






【论文笔记】VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
论文信息
题目:VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
作者:Hassan Akbari and Liangzhe Yuan and Rui Qian and Wei-Hong Chuang and Shih-Fu Chang and Yin Cui and Boqing Gong
期刊/会议:35th Conference on Neural Information Processing Systems (NeurIPS 2021)
时间:2021
领域:Multimodal
关键词:Multimodal; Self-Supervised. Raw Data; Transformer
VATT的代码是公开的。
Why?
目前已有工作
- 目前算机视觉任务的主流做法是用卷积神经网络(CNN);
- NLP社区完成了从RNN和CNN等具有强归纳偏差(inductive bias)到基于自注意力机制构建的更通用模型的转变。Transformer在大型语料库上进行与训练然后微调可以为不同任务带来SOTA的结果;
- 已经有工作开始探索计算机视觉中Transformer的应用,且取得了令人信服的效果,“large scale (supervised) training trumps inductive bias (for image classification)”,并将这一结论扩展到视频识别任务中。
现在存在的问题及原因?
- Transformer的大规模监督训练(supervised)忽略了大量未标记的非结构化视觉信息,且监督训练中带来的偏差系统(Biased system
个人认为相当于过拟合) - 有监督训练从根本上限制了Transformer的应用范围,因为要足够多的标签视频数据或图像
切入点是什么?
基于上述问题,本文提出了另一个关于Transformer如何讲原始信号作为输入的紧迫问题。“如何为它们提供大规模的无监督视觉数据?”为了解决这个问题,文章从NLP中获得灵感,BERT和GPT用掩码机制(Masked Language Modeling)作为预训练任务。自然语言是Transformer天然的监督,依次将单词、词组和句子置于上下文中,赋予他们语义和语法,
而对于视觉数据,最天然的监督数据就是多模态视频。在数字媒体世界中,有大量可用的多模态视频,它们的实时性和跨模态校准性(p.s. 不同模态之间可以对齐)可以带来不需要人工标注的自监督性。 ,可以教会Transformer必要的先验知识,以建模视觉世界。
思路是什么?
研究了三个Transformer的自监督和多模态预训练,将互联网视频的原始的RGB帧、音频的波形和演讲语音的文本转录分别作为输入。文中将视觉音频文本Transformer成为VATT。VATT借用了BERT和ViT的架构,并为每个单独模态保留了tokenization和线性投影。VATT对ViT的架构进行了最小的更改,一边可以与其他框架和任务共享权重。
扩展
为了探索是否存在多模态通用的Transformer,作者在三种模态共享权重,并保留各自的线性映射和标记化层,并获得了不错的结果。
提出DropToken,可以降低训练的复杂性,但是会略微降低性能。DropToken在训练期间从每个输入序列中随机丢弃一部分视频和音频token,允许高分辨率输入并利用其丰富性、这对于Transformer来说很重要,因为它们的计算复杂性相对于输入token的数量是平方的。
How?
论文的具体贡献
- VATT模型的提出
- 对模态共享权重的探索
- 提出DropToken
具体模型和算法
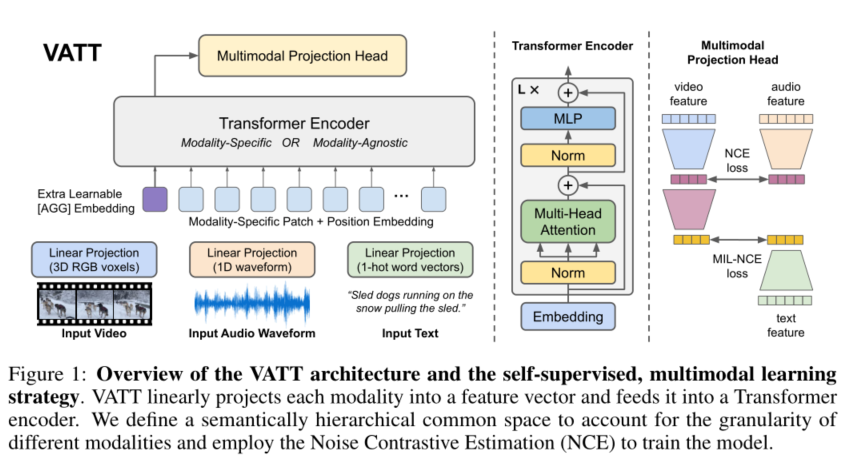
VATT将每个模态线性投影到特征向量中,并将其送到Transformer编码器中,并将编码后的特征在语义分层的不同粒度空间中通过噪声对比估计(NCE)来训练模型。
文章提出了两种Transformer设置:
- 主干Transformer权重是相互独立的
- 主干Transformer是模态共享权重
模型整体是通过Transformer提取不同模态的表示然后映射到公共空间,并通过对比损失来比较各个模态进行对齐。
Tokenization和位置编码
VATT直接对原始信号进行处理,视觉输入是3通道RGB像素视频帧,音频输入是初始波形,文本输入是单词序列。
对于视频片段,方法是将一整个T*H*W的视频片段划分为[T/t]*[H/h]*[W/w]的小Patch序列,其中每个patch包含t*h*w*3个立体像素,然后对每个patch的所有像素应用一个线性投影,这个线性投影由一个可学习的权重执行,具体实现可以看作是[1]中提出的patching机制的3D扩展。
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
对于位置编码,文中定义了一个可学习嵌入的特定维度序列:
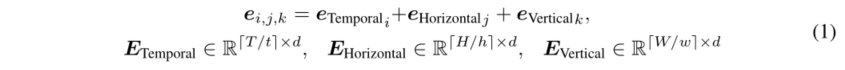 其中
其中e_i是E的第i行。这样一来就可以用[T/t]+[H/h]+[W/w]个位置嵌入来表示所有patch的位置。
原始音频波形是一个1D的输入,长度为T’,将其划分为[T'/t']个片段,每个片段包含t'长度的波形振幅。类似于视频,对音频同样使用可学习权重的线性投影来把一个patch中的所有元素投影到线性空间中来获得一个d-维度的向量表示。并使用[T'/t']个位置向量来编码每个波形片段的位置。
对于文本,先构建大小为v的词库表,然后对每个单词映射到v维度的独热向量,并通过可学习权重的线性映射进行映射。
DropToken(p.s. 就是按顺序随机采样)因为Transformer的计算复杂度是O(N^2)的,而且作者认为与其降低输入维度不如随机采样高维度的Token。
Transformer结构
为了简单,文中使用了NLP中最成熟的Transformer架构。与ViT类似,不调整架构以便将权重迁移到任何标准的Transformer中实现。如图1中间部分所示。Transformer的输入如下:
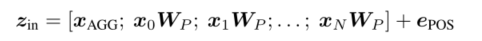
其中x_AGG就是CLS Token,用来聚合整个序列的表示。
公共空间映射
就是通过线性映射把Transformer输出的模态表示映射到同一个空间中。

同时和Self-Supervised Multimodal Versatile Networks这篇文章中一样提到了不同粒度的空间。
多模态对比学习
使用NCE (Noise Contrastive Estimation)对齐视频-音频对和MIL-NCE (Multiple Instance Learning NCE)对齐视频-文本对。
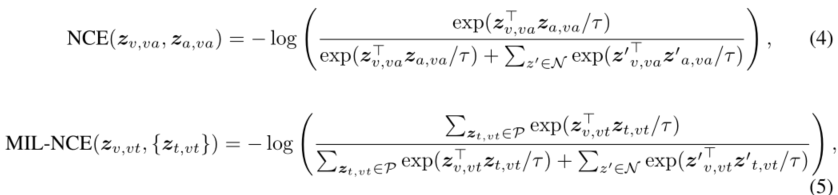
总体训练目标就是两个对比损失通过一个超参数的比例相加:
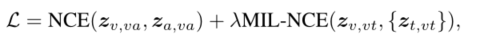
模型通过上述损失函数进行端到端的训练。
实验结果
数据集
预训练数据集:
- HowTo100M
- AudioSet
下游任务:
- UCF101,HMDB51,Kinetics-400,Kinetics-600,Moments in Time (视频动作识别)
- ESC50,AudioSet (音频事件分类)
- YouCook2,MSR-VTT (零次文本视频检索)
- ImageNet (图像分类)
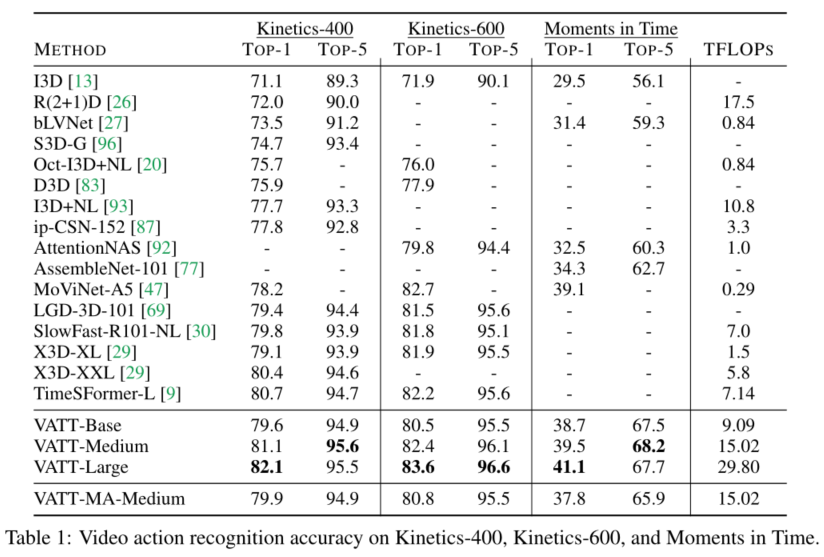
视频动作识别
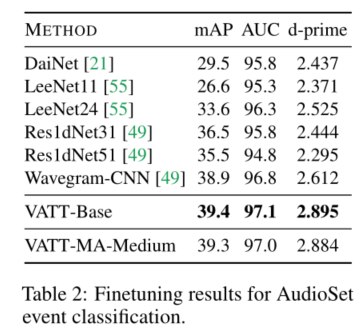
音频事件分类
图片分类

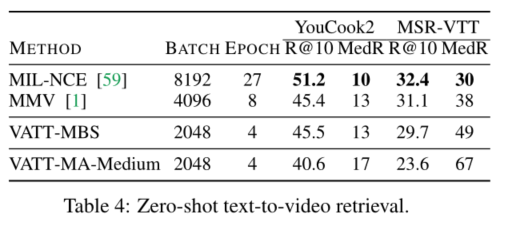
零次文本视频检索
提供了哪些思路?
可以考虑一下多模态统一模型的应用和优化

















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









