







一、什么是网络爬虫
首先,我们需要接受一个观点:非原创即采集。只要获取不是自己原创的资源(视频、音频、图片、文件等一切数据,比如,通过百度查找信息、在浏览器上阅览网页、使用迅雷下载文件、与朋友微信聊天),我们就是在采集网络数据。理论上而言,采集网络数据是一种通过多种手段收集网络数据的方式,除与API交互(或者直接与浏览器交互)的方式之外,最常用的网络数据采集方式是编写一个自动化程序向网络服务器请求数据(通常是用HTML表单或其他网页文件),然后对数据进行解析,提取需要的信息。采集网络数据所用到的程序一般被称为网络爬虫(Web crawler)。
网络爬虫(网络数据采集程序)就像一只辛勤采蜜的小蜜蜂,它飞到花(目标网页)上,采集花粉(需要的信息),经过处理(数据清洗,存储)变成蜂蜜(可用的数据)。
二、什么是网页
对于采集网络数据而言,第一步就是要“飞”到目标网页上,那么网页是什么呢?网页制作的标准又是什么呢?
超文本标记语言(HyperText Markup Language ,HTML)是一种制作网页的标准语言,它消除了不同计算机之间信息交流的障碍。 其中,“超文本”就是指网页中可以包含图片、音乐、链接、程序等非文字元素。HTML定义许多用于排版的命令,即标签(tag)。例如,<I>表示后面开始用斜体字排版,</I>则表示斜体字排版到此结束。HTML就把各种标签嵌入到网页中,构成了HTML文档。当浏览器读取到此文档之后,就按照HTML文档中的各种标签,根据浏览器的所使用显示器的大小和分辨率的高低,重新进行排版并显示出来。由此可见,网页的本质就是HTML文件。
下面是一个HTML的示例以及其在浏览器中的显示:

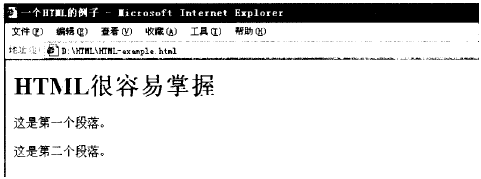
三,如何访问网页
按照生活常识,我们都是通过网址访问网页,比如通过在浏览器中输入www.baidu.com访问百度。甚至,我们只需输入baidu.com,浏览仍然会显示百度主页。但是,对于爬虫程序而言,其无法像人一样智能执行操作,其只能按一定协议,一定格式进行网页定位。
统一资源定位符(Uniform Resource Locator,URL)是对可以从因特网上得到的资源位置和访问这些资源的方法的简称。其中,这里所说的“资源”是指互联网上任何可以被访问的对象,包括文件目录、文件、文档、声音以及与因特网相连的任何形式的数据。
统一资源定位符URL一般由以下四个部分组成:
<协议>://<主机>:<端口>/<路径>
<协议>是指用什么协议来获取该万维网文档。最常用的协议是超文本传输协议http,其次是文本传输协议ftp。
<主机>是指该主机在因特网上的域名(任何一个连接在因特网上的主机或路由器,都有一个唯一的层次结构的名字,即域名)。
<端口><路径>有时可以省略。
四、题外话
我在写这篇文章之前,和大多数同学一样,也只懂Python的基本语法,并且从未涉猎过HTML等知识。所以,对于文章中出现的任何问题,恳请大家指出。希望与大家一起学习,进步。
另外,我个人不喜欢单纯的讲解理论,所以文章大部分都是代码。在代码的上方,我添加了很多“”#注释“”,一般来说,这些注释除了说明这段函数的功能外,常常也讲解了某些属性或者方法的具体理论。















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









