









文章来源
paper:https://arxiv.org/pdf/2104.11178
Motivation
作者提出了一个使用无卷积transformer架构从无标签数据中学习多模态表示的框架。具体来说,Video-AudioText Transformer (VATT)将原始信号作为输入,并提取足够丰富的多模态表征,从而有利于各种下游任务(例如检测、分类、跟踪)。作者使用多模态对比损失从头到尾训练VATT,并通过视频动作识别、音频事件分类、图像分类和文本到视频检索等下游任务评估其性能。此外,作者研究了一种模式不可知的、单骨干的transformer,在三种模态之间共享权值。证明了无卷积VATT在下游任务中的性能优于先进的基于基于ConvNet的结构。
最近的研究表明,无需卷积的、专门设计的全注意模型可以匹配cnn在图像识别任务中的表现。
作者提出了一个紧迫的问题:如何得到大规模未标注的数据?
作者认为多模态视频的极大规模有可能教会transformer必要的先验知识,而不是预先定义的归纳偏差,以建模视觉表征。
为此,作者研究了三种transformer的self-supervised、多模态预训练[93],它们分别将互联网视频的原始RGB帧、音频波形和语音音频的文本作为输入。
Method

整体执行过程如下:
- 将每个模态通过tokenization layer。即将原始输入投影未一个enbedding 向量,然后传递给Transfomer.
- Transformer backbone提取具体某个模态的表征,然后将其映射到共享空间中,带上对比损失。
Transformer 有2种主要的设置:(1)每个模态都有具体各自的权重;(2)各个模态共享同一个权重。
详细步骤如下:
(一)Tokenization and Positional Encoding
-
Video:
设每个视频片段(video clip)的大小为: T × H × W T \times H \times W T×H×W。
首先,将其划分为若干个小patch ∈ t × h × w × 3 \in t \times h \times w \times 3 ∈t×h×w×3: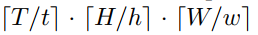
紧接着采用线性投影的方式得到每个patch的d维向量。即用一个可学习的矩阵 W v p ∈ t h w × d \mathbf W_{vp} \in thw \times d Wvp∈thw×d。
最后,定义了可学习的embedding沿着3D空间编码位置信息,即:

故需要用上位置embedding分别加入到 e i , j , k e_{i,j,k} ei,j,k中,该位置embedding的长度为:
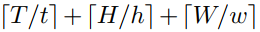
-
Audio
原始的audio信号是1D的数据,其长度为 1 ∗ T ′ 1*T^{'} 1∗T′,紧接着将其划分为 ⌊ T ′ / t ′ ⌋ \lfloor T^{'}/t^{'} \rfloor ⌊T′/t′⌋个小片段,每个片段的长度是 t ′ t^{'} t′。
紧接着,应用线性投影,即采用可学习的矩阵 W a p ∈ R t ′ × d \mathbf W_{ap} \in \mathbb R^{t^{'} \times d} Wap∈Rt′×d.
最后,作者采用了 ⌊ T ′ / t ′ ⌋ \lfloor T^{'}/t^{'} \rfloor ⌊T′/t′⌋个可学习的embedding去编码每个波形片段。 -
Text
首先,构建一个包含所有训练数据单词的词汇库,其长度为 v v v。
紧接着,对于每一个单词,将其映射为 v v v维度的one-hot向量;
最后,用一个可学习的矩阵 W t p ∈ R v × d \mathbf W_{tp} \in \mathbb R^{v \times d} Wtp∈Rv×d去实现线性投影。
(二)DropToken

Droptoken用来在训练时减少计算复杂度。
在得到视频或者语音模态的token后,随机性的选择这些token的一部分通过采样序列,并非采用所有的token数据 传递到Transformer。
作者认为与其降低原始输入的分辨率或维度,不如保持高保真输入,并通过DropToken随机抽样token。DropToken特别具有吸引力,因为它的原始视频和音频输入可能包含高冗余。
(三)Transformer-backbone
具体执行方案如下:
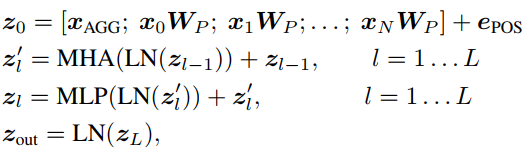
x
A
G
G
\mathbf x_{AGG}
xAGG是可学习的embedding ,代表聚合所有输入信息的可学习embedding,其输出为
z
o
u
t
0
z_{out}^0
zout0,该输出会用于后续的分类和common space映射。
MHA代表Multi-Head-Attention,执行了标准的self-attention操作。
MLP代表多层感知机,其激活函数采用了GeLU。
LN代表Layer Normaliztion。
e
p
o
s
\mathbf e_{pos}
epos代表position embedding。
作者在文本模型中,去掉了编码位置
e
P
O
S
e_{POS}
ePOS,并在MHA模块的第一层的每个注意得分中添加了一个可学习的相对偏差。这个简单的改变使文本模型的权重可以直接转移到最先进的文本模型。
(四)Common Space Projection
作者使用了公共空间投影和对比学习来训练网络。更具体地说,对于一个视频-音频-文本三元组,作者定义了一个在语义层次的公共空间映射,能够通过余弦相似度直接比较视频-音频对和视频-文本对。为此,作者将多层次预测定义如下:
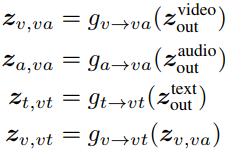

其中
g
a
→
v
a
(
)
g_{a \rightarrow va()}
ga→va()是用2层带有ReLU激活函数的投影实现的,此外,作者还增加了BN层在每个线性层后面。
(五)Multimodal Contrastive Learning
由于未标记的多模态视频数据随处可得,故作者采用了self-supervised目标函数训练VATT模型。
作者使用了Noise-Contrastive-Estimation (NCE)来对其video-text和video-autio pairs,其中video-text和video-autio pairs是来自视频的不同时序位置。
作者定义了正样本和负样本pairs。
正样本pairs:在同一个视频片段里面同时选择video和audio信息,在不同的时序上同时选择video和text信息。
负样本Pairs:分别随机在不同的video,audio和text上选择。
接着,作者定义了NCE loss,最大化正样本pairs的相似性同时最小化负样本pairs的相似性。
由于在预训练的数据集上存在很多噪声text数据,并且有些视频片段不包含语音信息。因此,作者使用了 Multiple-Instance-learning-NCE(MIL-NCE)去匹配一个视频输入和多个text输入信息,视频和text在视频输入的时序上是很靠近的。这种变体改进了用于视频-文本匹配的普通NCE。作者对视频-音频对使用常规NCE,对视频-文本对使用MIL-NCE。具体来说,给定上节中规定的公共空间,损失目标可写为:

B
B
B代表batch_size,作者在每次迭代上构建了B个video-audio pairs。
分别代表正的
P
(
z
)
\mathcal P(z)
P(z)和
N
(
z
)
\mathcal N(z)
N(z)分别为视频剪辑
z
v
,
v
t
\mathbf z{v,vt}
zv,vt周围的正文本剪辑和负文本剪辑。具体来说,
P
(
z
v
,
v
t
)
\mathcal P(z{v,vt})
P(zv,vt)包含了5个与视频剪辑在时间上最接近的文本剪辑。τ用来调整区分正对和负对时目标的超参。
最后,VATT模型总的损失函数如下:
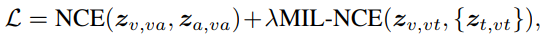
总结
文章多模态的方式值得借鉴,由于作者没有提供源代码,可以在下面参考。
BERT: https://github.com/google-research/bert
ViT: https://github.com/google-research/vision_transformer














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









