






Numpy库自学笔记(二、数组转换)
本笔记内容源于北京某大学课程课件、Numpy官方文档
数组转换与维度变换
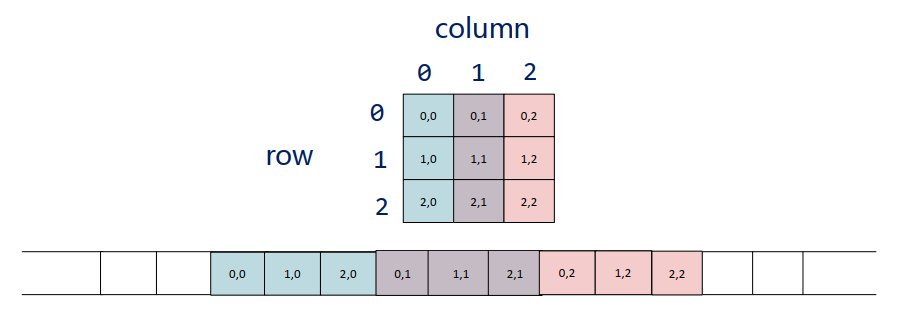
首先与要了解元素在Numpy中的排列方式,在存储高维数组时,元素仍呈线性存储,由于高维数组分行和列,因此存储方式分为行存储、列存储。
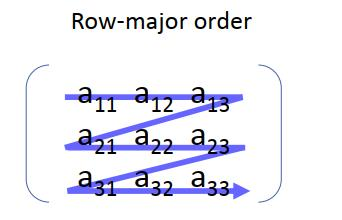

按行顺序存储,同一行的元素存储在物理位置相邻的存储单元中,如下图所示

按列顺序存储,同一列的元素存储在物理位置相邻的存储单元中
3维数组中元素的排列方式,a[0][0][0]-a[0][0][1]-a[0][0][2]-a[0][1][0]-a[0][1][1]...

数组转换
| 函数 | 介绍 |
|---|---|
| ndarray.copy (order=‘C’) | 返回原数组的副本。修改副本不会影响原数组 |
| ndarray.view (order=‘C’) | 返回原数组的视图。修改副本会影响原数组 |
| ndarray.astype (new_type, order=‘K’) | order : 可选范围为{ ‘C’ , ‘F’ , ‘A’ , ‘ K’ } 将数组转换成指定的数据类型, 原数组不变 |
| ndarray.tolist ( ) | ndarray.tolist ( ) |
ndarray.copy (order=‘C’) ,返回原数组的副本。修改副本不会影响原数组。
- order : 可选范围为{‘C’, ‘F’, ‘A’ , ‘ K’}, order 选项控制拷贝数组在内存中的存储
顺序。 - “C”表示使用类似C语言的存储方式,按行优先存储
- “F” 表示使用类似Fortran语言的存储方式,按列优先存储
- “A”表示原数组如果按照Fortran存储方式,那么”A” 为F顺序存储。否则, ”A”为C顺序。
- “K” 表示拷贝数组和原始数组的存储顺序尽可能一致。
a=np.array([[1,3,5],[7,9,4]])
b=a.copy() #默认的是‘C’
c=a
d=a[:]
e=np.copy(a)#默认为k
a[0]=0
print(a) #原元素变化时
print(b)#拷贝数组元素不变,将原数据复制到新的内存空间中,即a与b的地址不同,因此改变b不影响a,改变a不影响b
print(e)
print (f'{id(a)},{id(b)},{id(e)}')
print(c)
print(d)
print(f'{id(a)},{id(c)},{id(d)}')#c=a[:]这种方式对数组进行复制时,c和a的地址相同,当对元素进行改变时,会产生影响
#而d=a[:],d的地址不同与a的原因是d开辟了新的地址,里面的内容指向a,而不是将原数据复制到新的内存空间中,因此a改变,d也改变
[[0 0 0]
[7 9 4]]
[[1 3 5]
[7 9 4]]
[[1 3 5]
[7 9 4]]
1827768851312,1827768850592,1827768849072
[[0 0 0]
[7 9 4]]
[[0 0 0]
[7 9 4]]
1827768851312,1827768851312,1827768849792
而列表与数组的copy方式不同,需要注意的是列表中e=a[:]与数组ndarray不同
a=[1,2,3]
b=a
c=a.copy()
e=a[:]
a[0]=0
print(f'{a},{b},{c},{e}')
print(f'{id(a)},{id(b)},{id(c)},{id(e)}')
[0, 2, 3],[0, 2, 3],[1, 2, 3],[1, 2, 3]
2464546618112,2464546618112,2464546617408,2464546634752
ndarray.view (order=‘C’)
view(视图)就是我们上文所说的“开辟了新的地址,里面的内容指向原数组”
修改复制后对象,会对原数组产生影响
a=np.array([[1,3,5],[7,9,4]])
b=a.view()
b[0]=0
print(f'{a}\n{b}')
print(f'{id(a)},{id(b)}')
[[0 0 0]
[7 9 4]]
[[0 0 0]
[7 9 4]]
2464547483200,2464547483120
ndarray.astype (new_type, order=‘K’ ), order : 可选范围为{ ‘C’ , ‘F’ , ‘A’ , ‘ K’ }
将数组转换成指定的数据类型, 原数组不变。
a=np.array([1,3,5.0])
print(a)
b=a.astype('int')
print(a)#不影响原数组,因此b不是a的view
print(b)
[1. 3. 5.]
[1. 3. 5.]
[1 3 5]
ndarray.tolist ( )
- 将数组变成嵌套的列表, 原数组不变
a=np.array([[[3, 3, 7],[2, 4, 7]],[[2, 1, 2],[1, 1, 4]]])
a1=a.tolist()
print(a)
[[[3 3 7]
[2 4 7]]
[[2 1 2]
[1 1 4]]]
ndarray.item(shape)
- 按照shape, 返回指定数组的元素副本。与a[shape]类似,
但是返回的是标准Python标量而不是数组标量。
a=np.array([[[3, 3, 7],[2, 4, 7]],[[2, 1, 2],[1, 1, 4]]])
a[(1,0,1)]
1
a.item(7)#如果直接用a[7]则会报错
1
a.item((1,0,1))#shape为元组,用于定位用
1
ndarray形状转换
ndarray.reshape( new_shape, order=‘C‘) 与np.reshape (a, new_shape,order=‘C’) ,不改变数据的情况下, 按照new_shape形状, 产生一个新数组,原数组
不变
- order : 可选范围为{ ‘C’, ‘F’, ‘A’ }, 默认参数为C。
- “C”类似C语言的索引顺序读取/ 写入元素
- “F”类似Fortran语言的索引顺序读取/ 写入元素
- “A” 表示原数组是Fortran存储顺序,那么” A” 为F顺序读取/ 写入元素,否则,” A” 为C顺序
a=np.array([[1,2,3],[4,5,6]],order='F')
print(a)
print(a.reshape(3,2,order='A'))#由于是a是按列存储,则读取a的数据时,从上到下读;本写入也采用F的形式,所以按列将a的元素依次写入
print(np.reshape(a,(3,2),order='F'))
[[1 2 3]
[4 5 6]]
[[1 5]
[4 3]
[2 6]]
[[1 5]
[4 3]
[2 6]]
ndarray. resize(new_shape, refcheck=True)
- 改变原数组的形状和大小,可以缩小数组,扩大数组,重组数据不够时,使用零填补
- refcheck –引用计数检查,默认值 True,启用引用计数检查的目的是数组与另外 Python对象公共内存时,不要改变数组内存空间大小(保持数组元素数量不变)
np. resize(a, new_shape)
- 按照指定形状返回新的数组,原数组不变。可以缩小数组,
- 扩大数组,重组数据不够时,使用原数据依次填补
a=np.array([[1,2,3],[4,5,6]],order='F')
print(a)
a.resize((2,2),refcheck=False)
print(a)
a.resize((3,3),refcheck=False) #由于是按列存储,所以是这样
print(a)
a.resize((1,3),refcheck=False)
print(a)
[[1 2 3]
[4 5 6]]
[[1 2]
[4 5]]
[[1 5 0]
[4 0 0]
[2 0 0]]
[[1 4 2]]
a=np.array([[1,2,3],[4,5,6]]) #默认的存储顺序是“C”
print(a)
b=np.resize(a,(2,4))#默认按行存储,即1、2、3、4、5、6,当到第七个位置的时候,由于原数组元素不够,则再从1、2、3、4、5、6依次递补
c=np.resize(a,(2,2))
print(b)
print(c)
print(a)
[[1 2 3]
[4 5 6]]
[[1 2 3 4]
[5 6 1 2]]
[[1 2]
[3 4]]
[[1 2 3]
[4 5 6]]
ndarray.swapaxes (axis1, axis2)
np.swapaxes (a, axis1 ,axis2)
返回数组中axis1, axis2互换的数组,原数组不变
a=np.arange(24).reshape((2,3,4))
a
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Du7L0pJo-1658199130274)(attachment:image.png)]
a.swapaxes(1, 2)#相当于线性代数中的转置
array([[[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]],
[[12, 16, 20],
[13, 17, 21],
[14, 18, 22],
[15, 19, 23]]])
ndarray. flatten() #平坦化(将多维数组转换为一维数组) 原数组不变
a.flatten()#由于a为C形式存储,因此flatten后输出结果所示
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])















 3956
3956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









