







1. flume 的基本概念
本文中所有与 flume 相关术语都采用斜体英文表示,这些术语的含义如下所示。
flume 一个可靠的,分布式的,用于采集,聚合,传输海量日志数据的工具。
Web Server 一个产生 Events/数据 的客户端。
Agent flume 系统中的一个节点,它主要包含三个部件:Source, Channel, Sink。
Event 事件,在 flume-agent 内部传输的数据结构。一个 Event 由 Map<String, String>Headers 和 byte[] body 组成,其中 Headers 保存了 Event 的属性,body 保存了 Event 的内容。
Source Agent Source 用来接收 WebServer 产生的 Events,以及其他 flume-agent 中的 Sink 产生的 Events。
Channel Source 将 Events 放在 Channel 中保存,Channel 主要有两种,是 MemoryChannel 和 FileChannel,分别将 Events 存放在内存中和文件中。
Sink Sink 用来消费 Channel 内保存的 Events,然后将 Events 发送出去。
Sinkgroups 将多个 Sink 组合在一起,形成 Sinkgroups。
HDFS Hadoop分布式文件系统,它用来存储日志数据,也就是 Sinks 发送出来的 Events。
2. flume 的数据流模型
(1) 单 Agent 单数据流模型
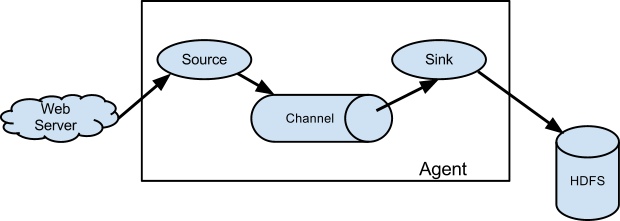
图1 单 Agent 单数据流模型
(2) 多 Agent 串行传输数据流模型
如下图 2 所示,多个 Agent 可以串在一起,将数据从 Agent foo 传输到 Agent bar,再传输到目的地。

图2 多 Agent 串行传输数据流模型
(3) 多 Agent 汇聚数据流模型
如下图 3 所示,我们将来自于位于不同服务器的 Agent1, Agent2, Agent3 收集到的数据 汇聚到一个中心节点 Agent4 上,再由 Agent4 统计将数据写入到 HDFS上。通常这种情况下,我们称 Agent1, Agent2, Agent3 为 flume_agent,称 Agent4 为 flume_collector,即汇聚节点的含义。
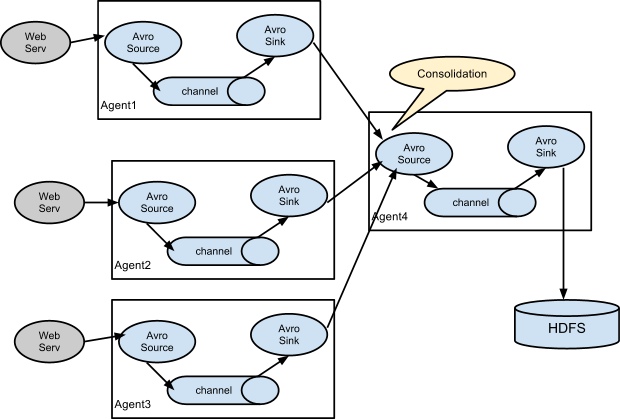
图3 多 Agent 汇聚数据流模型
(4) 单 Agent 多路数据流模型
一个 Agent 中可以由一个 Source ,多个 Channels ,多个 Sinks 组成多路数据流,其多路数据流模型如下图4所示。
一个 Source 接收外部 Events,并将 Events 发送到三路 Channel 中去,然后不同的 Sink 消费不同的 Channel 内的 Events ,再将 Events 进行不同的处理。
Source 如何将 Events 发送到不同的 Channel 中?这里 flume 采用了两种不同的策略,是 replicating 和 multiplexing 。
其中 replicating 是 Source 将每个 Event 都发送到 Channel 中,这样就将 Events 复制成 3 份发到不同的地方去。
其中 multiplexing 是 Source 根据一些映射关系,将不同种类的 Event 发送到不同的 Channel 中去,即将所有 Events 分成3份,分别发送到三个 Channels。
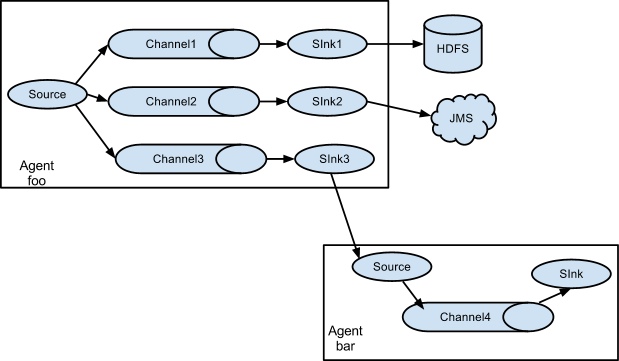
图4 单 Agent 多路数据流模型
(5) Sinkgroups 数据流模型
上面 4 种数据流模型,都会有同一个问题:一条数据流经过的所有节点,如果中间的某个节点 Down 之后,都会影响整个数据流断流。flume 内部提供了 sinkgroups 数据流模型,能够将下游多个节点组合成一个集群,其中集群中的某个节点 Down 之后,不影响数据流。
sinkgroups 将 sinks 组合在一起,通过两种策略从中选择一个 sink 来消费 channel。sinkgroups 提供的两种策略有 :failover 和 loadbalance。
其中 failover 机制,会将所有 Sinks 标识一个优先级,一个以优先级为序的 Map 保存着 活着的 Sink,一个队列保存着 失败的 Sink。每次都会选择优先级最高的活着的 Sink 来消费 Channel 的 Events。每过一段时间就对失败队列中的 Sinks 进行检测,如果变活之后,就将其插进 活着的 Sink Map。
另一种 load_balance机制,在这种机制下,还有两种不同的策略,分别是 round_robin 和 random。则 round_robin 就是不断地轮询 Sinkgroups 内的 Sinks,已保证均衡。random 则是从 Sinkgroups 中的 Sinks 随机选择一个。
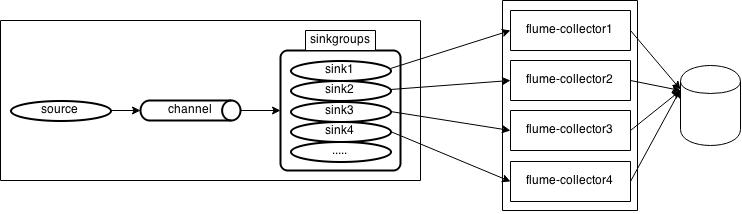
图5 sinkgroups 数据流模型。
(6) 扩展数据流模型。
上述 5 种数据流模型是官方文档中提到的,我只是知识的搬运工。
由于 flume 提供了三种组件 Source, Channel, Sink。在 flume 允许范围内可以任意组织这三种组件建立出各种各样的数据流模型来满足需求。现在就充分发挥我们的想象力,组合各种样的数据流模型来满足各种各样的需求。
在单个 Agent 可以有多个 Source, Channel, Sink 组成多条数据流,它们彼此独立,互不关联。如下图6 所示,两个并行的数据流模型为 web server1 --> source1 --> channel1 --> sink1 --> HDFS1,web server2 --> source2 --> channel2 --> sink2 --> HDFS2。
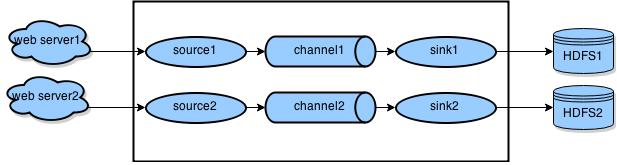
图6 单 Agent 多条数据流模型
Agent 提供多种输入源,即多个 Source,一个 Channel,一个 Sink 组合的数据流模型,如下图7所示。
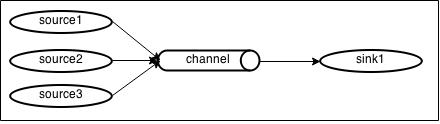
图7 多种输入源数据流模型















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









