






网络爬虫笔记—Selenium
1、简介及环境安装
Selenium是一种自动化测试工具,利用它可以操作浏览器执行固定动作,例如点击、下拉等操作。在日常工作中,如果你需要用浏览器并且重复某项操作,那Selenium工具可以帮你自动化完成这些重复且枯燥的工作。
Selenium因为需要操作浏览器,所以需要下载对应浏览器的驱动,以此来达到操作浏览器的目的。对于插件的下载与安装,这里不再详细介绍,如你没安装,可参考这篇谷歌浏览器驱动的安装教程
chromedriver下载与安装方法,亲测可用_zhoukeguai的博客-CSDN博客
针对Selenium工具的使用,前期我写了一篇如何爬取东方财富研报的文章,如果你感兴趣,可点击股票评级信息抓取查看。
2、创建浏览器对象和访问页面
from selenium import webdriver
browser = webdriver.Chrome()#创建一个谷歌浏览器对象
goalurl = "https://www.baidu.com"#网址前需加上https://,不加有时会报错
browser.get(goalurl)#自动打开谷歌浏览器,并访问百度
print(browser.page_source)#输出网页源码
browser.close()#关闭谷歌浏览器
运行上述代码,电脑便会打开谷歌浏览器并访问百度网站,然后输出百度网站源码,之后关闭谷歌浏览器。
3、查找节点
要用selenium操作浏览器,首先需要知道浏览器各个元素对应的位置或者节点,只有知道这些节点才能自动化操作网页,下面就介绍一些节点的查找方法。
3.1、单个节点
例如我们想要模拟点击百度网站的“百度一下”按钮,那么要如何操作呢?

首先按照下图步骤,查看节点信息:

通过上图可以看到,【百度一下】按钮的各个属性值如下:
| 属性名 | 属性值 | 说明 |
|---|---|---|
| tag name | input | 可能会重复 |
| id | su | 网页中,一个id只会对应一个节点,不会重复 |
| class | btn self-btn bg s_btn | 可能会重复 |
因此,我们可以利用这些属性值,来控制谷歌浏览器点击【百度一下】按钮,具体代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()#创建一个谷歌浏览器对象
goalurl = "https://www.baidu.com"#网址前需加上https://,不加有时会报错
browser.get(goalurl)#自动打开谷歌浏览器,并访问百度
browser.find_element(By.ID, "su").click()#通过id值定位百度一下按钮,并进行模拟点击
#browser.find_element(By.XPATH, '//*[@id="su"]').click()#通过xpath方法点击
browser.close()#关闭谷歌浏览器
通过其他属性定位节点的方法:find_element(By.NAME, "element_name"),find_element(By.ID, "element_id"),find_element(By.LINK_TEXT, "element_link_text"),find_element(By.PARTIAL_LINK_TEXT, "element_partial_link_text"),find_element(By.TAG_NAME, "element_tag_name"),find_element(By.CSS_SELECTOR, "element_css_selector"),find_element(By.XPATH, "element_xpath")
上面列出的方法有很多,不过常用的是通过id、tagname、Xpath的方法来定位元素节点位置。个人感觉Xpath是一个非常好用的方法,因为它的element_xpath参数不需要自己编写了,直接通过浏览器复制就好了。是一个很好的懒人神奇,其复制方法如下图:

3.2、多个节点
通过find_element只能查找并返回一个节点,当有多个节点时,就需要使用find_elements来获取,两者区别如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()#创建一个谷歌浏览器对象
goalurl = "https://www.baidu.com"#网址前需加上https://,不加有时会报错
browser.get(goalurl)#自动打开谷歌浏览器,并访问百度
noslist = browser.find_element(By.TAG_NAME, 'a')
yeslist = browser.find_elements(By.TAG_NAME, 'a')
browser.close()#关闭谷歌浏览器
print("find_element的返回结果:",noslist)
print("find_elements的返回结果:",yeslist)
输出结果:
ind_element的返回结果: <selenium.webdriver.remote.webelement.WebElement (session="76abea3c4d66702906b9cc9fa78b08f1", element="8a7312ad-f334-468f-a3de-ca8a63d8c552")>
find_elements的返回结果: [<selenium.webdriver.remote.webelement.WebElement (session="76abea3c4d66702906b9cc9fa78b08f1", element="8a7312ad-f334-468f-a3de-ca8a63d8c552")>, <selenium.webdriver.remote.webelement.WebElement (session="76abea3c4d66702906b9cc9fa78b08f1", element="39b75cbc-0bea-4802-a882-bcba628d4a2b")>,...
find_elements的返回内容进行了简写,从返回结果来看,find_element只能获取一个节点信息,而find_elements可以获取所有满足条件的节点信息。两者在写法上完全相同,仅仅是后面多了一个字母s。
4、节点交互
selenium节点交互,就是通过程序模拟人,手动操作浏览器,例如操作浏览器的点击动作、输入文字、清空文字等操作;下面模拟一下百度搜索“宏蜘蛛”的动作。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()#创建一个谷歌浏览器对象
goalurl = "https://www.baidu.com"#网址前需加上https://,不加有时会报错
browser.get(goalurl)#自动打开谷歌浏览器,并访问百度
myinput = browser.find_element(By.ID, "kw")#找到百度输入框
myinput.send_keys("宏蜘蛛")#在百度输入框中输入“宏蜘蛛”
time.sleep(1)#等待一秒
myinput.clear()#清空百度输入框中的内容
time.sleep(2)#等待2秒
browser.find_element(By.ID, "kw").send_keys("宏蜘蛛")#重新向输入框中输入“宏蜘蛛”
searchbutton = browser.find_element(By.ID, 'su')#找到【百度一下】按钮
searchbutton.click()#点击【百度一下】按钮
time.sleep(2)#等待2秒
browser.close()#关闭谷歌浏览器
其他更加详细的方法,大家可参考selenium官方文档。
5、动作链
上面介绍的一些动作,都是针对单个元素进行操作。在实际使用浏览器过程中,我们有时也会对某些元素进行拖拽,例如,将一个图片从A处拖拽到B处。这些动作通过上面的单个元素的操作方法是无法实现的,这时就需要运用到动作链。
例如下图中,我们要将【请托拽我!】拖拽到【请放置到这里!】这个地方,这就需要使用到动作链。案例网页的网站地址为:https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
拖拽前

拖拽后

browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
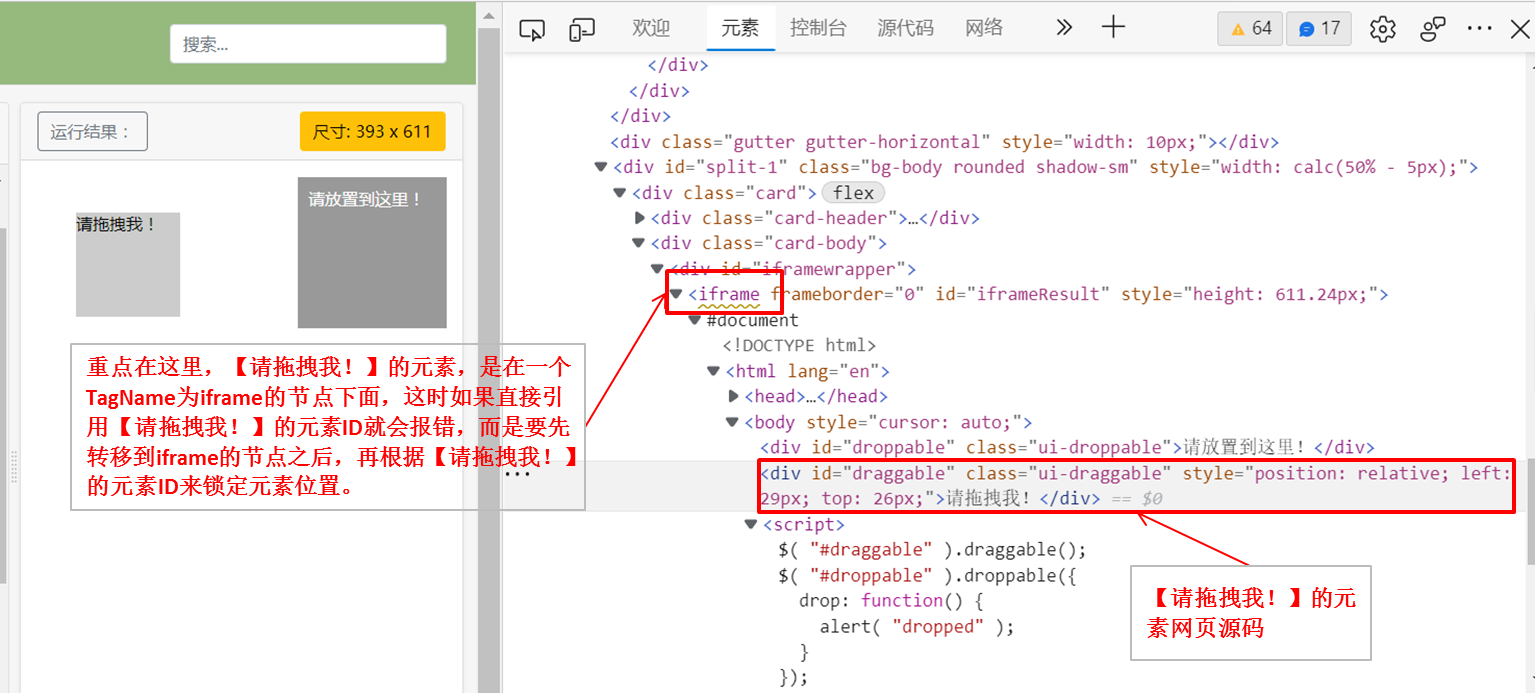
browser.switch_to.frame('iframeResult')#转移框架,这是因为下面的source和target元素都是在ID为
#iframeResult的frame类型下面
source = browser.find_element(By.ID,'draggable')#可参考3.1 单个节点的方法获取该节点的信息
target = browser.find_element(By.ID,'droppable')#可参考3.1 单个节点的方法获取该节点的信息
actions = ActionChains(browser)#创建动作链
actions.drag_and_drop(source, target)#设置移动的前后元素目标
actions.perform()#执行拖拽动作
代码解析
上述代码中出现了一个新的代码browser.switch_to.frame('iframeResult'),如将这段代码删掉后,会出现如下错误提示:NoSuchElementException: no such element: Unable to locate element: {"method":"css selector","selector":"[id="draggable"]"},后面查找了一些资料,找到了具体的原因。
网页中有一种节点叫作iframe,它是子Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级Frame里面操作,而此时如果页面中还有子Frame,它是不能获取到子Frame里面的节点的。这时就需要使用switch_to.frame()方法来切换Frame。
关于更多动作链的内容,这里不再详细阐述,大家如有需求,可点击此处,查看官方文档。
6、下拉进度条(执行JavaScript)
有些网页的内容是使用JavaScript渲染的,其内容并不会全部展示出来,而是浏览到哪里就加载到哪里,如果你不往下拉,它会显示点击此处查看更多内容,这时抓取网页信息的时候,只能抓取到查看更多之前的部分。如想抓取更多内容,则需要运用模拟下拉进度条的方法。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')#括号里面执行的JavaScript脚本
#意思就是将浏览器右侧的下拉滑动条,拉到最后
browser.execute_script('alert("To Bottom")')#当拉到最后之后,会在浏览器上弹出“To Bottom”的提示
7、获取节点信息
7.1、获取属性
通过查看元素信息可以知道,百度网站【百度一下】按钮的id为“su”、value为“百度一下”、class为“bg s_btn”

from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
logo = browser.find_element(By.ID,'su')#根据ID的值找到【百度一下】按钮
print("【百度一下】的id为:",logo.get_attribute('id'))
print("【百度一下】的value为:",logo.get_attribute('value'))
print("【百度一下】的class为:",logo.get_attribute('class'))
输出结果:
【百度一下】的id为: su
【百度一下】的value为: 百度一下
【百度一下】的class为: bg s_btn
7.2、获取文本值

from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
logo = browser.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]')#根据XPATH方法找到元素节点
print("百度置顶消息内容:",logo.text)
输出结果:
百度置顶消息内容: 同行天下大道 共创光明未来
7.3、获取id、位置、标签名和大小
以获取百度首页的【百度一下】元素节点为例。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
input = browser.find_element(By.ID,'su')#根据ID的值找到【百度一下】按钮
print("【百度一下】的id:",input.id)#实际输出结果和get_attribute('id')的内容不一致
print("【百度一下】的位置:",input.location)#获取该节点在网页中的相对位置
print("【百度一下】的tag_name:",input.tag_name)#获取【百度一下】按钮的tagname值,通过上面的图片可知,tagname值为input
print("百度一下】的高宽:",input.size)#获取节点的大小,也就是宽和高
输出结果:
【百度一下】的id: d6c2f5f9-5057-4700-a06c-dbffe01c4192
【百度一下】的位置: {'x': 844, 'y': 188}
【百度一下】的tag_name: input
百度一下】的高宽: {'height': 44, 'width': 108}
8、延时等待
延时等待的目的是为了获取更加完整的网页源码信息,因为现在许多网页都是通过Ajax请求渲染的,如果获取网页源码的速度过快,则会造成网页源码信息缺失。隐式等待是一种设置延时等待的方法;指设置一个固定时间,如在固定时间内没有找到某一节点则抛出异常提示。隐式等待的语法为:browser.implicitly_wait(3)设置等待时间为3秒。
9、网页的前进和后退
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')#打开百度网站
browser.get('https://www.taobao.com/')#打开淘宝网站
browser.get('https://www.python.org/')#打开python网站
browser.back()#返回淘宝网站
time.sleep(1)#暂停1秒
browser.forward()#返回python网站
time.sleep(2)#暂停2秒
browser.close()#关闭浏览器
10、获取、添加、删除Cookies
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
print(browser.get_cookies())#获取cookies
browser.add_cookie({'name': 'name', 'domain': 'www.baidu.com', 'value': 'germey'})#添加cookies,以字典的形式添加
#此处的添加并不是将原cookie清空,变成我们新加的cookie;而是在原cookie基础上添加。
print(browser.get_cookies())
browser.delete_all_cookies()#删除所有的cookies
print(browser.get_cookies())
11、界面切换
我们在使用浏览器时,有时会弹出新的界面,为了在不同界面操作,这时就需要用到switch_to.window函数。
import time
from selenium import webdriver
browser = webdriver.Chrome()#创建谷歌浏览器
browser.get('https://www.baidu.com')#打开百度网页
browser.execute_script('window.open()')#新建一个网页窗口,execute_script里面的为JavaScript语句
print(browser.window_handles)#browser.window_handles会获取当前浏览器中所有界面的代码,以列表形式展示
browser.switch_to.window(browser.window_handles[1])#切换到第二个网页界面,即上面新打开的空白页
browser.get('https://www.taobao.com')#空白页浏览淘宝网站
time.sleep(1)#休眠1秒钟
browser.switch_to.window(browser.window_handles[0])#切换值百度网页的界面
browser.get('https://python.org')#将百度网页变成python网页
- 本篇笔记首先在微信公众号“宏蜘蛛”上发布,链接为:网络爬虫笔记—Selenium
—End—
参考资料
2、selenium版本跟新,使用find_element()命令_JJCY的博客-CSDN博客_更新selenium版本
3、谷歌浏览器配置chromedriver(win) - 敲代码带 - 博客园 (cnblogs.com)
4、转化到frame窗口中:browser.swicth_to_frame() - tyne0921 - 博客园 (cnblogs.com)
5、chromedriver下载与安装方法,亲测可用_zhoukeguai的博客-CSDN博客_chromedriver















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









