






这篇论文的作者是Yuan Gong, Yu-An Chung, James Glass ,MIT Computer Science and Artifificial Intelligence Laboratory, Cambridge, MA 02139, USA
研究动机
为了做音频分类任务,在CNN的基础上加了注意力机制,如果注意力机制有用,那么可不可以只使用注意力机制就可以获得好的效果?因为CNN并不是必要的。
INTRODUCTION
为了做音频分类任务,提出了AST(audio Spectrogram Transformer)模型,不含CNN架构。用ViT(Vision Transformer)模型迁移到AST。
模型结构
将t秒的波形变换为128维的对数梅尔频谱特征,使用的是25ms的汉明窗,窗移10ms,最终形成的形状是[128,100],之后将频谱分成16x16的小块,重叠为6,论文中有一个计算分成块的数量公式,分成块之后,将每一个块展平成一维的数据,大小是768,怎么展平的?16x16x块数量并且用一个线性投影层。因为Transformer和块序列没有时间信息,所以加入了一个正数embedding,同样是768,为的是获得二维频谱的空间信息。
输入到网络中,最开始在序列前面加入一个token,[cls],AST只用来做分类任务,所以只用到了Transformer 中的encoder层,而且用的是最原始的结构,没有做任何的修改,这样的优势有2个:第一,Tensorflow 或者Pytorch有内置的Transformer结构,容易实现;第二,原始的结构迁移学习很容易。
补充一点就是,块的信息被展平为一维信息用的是一个线性层投影,它相当于一维卷积。
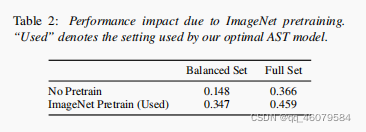
Transformer比CNN强是当数据量变得很大的时候,但是音频数据并没有那么多,所以为了不用CNN,使用迁移学习比较好,它不要求数据量很多。所以现在图片数据集上预训练ViT模型,但是有一些小点需要注意,图片的通道是三维,而音频是一维,所以就需要把维度提上去。同样地,需要归一化操作。另外,频谱的长度是变化的,Transformer也支持变化的输入长度,还可以直接从一个模型迁移到另一个模型。提出一种cut and bi-linear interpolate方法在正向量那。
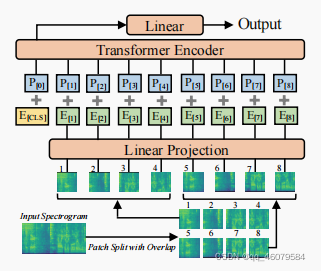
实验设置
数据和操作
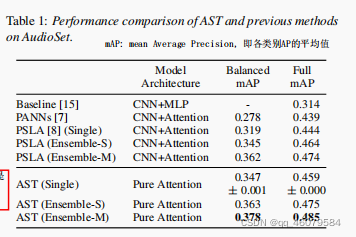
AudioSet: 2百万10秒的视频片段和527个标签,训练集,验证集,测试集按照22k,2M,20k来划分。用了数据增强,Adam优化器,batch为12,使用二分类交叉熵损失。分为balanced training, fulling training,前者代表训练一部分数据,后者代表把数据全用于训练,前者的实验数据是:学习率5e-5,25epochs,每5轮学习率减半,10轮停止。后者的实验数据是:学习率1e-5,训练5epochs,在每个epoch学习率减半,2轮之后停止。实验结果如下:
用不用预训练的区别:
实验结果
让balanced和full的实验重复三次,每次实验设置一样,但随机种子不一样。表中的Ensemble-S:实验三次,相同的设置,不同的随机种子,最后算出结果的平均值。Ensemble-M:让模型用不同的设置,让Ensemble-S中的三个模型和另外用不用的块分离策略的三个模型一起训练。
做了一些对比实验,结果如图:
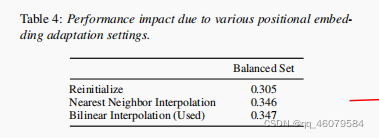
patch就是文章中说的块:
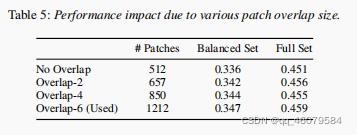
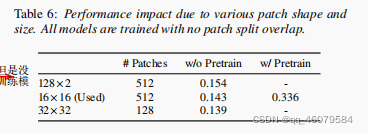
除了这些对比实验,单个变量的对比以外,还在其他的数据集上做了比较:
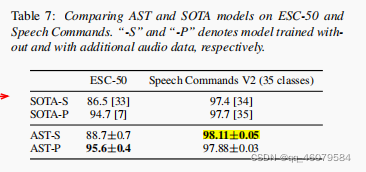
结论
不用CNN的结构也是可以实现语音分类的任务的。
生词
hybrid model 混合模型
benchmark 基准
inductive biases 归纳偏置
state-of-the-art(SOTA)
convolution-free 没有卷积
converge 收敛
off-the-shelf 现成的
cross-modality 交叉模态
regime 规则
interpolate 内插
ablation study 对比实验
checkpoint 检查点
indispensable 不可缺少的

















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









