







Numpy库自学笔记
本笔记内容源于北京某大学大数据课程课件、小学期课件、Numpy官方文档
文章目录
Numpy简介
NumPy( Numerical Python)是基于Python语言的一种开源的科学数值计算的第三方库,拥有高效的、节约空间的多维数组对象——ndarray以及为基于数据的计算提供大量的标准数学函数,提供线性代数、傅里叶变换、随机数生成等高级数学功能,并且提供C\C++\Fortran等语言的接口支持,便于研究。
#例子:用列表和NumPy中的数组分别计算c=a+b,可以看出利用Numpy计算更加快捷1
a1= [[1,2,3],[2,3,4]]
b1= [[6,4,10],[4,6,15]]
c1= [[0,0,0],[0,0,0]]
for i in range(2):
for j in range(3):
c1[i][j] = a1[i][j]+b1[i][j]
c1
[[7, 6, 13], [6, 9, 19]]
import numpy as np
a= np.array([[1,2,3],[2,3,4]])
b= np.array([[6,4,10],[4,6,15]])
c=a+b
c
array([[ 7, 6, 13],
[ 6, 9, 19]])
Ndarray数组的属性与创建
ndarray中的nd代表n维, ndarray代表n维数组对象,通过下面的方法进行创建。虽然ndarray(n维数组)很多调用的方法与list(列表)类似,但本质上二者不同,不过可以相互转换。
import numpy as np
np.array(object, dtype = None, order = None)
array(<class 'object'>, dtype=object)
- object通常是一个容器或迭代器,将其内容包装成一个ndarray对象
- dtype如果不指定,自动从实际数据中推断
- order:数据在内存中的排列规则,'C’为行方向(默认),'F’为列方向,这会在下文解释
数组的属性
一些检查数组属性的函数
- ndim:返回 int。表示数组的维数
- shape:返回 tuple。表示数组的尺寸,对于 n 行 m 列的矩阵,形状为(n,m)
- size:返回 int。表示数组的元素总数,等于数组形状的乘积
- dtype:返回 data-type。描述数组中元素的类型
- itemsize:返回 int。表示数组的每个元素的大小(以字节为单位)
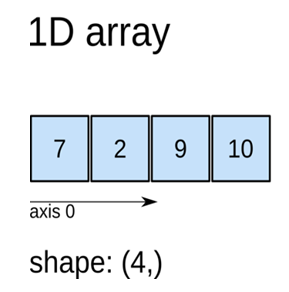
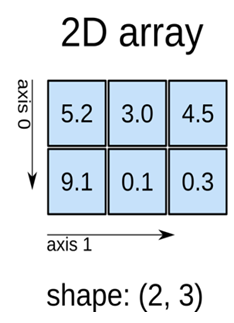
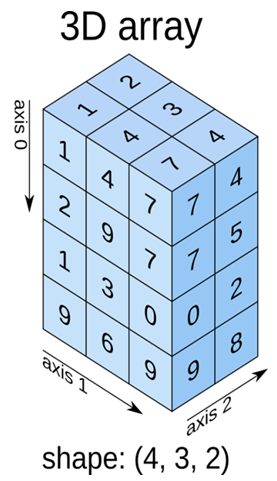
下面三个图体现出数组具有的三个属性,即数组的维度ndim,数组的形状shape,轴(axis): 标识数据的维度
一维数组为线性,从左到右看
二维数组有axis0、axis1两个轴,先读取行的数据,可见axis0有两个元素[a,b],即a对应第一行,b对应第二行a=[5.2,3.0,4.5],b=[9.1,0.1,0.3],后读取列的数据,即将二维数组拆分为多行并在一起的一维线性数组,axis1对应列的元素。当我们要查看第一行第二列的元素时,提取第一行的数据axis[0]=[5.2,3.0,4.5],后提取第2列的数据为3.0
三维数组则由多个二维数组堆叠而成,先按照axis0的方向,进行切片,产生4个二维数组,在按照二维数组读取数据的方法对数据进行读取。
 |  |  |
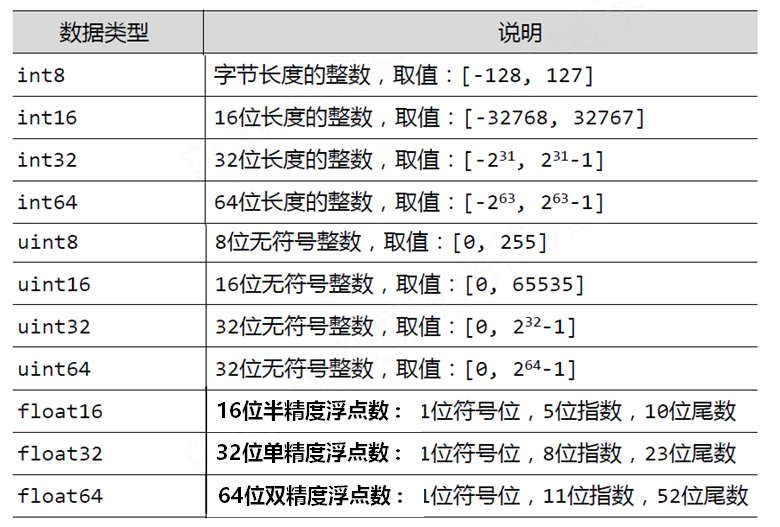
数据类型
Python语法仅支持整数、浮点数和复数3种类型,而NumPy科学计算涉及数据较多,对存储和性能都有较高要求,对元素类型精细定义,这样有助于NumPy合理使用存储空间并优化性能,也有助于程序员对程序规模有合理评估
x = np.array([1, 2, 3],dtype="int32")
y = np.array([4.0, 5, 6])
print(x.dtype, x.shape, x.ndim)
print(y.dtype, y.shape, y.ndim)
z = x + y
print(z,z.dtype)
int32 (3,) 1
float64 (3,) 1
[5. 7. 9.] float64
当拥有不同数据类型的数组进行运算时,会默认采用运算数组中的最高精度进行运算
举例创建数组
例子
| 班级 | 姓名 | 数学分析 | 高等代数 | 概率统计 |
|---|---|---|---|---|
| 一班 | 张丽 | 80 | 95 | 84 |
| 一班 | 王钰 | 90 | 86 | 85 |
| 二班 | 闵玥 | 92 | 81 | 80 |
| 二班 | 赵寒 | 83 | 79 | 74 |
#建立一维数组
np.array([80,95,84])
array([80, 95, 84])
np.array((90.,86.,85.))
array([90., 86., 85.])
np.array(['张丽', '王钰', '闵玥', '赵寒'])#U2 长度为2个Unicode字符, Unicode是计算机字符编码
array(['张丽', '王钰', '闵玥', '赵寒'], dtype='<U2')
#二维数组的建立
np. array([[80, 95, 84], [90, 86, 85]])
array([[80, 95, 84],
[90, 86, 85]])
#三维数组的建立
example1=np.array([[[80,95,84],[90,86,85]],[[92,81,80],[83,79,74]]])
#先按照班级进行切片,之后按照同学划分,再按照学科种类分列
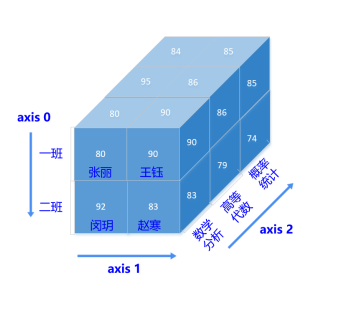
#当我们要读取一班张丽的概率统计成绩时,如下文所示
example1[0][0][2]
84
#也可以这样对数据进行读取
example1[0,0,2]
84
#看下example的shape、ndim、size
print(example1.shape)
print(example1.ndim)
print(example1.size)
(2, 2, 3)
3
12
使用常见函数创建数组
| NumPy 函 数 | 说 明 |
|---|---|
| np.ones(shape) | 根据shape生成一个全1的数组, shape是列表或元组类型 |
| np.zeros(shape) | 根据shape生成一个全0的数组, shape是列表或元组类型 |
| np.eye(n,k=0) | 创建一个n*n单位矩阵, k=0(默认值)表示主对角线,正值表示上对角线,负值表示下对角线 |
| np.full(shape,val) | 根据shape生成一个数组,每个元素值都是val |
| np.arange(n) | 用于创建一个于等差数列,类似range()函数,返回ndarray类型,元素默认从0到n-1,可以指定start, stop, step,用于整数场合 |
| np.linspace(start, stop , n) | 返回n 个在闭区间 [start, stop] 内均匀分布的数值(start, stop , n)(默认含右侧端点)用于浮点数场合 |
| np.ones_like(a) | 根据数据a的形状生成一个全1的数组 |
| np.zeros_like(a) | 根据数组a的形状生成一个全0的数组 |
| np.full_like(a,val) | 根据数组a的形状生成一个数组,每个元素值都是val |
| np.logspace(start, stop, num=50, base=10.0) | 用于创建一个于等比数列,num为样本数量,base为l底数 |
#举例
a=np.zeros((2,2,3))#默认是浮点数
print('a=',a)
b=np.ones_like(a)
print('b=',b)
c=np.full([2,2,3],9)
print('c=',c)
a= [[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
b= [[[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]]]
c= [[[9 9 9]
[9 9 9]]
[[9 9 9]
[9 9 9]]]
np.arange( )
- 创建一个一维数组
- 可以传入一个参数、两个参数或三个参数
- 1个参数: np.arange(n)生成 0 到 n - 1 的连续整数
- 2个参数: np.arange(start,stop) 生成半开区间 [start, stop) 内步长为1的等差数列
- 3个参数: np.arange([start,] stop,[step,]), 生成半开区间 [start,stop) 内的等差数列, step为步长
print(np.arange(10))
print(np.arange(2,10))
print(np.arange(1,10,3))
[0 1 2 3 4 5 6 7 8 9]
[2 3 4 5 6 7 8 9]
[1 4 7]
np.linspace( )
- np.linspace(start, stop, n)
- 返回n 个在闭区间 [start, stop] 内均匀分布的数值
- 可以不包含区间的结束点, 半开区间[start, stop),方法是在 np.linspace() 函数中将参数endpoint 设为 False
一般来说创建非整数间隔的数组,采用np.linspace( ),创建整数间隔的数组采用np.arange( )
print(np.linspace(1, 10, 7))
print(np.linspace(1,10,7,endpoint=False))
[ 1. 2.5 4. 5.5 7. 8.5 10. ]
[1. 2.28571429 3.57142857 4.85714286 6.14285714 7.42857143
8.71428571]
np.logspace(start, stop, num=50, base=10.0)
- 返回num个在闭区间 [basestart, basestop] 内按照等比方式均匀分布的数字
print(np.logspace(1, 5, 5)) #从101到105,含5个数
print(np.logspace(1, 10, 10, base=2)) #从21到210,含10个数
[1.e+01 1.e+02 1.e+03 1.e+04 1.e+05]
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
数组转换与维度变换
首先与要了解元素在Numpy中的排列方式,在存储高维数组时,元素仍呈线性存储,由于高维数组分行和列,因此存储方式分为行存储、列存储。
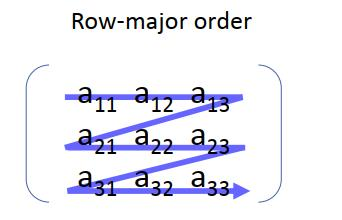

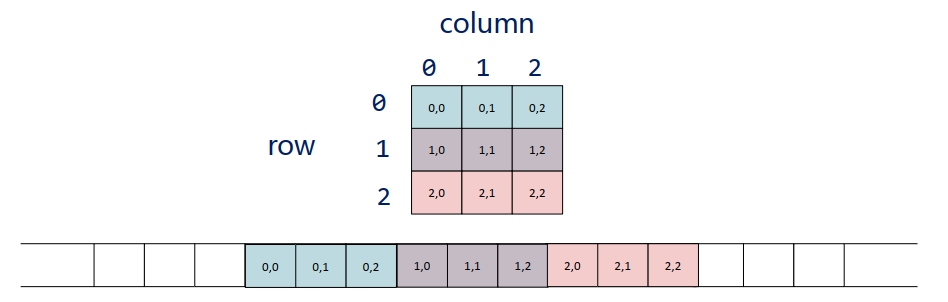
按行顺序存储,同一行的元素存储在物理位置相邻的存储单元中,如下图所示
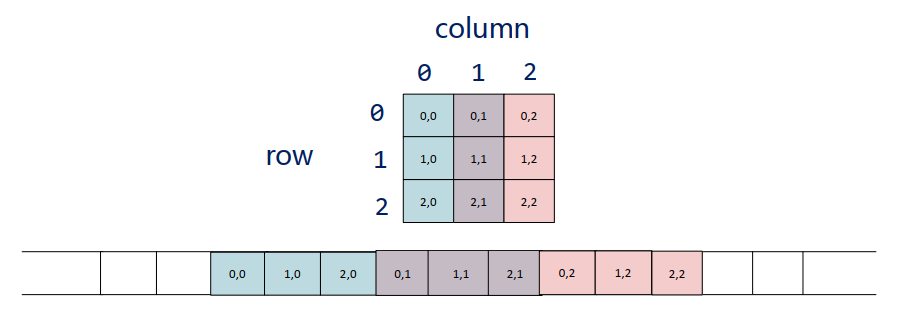
按列顺序存储,同一列的元素存储在物理位置相邻的存储单元中
3维数组中元素的排列方式,a[0][0][0]-a[0][0][1]-a[0][0][2]-a[0][1][0]-a[0][1][1]...
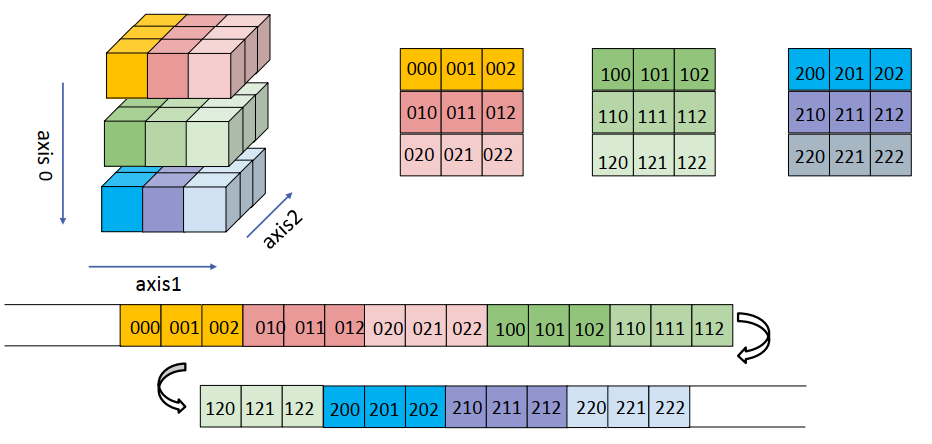
数组转换
| 函数 | 介绍 |
|---|---|
| ndarray.copy (order=‘C’) | 返回原数组的副本。修改副本不会影响原数组 |
| ndarray.view (order=‘C’) | 返回原数组的视图。修改副本会影响原数组 |
| ndarray.astype (new_type, order=‘K’) | order : 可选范围为{ ‘C’ , ‘F’ , ‘A’ , ‘ K’ } 将数组转换成指定的数据类型, 原数组不变 |
| ndarray.tolist ( ) | ndarray.tolist ( ) |
ndarray.copy (order=‘C’) ,返回原数组的副本。修改副本不会影响原数组。
- order : 可选范围为{‘C’, ‘F’, ‘A’ , ‘ K’}, order 选项控制拷贝数组在内存中的存储
顺序。 - “C”表示使用类似C语言的存储方式,按行优先存储
- “F” 表示使用类似Fortran语言的存储方式,按列优先存储
- “A”表示原数组如果按照Fortran存储方式,那么”A” 为F顺序存储。否则, ”A”为C顺序。
- “K” 表示拷贝数组和原始数组的存储顺序尽可能一致。
a=np.array([[1,3,5],[7,9,4]])
b=a.copy() #默认的是‘C’
c=a
d=a[:]
e=np.copy(a)#默认为k
a[0]=0
print(a) #原元素变化时
print(b)#拷贝数组元素不变,将原数据复制到新的内存空间中,即a与b的地址不同,因此改变b不影响a,改变a不影响b
print(e)
print (f'{id(a)},{id(b)},{id(e)}')
print(c)
print(d)
print(f'{id(a)},{id(c)},{id(d)}')#c=a[:]这种方式对数组进行复制时,c和a的地址相同,当对元素进行改变时,会产生影响
#而d=a[:],d的地址不同与a的原因是d开辟了新的地址,里面的内容指向a,而不是将原数据复制到新的内存空间中,因此a改变,d也改变
[[0 0 0]
[7 9 4]]
[[1 3 5]
[7 9 4]]
[[1 3 5]
[7 9 4]]
1827768851312,1827768850592,1827768849072
[[0 0 0]
[7 9 4]]
[[0 0 0]
[7 9 4]]
1827768851312,1827768851312,1827768849792
而列表与数组的copy方式不同,需要注意的是列表中e=a[:]与数组ndarray不同
a=[1,2,3]
b=a
c=a.copy()
e=a[:]
a[0]=0
print(f'{a},{b},{c},{e}')
print(f'{id(a)},{id(b)},{id(c)},{id(e)}')
[0, 2, 3],[0, 2, 3],[1, 2, 3],[1, 2, 3]
2464546618112,2464546618112,2464546617408,2464546634752
ndarray.view (order=‘C’)
view(视图)就是我们上文所说的“开辟了新的地址,里面的内容指向原数组”
修改复制后对象,会对原数组产生影响
a=np.array([[1,3,5],[7,9,4]])
b=a.view()
b[0]=0
print(f'{a}\n{b}')
print(f'{id(a)},{id(b)}')
[[0 0 0]
[7 9 4]]
[[0 0 0]
[7 9 4]]
2464547483200,2464547483120
ndarray.astype (new_type, order=‘K’ ), order : 可选范围为{ ‘C’ , ‘F’ , ‘A’ , ‘ K’ }
将数组转换成指定的数据类型, 原数组不变。
a=np.array([1,3,5.0])
print(a)
b=a.astype('int')
print(a)#不影响原数组,因此b不是a的view
print(b)
[1. 3. 5.]
[1. 3. 5.]
[1 3 5]
ndarray.tolist ( )
- 将数组变成嵌套的列表, 原数组不变
a=np.array([[[3, 3, 7],[2, 4, 7]],[[2, 1, 2],[1, 1, 4]]])
a1=a.tolist()
print(a)
[[[3 3 7]
[2 4 7]]
[[2 1 2]
[1 1 4]]]
ndarray.item(shape)
- 按照shape, 返回指定数组的元素副本。与a[shape]类似,
但是返回的是标准Python标量而不是数组标量。
a=np.array([[[3, 3, 7],[2, 4, 7]],[[2, 1, 2],[1, 1, 4]]])
a[(1,0,1)]
1
a.item(7)#如果直接用a[7]则会报错
1
a.item((1,0,1))#shape为元组,用于定位用
1
ndarray形状转换
ndarray.reshape( new_shape, order=‘C‘) 与np.reshape (a, new_shape,order=‘C’) ,不改变数据的情况下, 按照new_shape形状, 产生一个新数组,原数组
不变
- order : 可选范围为{ ‘C’, ‘F’, ‘A’ }, 默认参数为C。
- “C”类似C语言的索引顺序读取/ 写入元素
- “F”类似Fortran语言的索引顺序读取/ 写入元素
- “A” 表示原数组是Fortran存储顺序,那么” A” 为F顺序读取/ 写入元素,否则,” A” 为C顺序
a=np.array([[1,2,3],[4,5,6]],order='F')
print(a)
print(a.reshape(3,2,order='A'))#由于是a是按列存储,则读取a的数据时,从上到下读;本写入也采用F的形式,所以按列将a的元素依次写入
print(np.reshape(a,(3,2),order='F'))
[[1 2 3]
[4 5 6]]
[[1 5]
[4 3]
[2 6]]
[[1 5]
[4 3]
[2 6]]
ndarray. resize(new_shape, refcheck=True)
- 改变原数组的形状和大小,可以缩小数组,扩大数组,重组数据不够时,使用零填补
- refcheck –引用计数检查,默认值 True,启用引用计数检查的目的是数组与另外 Python对象公共内存时,不要改变数组内存空间大小(保持数组元素数量不变)
np. resize(a, new_shape)
- 按照指定形状返回新的数组,原数组不变。可以缩小数组,
- 扩大数组,重组数据不够时,使用原数据依次填补
a=np.array([[1,2,3],[4,5,6]],order='F')
print(a)
a.resize((2,2),refcheck=False)
print(a)
a.resize((3,3),refcheck=False) #由于是按列存储,所以是这样
print(a)
a.resize((1,3),refcheck=False)
print(a)
[[1 2 3]
[4 5 6]]
[[1 2]
[4 5]]
[[1 5 0]
[4 0 0]
[2 0 0]]
[[1 4 2]]
a=np.array([[1,2,3],[4,5,6]]) #默认的存储顺序是“C”
print(a)
b=np.resize(a,(2,4))#默认按行存储,即1、2、3、4、5、6,当到第七个位置的时候,由于原数组元素不够,则再从1、2、3、4、5、6依次递补
c=np.resize(a,(2,2))
print(b)
print(c)
print(a)
[[1 2 3]
[4 5 6]]
[[1 2 3 4]
[5 6 1 2]]
[[1 2]
[3 4]]
[[1 2 3]
[4 5 6]]
ndarray.swapaxes (axis1, axis2)
np.swapaxes (a, axis1 ,axis2)
返回数组中axis1, axis2互换的数组,原数组不变
a=np.arange(24).reshape((2,3,4))
a
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RXS7ftf9-1658133917616)(attachment:image.png)]
a.swapaxes(1, 2)#相当于线性代数中的转置
array([[[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]],
[[12, 16, 20],
[13, 17, 21],
[14, 18, 22],
[15, 19, 23]]])
ndarray. flatten() #平坦化(将多维数组转换为一维数组) 原数组不变
a.flatten()#由于a为C形式存储,因此flatten后输出结果所示
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
切片和索引
索引
- 一维数组索引: obj 是整数(从0开始计数,或者从-1开始计数)
- 多维数组索引:多维数组每个维度(轴)可以有一个索引值,索引值之间用逗号分隔,a[1,1,1]与a[1][1][1]所表达的意思是一样的
a = np.arange(9) #[0, 1, 2, 3, 4, 5, 6, 7, 8]
print(f'{a[8]},{a[-1]}')
8,8
b = a.reshape(3,3)
print(f'{b}\n{b[1,2]}\n{b[1][2]}')
[[0 1 2]
[3 4 5]
[6 7 8]]
5
5
c=np.array ([[[80,95,84],[90,86,85]],[[92,81,80],[83,79,74]]])
c[1, 0, 2]
80
切片
切片的下标基本格式[start🔚step],生成一个等差数列
- start是下标起始值(包括它)
- end 是下标终止值(不包括它) [:-1]取全部元素,但不包括最后一个值
- step是步长,默认值为1
- start,end,step可以任意省略
多维数组切片:在每一个维度(轴)上都可以进行切片
- 一维数组的切片下标格式可以应用到多维数组的每个维度上
- 每个维度上的切片下标之间用逗号分隔
- 返回多维数组的子数组视图( view)——对此视图的修改会反应在原数据上
- 如果提供的切片下标数少于轴数,则将丢失的切片视为完整切片
a = np.arange(9).reshape(3,3)
a
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
a[1:3]#对第2行、第三行进行切片
array([[3, 4, 5],
[6, 7, 8]])
b=a[1:3]
b[0,0]=10
a#与列表不同的是,数组的切片是视图,修改会对原数组产生影响
array([[ 0, 1, 2],
[10, 4, 5],
[ 6, 7, 8]])
a[:,0::2]#举例步长的使用方法
array([[ 0, 2],
[10, 5],
[ 6, 8]])
布尔索引
对于布尔型索引,我们可以使用逻辑参数(而不是确切的索引值)选择元素,例如,假设有一个 10,000 x 10,000 ndarray,其中包含从 1 到
15,000 的随机整数,我们只想选择小于 20 的整数
x = np.arange(25).reshape(5,5)
x>10
array([[False, False, False, False, False],
[False, False, False, False, False],
[False, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
x[x>10]
array([11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24])
数组的基本运算
a=np.arange(3)+5
a
array([5, 6, 7])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ARo9CbD-1658133917617)(attachment:image.png)]
x1=np.arange(12).reshape(3,4)
x2=np.array([1,2,3,4])
print(x1)
print(x2)
print(x1+x2)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[1 2 3 4]
[[ 1 3 5 7]
[ 5 7 9 11]
[ 9 11 13 15]]
数组的运算了解其广播特性
满足以下条件之一,数组可以广播:
- 两个数组的后缘维度,即从末尾开始算起的维度长度相同
- 数组的一个轴的长度为1
- 广播主要发生在两种情况,一种是两个数组的维数不相等,但是它们的后缘维度的轴长相符,另外一种是有一方的长度为1
- 广播会在缺失和(或)长度为1的维度上进行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VfVp0KMR-1658133917617)(attachment:image.png)]
x1=np.arange(12).reshape(3,4)
x2=np.array([[1,2,3,4],[5,6,7,8]])
print(x1+x2)#这样就会报错,数组的一个轴的长度为1才可以符合广播的条件
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-6-75bed88e53fd> in <module>
1 x1=np.arange(12).reshape(3,4)
2 x2=np.array([[1,2,3,4],[5,6,7,8]])
----> 3 print(x1+x2)#这样就会报错,数组的一个轴的长度为1才可以符合广播的条件
ValueError: operands could not be broadcast together with shapes (3,4) (2,4)
x1=np.arange(12).reshape(3,4)
x2=x1*x1 #对应位置元素相乘,不是矩阵相乘
print(x1)
print(x2)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 1 4 9]
[ 16 25 36 49]
[ 64 81 100 121]]
NumPy通用函数(ufunc)
ufunc是universal function的缩写,它是一种对ndarray中的数据执行元素级运算的函数。
NumPy内置得许多ufunc函数都是在C语言级别实现的,因此它们的计算速度非常快。
一元函数
| NumPy函数 | 说 明 |
|---|---|
| np.abs( ) | 计算数组各元素(整数)的绝对值 |
| np.fabs( ) | 计算数组各元素(浮点数)的绝对值 |
| np.sign( ) | 计算数组各元素的符号值, 1(正数),0(零),-1(负数) |
| np.ceil( ) | 计算数组各元素的ceiling值,即大于等于该值的的最小整数 |
| np.floor( ) | 计算数组各元素的floor值,即小于等于该值的的最大整数 |
| np.rint( ) | 计算数组各元素的四舍五入值到最接近的整数,保留dtype |
| np.round( ) | 计算元素四舍五入到指定精度 |
| np.power(n,m) | 计算 n^m |
| np.sqrt(x) | 计算各元素的算术平方根 |
| np.square(x) | 计算各个元素的平方,x2 |
| np.exp(x) | 计算数组各元素的指数值 |
| np.log( ), np.log2( ),np.log10( ), np.log1p(x) | 分别计算数组各元素的自然对数、 2为底对数和10为底的对数, log(1+x) |
| np.sin( ), np.sinh( ),np.cos( ), np.cosh( ),np.tan( ), np.tanh( ) | 计算数组各元素的普通型和双曲线三角函数 |
| np.arcsin( ), np.arcsinh( ),np.arccos( ), np.arccosh( ),np.arctan( ), np.arctanh( ) | 计算数组各元素的普通型和双曲线反三角函数 |
二元函数
| NumPy函数 | 说 明 |
|---|---|
| np.add(x,y), np.subtract(x,y),np.multiply(x,y),np.divide(x,y), np.power(x,y) | 两个数组的对应元素进行运算+, - , * , /, ^ |
| np.greater(x,y), np.less(x,y),np.greater_equal(x,y),np.less_equal(x,y),np.equal, np.not_equal(x,y) | 逐个元素比较运算>, <, >=, <= , ==, !=,返回布尔值数组 |
| np.maximum(x,y), np.fmax(x,y)np.minimum(x,y), np.fmin(x,y) | 元素级的最大值/最小值计算 |
| np.mod(x,y) | 元素级的模运算 |
随机函数
随机数函数在NumPy的random模块中, np.random.函数名( )
| 函数名 | 解释 |
|---|---|
| seed(s) | 随机种子, s是给定的种子值 |
| rand(d0,d1,…dn) | 生成[0,1) 均匀分布随机数的数组,根据d0,d1,…dn确定数组的形状 |
| randn(d0,d1,…dn) | 生成[0,1)标准正态分布的随机数数组,根据d0,d1,…dn确定数组的形状 |
| randint(low,high=None, size=None,dtype) | 生成范围是[low,high)的随机整数数组, 根据size确定数组形状 |
| uniform(low,high,size) | 生成 [low,high) 具有均匀分布的随机数数组,size为形状 |
| binomial(n,p,size) | 生成具有二项分布的随机数数组, size为形状 |
| normal(loc,scale,size) | 生成具有正态分布的随机数数组, loc为均值,scale为标准差, size为形状 |
| chisquare(df,size) | 产生卡方分布的随机数数组, df为自由度,size为形状 |
| poisson(lam,size) | 产生具有泊松分布的数组, lam为随机发生率,size为形状 |
| choice(a,size=None, replace=True,p=None]) | 从一维数组a中以概率p抽取元素,形成size形状 的新数组, replace=True有放回的抽样 |
#seed()中的参数被设置了之后,np.random.seed()可以按顺序产生一组固定的数组,如果使用相同的seed()值,则每次生成的随机数都相同。
np.random.seed(1)
L1 = np.random.randn(3, 3)
np.random.seed(1)
L2 = np.random.randn(3, 3)
print(L1)
print(L2)
[[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]
[ 1.74481176 -0.7612069 0.3190391 ]]
[[ 1.62434536 -0.61175641 -0.52817175]
[-1.07296862 0.86540763 -2.3015387 ]
[ 1.74481176 -0.7612069 0.3190391 ]]
np.random.rand(3,3)
array([[0.02738759, 0.67046751, 0.4173048 ],
[0.55868983, 0.14038694, 0.19810149],
[0.80074457, 0.96826158, 0.31342418]])
np.random.uniform(0,10,(3,3))
array([[6.92322616, 8.76389152, 8.94606664],
[0.85044211, 0.39054783, 1.6983042 ],
[8.78142503, 0.98346834, 4.21107625]])
dr=np.random.choice([0,1,2,3,4,5,6,7]) #随机选取八个数字之一
dr
1
线性代数
NumPy中多维数组的乘法运算,默认情况下是对应位置元素相乘,不是矩阵相乘,NumPy库提供了matrix类,使用matrix类创建矩阵对象,它们的加减乘除运算采用矩阵方式计算
• 建立矩阵用np.matrix(对象)函数 或者np.mat(对象)函数
• 对象类型为数组、列表、元组、字符串
• 数组与矩阵相互转换 np.asmatrix( ) ,np. asarray( )
x1=np.array([[1,2,3],[4,5,6],[7,8,9]])
x2=np.matrix(x1)
x2
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
x2*x2
matrix([[ 30, 36, 42],
[ 66, 81, 96],
[102, 126, 150]])
x1=np.asarray(x2)
x1
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
x1*x1
array([[ 1, 4, 9],
[16, 25, 36],
[49, 64, 81]])
不是matrix类
| NumPy函数 | 说 明 |
|---|---|
| np.dot(x,y) | 计算两个数组的点积 |
| np.transpose(x,axes) .T | 数组转置 |
| np.diag(x) | 以一维数组的形式返回方阵的对角线(或非对角线)元素或将一维数组转换为方阵(非对角线元素为0) |
| np.trace(x) | 计算数组对角线元素的和 |
x=np.array([[[1,2],[3,2]],[[4,2],[5,4]],[[6,4],[5,2]]])
print(x)
print(x.T)
[[[1 2]
[3 2]]
[[4 2]
[5 4]]
[[6 4]
[5 2]]]
[[[1 4 6]
[3 5 5]]
[[2 2 4]
[2 4 2]]]
NumPy.linalg (linear algebra) 线性代数模块,格式: np.linalg.函数名()
| 函 数 名 | 说 明 |
|---|---|
| eig(x) | 计算数组的特征值和特征向量 |
| det(x) | 计算数组的行列式,数组的最后两个维度必须是方阵 |
| inv(x) | 矩阵的逆, x是方阵,且, det(x)≠0 |
| svd(x) | 计算奇异值分解 |
| solve(a,b) | 求解线性方程组Ax=b,其中A为一个方阵 |
| matrix_power | (a,n) 矩阵的n次幂,其中a可以是数组或者矩阵 |
x=np.array([[1,2,3],[2,3,4],[5,6,7]])
x
array([[1, 2, 3],
[2, 3, 4],
[5, 6, 7]])
x1=np.linalg.eig(x)
x1
(array([ 1.20000000e+01, -1.00000000e+00, -8.40398639e-17]),
array([[ 0.30996521, 0.66666667, 0.40824829],
[ 0.44280744, 0.33333333, -0.81649658],
[ 0.84133414, -0.66666667, 0.40824829]]))
x1=np.linalg.eig(x)[0]#提取特征值
x1
array([ 1.20000000e+01, -1.00000000e+00, -8.40398639e-17])
a=np.array([[1,2,3],[4,5,6]])
print(np.cumsum(a))
[ 1 3 6 10 15 21]
统计函数
统计函数由Numpy直接提供, Numpy.函数名()
| 函 数 名 | 说 明 |
|---|---|
| sum(a,axis=None) | 根据给定轴axis,计算数组a相关元素之和 |
| mean(a,axis=None) | 根据给定轴axis,计算数组a相关元素的算术平均值 |
| std(a,axis=None),var(a,axis=None) | 根据给定轴axis,计算相关元素的标准差、方差 |
| min(a,axia=None),max(a,axis=None) | 根据给定轴axis,计算数组a中元素的最小值 |
| median(a,axis=None) | 根据给定轴axis,计算数组a中元素的中位数 |
| ptp(a,axis=None) | 根据给定轴axis,计算数组a中元素的最大值与最小值的差 |
| average(a,axis=None,weights=None) | 根据给定轴axis,计算数组相关元素的加权平均值 |
| cumsum(a,axis=None) | 根据给定轴axis,所有元素的累计求和 |
| cumprod(a,axis=None) | 根据给定轴axis,所有元素的累计连乘 |
| percentile(a,q,axis) | 根据给定轴axis,计算数组a相关元素的百分比分位数 |
a=np.array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39]],
[[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49],
[50, 51, 52, 53, 54],
[55, 56, 57, 58, 59]]])
np.average(a, axis=0) #对三维数组中的第一个轴进行求平均,axis0[0]、axis0[1]、axis0[2]代表着第一、二、三个二维矩阵,对这三个二维数组各元素对应位置求平均,最终会得到一个二维矩阵
#也就是对三个二维数组相同位置上的书求平均
array([[20., 21., 22., 23., 24.],
[25., 26., 27., 28., 29.],
[30., 31., 32., 33., 34.],
[35., 36., 37., 38., 39.]])
np.average(a, axis=1)#axis1[0]....代表着第第一、二、三、四个一维矩阵,则分别对axis0[0]、axis0[1]、axis0[2]中的四个一维数组相对应的位置求平均
array([[ 7.5, 8.5, 9.5, 10.5, 11.5],
[27.5, 28.5, 29.5, 30.5, 31.5],
[47.5, 48.5, 49.5, 50.5, 51.5]])
np.average(a, axis=2)#axis2则是对一维数组的所有元素求一个均值,每个二维数组有四个一维数组,因此有四个值
array([[ 2., 7., 12., 17.],
[22., 27., 32., 37.],
[42., 47., 52., 57.]])
np.average(a)#什么都不带,对所有元素求均值
29.5















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









