特征值得k个特征向量,其中k为新子空间维数(k<=d)
6.从最上面的k个特征向量开始构造投影矩阵W.
7.用投影矩阵W变换d维输入数据集X获得新得k维特征子空间。
具体理解?待续…
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









