






网络爬虫笔记—图形验证码识别
1、什么是图形验证码
像知网注册界面的这种验证码,就是图形验证码。
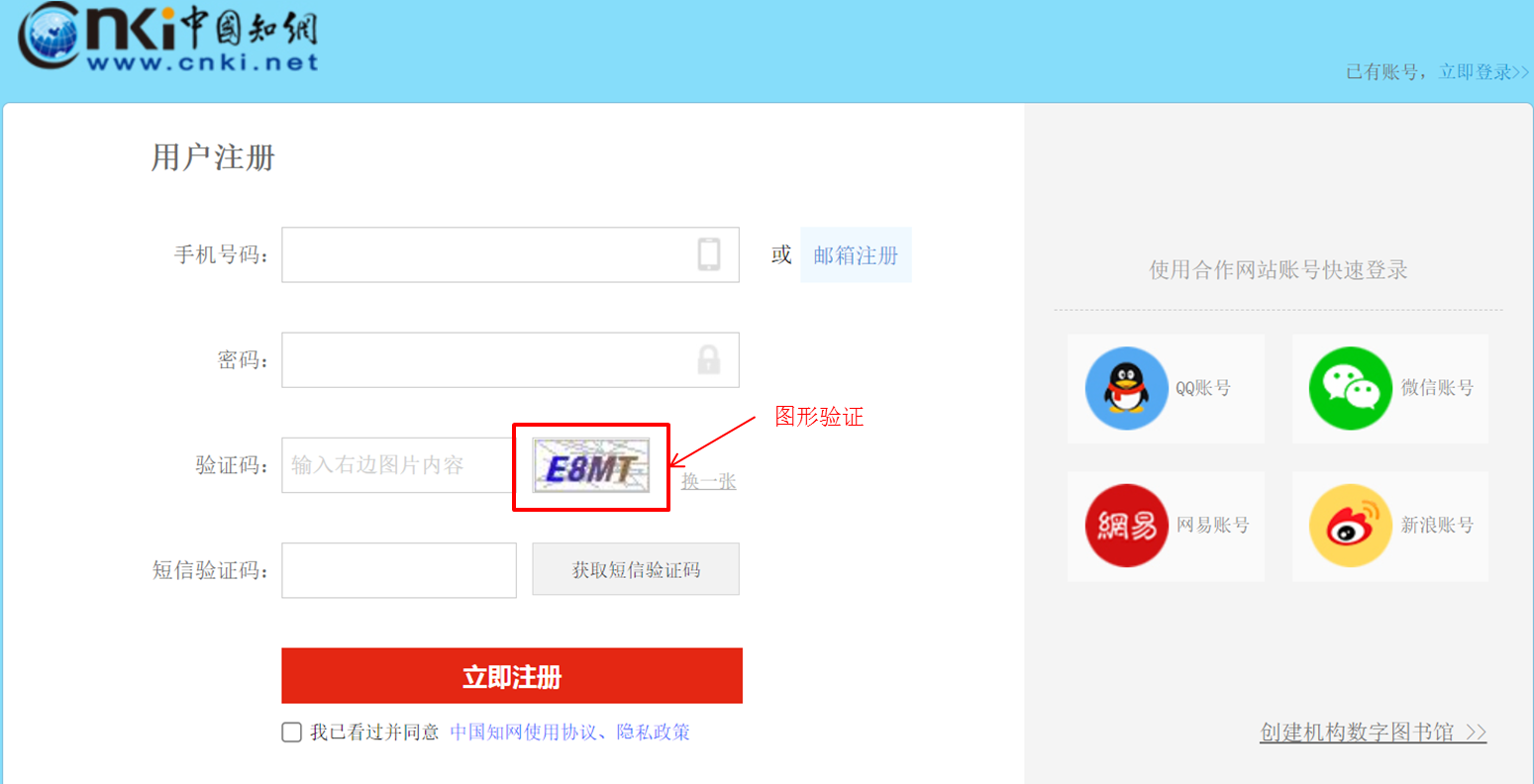
2、如何识别图形验证码
图形验证码可以利用这几年比较流行的OCR技术进行识别。OCR技术是一种图片识别技术,它可以识别图片中的文字,并将其转化为文本格式。我们在使用时,并不是自编一个OCR识别代码,而是直接使用第三方OCR识别技术。python的OCR需要使用到tesserocr库,该库不是python自带库需要进行安装,针对tesserocr库安装,大家可参考这篇文章:https://blog.csdn.net/Elom_H4/article/details/123987637。下面将以知网注册页面的验证码识别为例,进行案例的介绍。
3、知网图形验证码获取
知网图形验证码是一个动态验证码,每点击一次都会重新生成一个验证码。于是通过requests方式访问验证码链接,将不会得到登录界面显示的验证码,而是又生成了一个新的验证码。针对动态验证码的获取问题,一般可使用Selenium库操纵浏览器,然后对屏幕进行截屏,以此来获取网页的动态验证码。这一部分的内容将在后面的文章中体现,本次主要学习图形验证码的识别方法。
4、验证码识别
我们事先从知网注册网站下载了一个验证码图片,其图如下:

4.1、读取图片,直接识别
import tesserocr#OCR识别库
from PIL import Image#用于读取图片
image = Image.open("yanzhengma.png")#读取图片
result = tesserocr.image_to_text(image)#识别图片文字内容
print(result)
#输出结果:ZPBY-
读取图片后,直接识别的结果和实际值存在偏差,这时可以将图片转为灰度图片、然后再进行二值化处理,这样可以减少线条的干扰,从而识别的更加准确。
4.2、灰度和二值化处理
灰度处理,就是将彩色图片转化为黑白图片。
from PIL import Image#用于读取图片
image = Image.open("yanzhengma.png")#读取图片
image = image.convert("L")#传入L参数,代表将图片转为灰度图片
image.show()
结果输出:

与原始验证码相比,灰度图片变成了黑白无彩图片。电脑保存彩色的图片一般是三通道图片,即我们平常所说的RGB值,每一个像素点的值在0到255之间。当我们将其灰度之后,图片就会变成一个单通道图片。该单通道每一个像素点都是0到255之间的一个数,如果是0则代表是黑色,如果是255则代表是白色。二值化处理就是设置一个阈值,让灰度后的每一个像素点都与这个阈值比较,如果小于阈值就变成0,如果大于阈值就变成255,将原来的灰度图片,变成了更加黑白分明的图片,从而有利于图片的识别。
from PIL import Image#用于读取图片
image = Image.open("yanzhengma.png")#读取图片
image = image.convert("L")#传入L参数,代表将图片转为灰度图片
width = image.size[0]#获取图片的宽度
height = image.size[1]#获取图片的高度
threshold = 150#设置阈值
for h in range(0,height):
for w in range(0,width):
if image.getpixel((w,h)) < threshold:#遍历每一个像素点,并与阈值比较
image.putpixel((w,h),(0))#如果小于阈值,则像素点的值变成0(黑色)
else:
image.putpixel((w,h),(255))#如果大于阈值,则像素点的值变成255(白色)
image.show()#展示图片
结果输出:
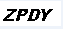
4.3、文字识别
import tesserocr#OCR识别库
from PIL import Image#用于读取图片
image = Image.open("yanzhengma.png")#读取图片
image = image.convert("L")#传入L参数,代表将图片转为灰度图片
width = image.size[0]#获取图片的宽度
height = image.size[1]#获取图片的高度
threshold = 150#设置阈值
for h in range(0,height):
for w in range(0,width):
if image.getpixel((w,h)) < threshold:#遍历每一个像素点,并与阈值比较
image.putpixel((w,h),(0))#如果小于阈值,则像素点的值变成0(黑色)
else:
image.putpixel((w,h),(255))#如果大于阈值,则像素点的值变成255(白色)
result = tesserocr.image_to_text(image)#识别图片文字内容
print(result)
#输出结果:ZPDY
灰度和二值化处理之后,后面直接调用OCR识别库就可以了,可以看到经过二值化处理之后,识别结果更加的准确。下面将三个图片放在一起,以便大家比较处理前后的变化。如果二值化处理之后的图片不清晰,大家可以通过调整阈值的方式来使图片变得清晰,减少其他线条的干扰。

- 本篇笔记首先在微信公众号“宏蜘蛛”上发布,链接为:网络爬虫笔记—图形验证码识别
—End—
参考资料
2、tesserocr_做测试的喵酱的博客-CSDN博客_tesserocr
3、python3.9 安装 tesserocr 过程 || pip install tesserocr pillow 安装失败解决方案_R874的博客-CSDN博客
4、Python之中Image的使用[putpixel]_qq_38221114的博客-CSDN博客

















 2600
2600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









