






一、管道方法简化工作流
1.读入数据集:pd.read.csv("+地址“)
2.将特征分配给NumPy阵列x,用LabelEncoder将对象分类标签转为整数。
3.将数据分为训练集和测试集
4.使用make_pipeline函数可以将包含任意多个scikit-learn转换器(支持fit和transform方法作为输入对象),后面接着实现fit以及predict方法的scik-learn评估器。

二、 在模型未见过得数据上评估其性能或者对模型泛化性能得可靠评估方法:
1.抵抗交叉验证:
a.开始阶段:把初始数据集分裂为独立的训练集和测试集,前者用于模型训练,后者用于评估模型泛化性能。
出现问题:在模型选择时反复使用相同的测试集合,他将会成为训练数据的一部分,这样更容易引起模型的过拟合。
b.模型选择:典型的机器学习应用对调整和比较不同的参数设置感兴趣,目的是进一步提高对未见过的数据的预测性能,该过程称为模型选择。模型选择过程就是指对于给定的分类问题,选择最优的参数值(超参数)
超参数:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
c.模型选择更好的方式:将数据分裂为训练集,验证集和测试集。
训练集:用于拟合不同的模型
验证集:用于在模型选择过程中验证性能
测试集:可以对该模型面对新数据的泛化能力有不太偏颇的评估。
d.实现过程
用不同的参数对模型进行训练以后,在验证集上反复评估模型的性能。一旦对调优的超参数值感到满意,就开始评估模型在验证集的泛化性能。

2. k折交叉验证
实现思路:k折交叉验证将训练集合随机分为k个无更换的子集,其中k-1个子集用于模型训练,一个子集用于性能评估。重复该过程k次,得到K个模型和k次性能估计。接着计算基于不同且独立的数据子集模型的平均性能,以获得与抵抗方法相比对训练子集不太敏感的性能评估。通常用k折交叉验证为模型调优,找到最优超参数,以获得令人满意的结果。
k折交叉验证属于无替换的重新采样技术,其优点在于每个采样点仅仅用于训练和验证一次,而对模型性能的评估将产生比抵抗方法更低的方差。

留存交叉验证(LOOCV)该方法把k值设置成训练子集的样本数,这样每一次迭代只有一个训练子集用于测试,适用于规模较小的数据
分层k折交叉验证:略微改善了k折交叉验证方法,所产生的评估偏差和方差比较低,特别是类属性分布不均匀的时候。
三、学习曲线和验证曲线调试算法
1.学习曲线:
提出背景:模型过于复杂,模型中有太多的自由度或者参数,就会对训练数据有过拟合倾向,因而对未见过的数据泛化不良。通常收集更多的训练数据有利于缓解过拟合,但是实际的可操作性不大
解决方法:通过绘制模型训练和验证的准确度与训练数据之间的关系图,可以很容易发现模型是否存在高偏差或者高方差。
高偏差和高方差的理解:
如果训练集设置非常好,而验证集设置相对较差,我们可能过度拟合了训练集,某种程度上,验证集并没有充分利用交叉验证集的作用。这种情况就是高方差(high variance) 算法并没有在训练集中得到很好的训练,如果训练数据的拟合度不高,就是欠拟合,可以说这种算法偏差比较高(high bias)

左上图说明模型遇到高偏差问题。该模型的训练和交叉验证准确度均
低,这说明模型对训练数据欠拟合。解决该问题的常用办法是增加模型的参
数个数,例如,通过收集或构建额外的特征,或者降低正则化的程度,就像
在SVM或逻辑回归分类器所做的那样。
右上图说明模型遇到高方差问题,表现是模型在训练和交叉验证的准确
度上有比较大的差别。要解决过拟合的问题,可以收集更多的训练数据,减
少模型的复杂度,或者增大正则化的参数等。对于非正则化的模型,也有助
于通过特征选择或者特征提取(第5章)减少特征的数量(第4章),从而降
低过拟合的程度。
其实,模型在训练集上的误差来源主要来自于偏差,在测试集上误差来源主要来自于方差。

上图表示,如果一个模型在训练集上正确率为 80%,测试集上正确率为 79% ,则模型欠拟合,其中 20% 的误差来自于偏差,1% 的误差来自于方差。如果一个模型在训练集上正确率为 99%,测试集上正确率为 80% ,则模型过拟合,其中 1% 的误差来自于偏差,19% 的误差来自于方差。
可以理解为偏差时训练数据与真实数据之间的差距,方差时训练数据与验证数据之间的差距
2.验证曲线
验证曲线是通过解决过拟合和欠拟合问题提高模型性能的有利工具

这里c为逆正则化参数,c越小,正则化强度越高,模型越欠拟合,c越大,正则化强度越弱,模型越过拟合
3.学习曲线和验证曲线的关系:
学习曲线绘制的是训练准确率,测试准确率和样本容量之间的关系 验证曲线绘制的是训练准确率,测试准确率和模型参数之间的关系
四、比较不同的性能评估指标
前面我们用模型准确度来评价模型,也可以采用精度,召回率等指标评价模型。
1.混淆矩阵:(这里的T/F表示预测正确与否,P/N 表示预测值,我们需要通过预测值反推正确值,比如FP,我们知道预测值为假,F表示预测错了,那么真实值一定是真)
真阳性:TP(True+Positive)√
真阴性:TN(True+Negative) √
假阳性:FP(False+Positive)×
假阴性:FN(False+Negative)×

计算公式:
误差率ERR=错误的/总的
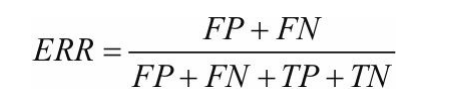
准确率ACC=正确的/总的
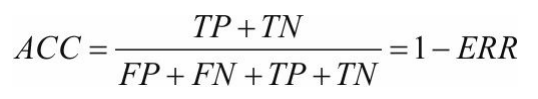
真阳率TPR:(找实际为阳的但预测错误的即是预测为阴的是FN和实际为阳预测也为阳的即TP,用TP除以二者之和)
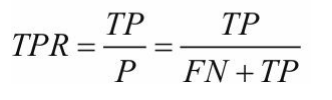
假阳率FPR:(找实际为阴预测为阳和实际为阴预测也为阴的,用FP除以二者之和)
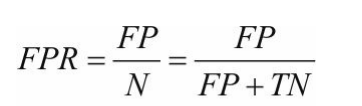
精确率:是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本
精准率PRE=在预测为正的样本中找到正真预测正确的样本
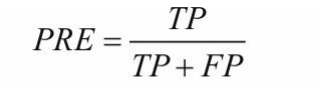
召回率:是针对我们原来的样本而言的,它表示的是样本中的正有多少被预测正确了
召回率REC=在实际分类为正的样本中,找到预测为正确的样本。
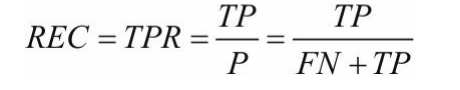
REC=TPR(召回率等于真阳率)
F1-得分:精度和召回率的组合
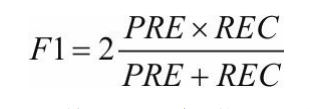
精准率与召回率之间的关系
**假设有这么一组数据,菱形代表 Positive,圆形代表 Negtive 。

现在需要训练一个模型对数据进行分类,假如该模型非常简单,就是在数据上画一条线作为分类边界。模型认为边界的左边是 Negtive,右边是 Positive。如果该模型的分类边界向左或者向右移动的话,模型所对应的精准率和召回率如下图所示:

破题关键:从定义出发
从上图可知,模型的精准率变高,召回率会变低,精准率变低,召回率会变高。
应该选精准率还是召回率作为性能指标?
到底应该使用精准率还是召回率作为性能指标,其实是根据具体业务来决定的。
比如我现在想要训练一个模型来预测我关心的股票是涨( Positive )还是跌( Negtive ),那么我们应该主要使用精准率作为性能指标。因为精准率高的话,则模型预测该股票要涨的可信度就高(很有可能赚钱!)。
五、受试者操作特性图:ROC
以FPR和TPR的性能比较结果作为依据,通过移动分类器的与之完成计算 解释:ROC对角线理解为随机猜想,落在对角线以下的猜想比随机猜想差,TPR=1且FPR=0是最完美的分类器落在图的左上角。 ROC曲线下面积AUC:描述分类模型的特性。















 8105
8105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









