







动手学深度学习
目标函数和优化算法
目标函数
机器学习可以是从“经验中学习”,进而提高效能,但我们如何将效能转化为客观实在的量,即定义模型的优劣程度的度量呢?这些度量我们可以称之为目标函数,可以用损失函数(loss function,或cost function )进行表示,当该函数的值越低时,则代表效果越好,通过学习来将损失函数降到最低。当然也可以定义越优化,函数值越高的函数。

通常,损失函数是根据模型参数定义的,并取决于数据集。 有的数据集为了训练,称为训练数据集(training dataset) ,有的数据集为了测试,称为测试数据集(test dataset )。通过在训练数据集训练,我们可以获得模型参数,并在测试数据集验证,前者相当于模拟考试,后者想到与真正的考试,模拟考分数高不代表做真题就一定得高分,当⼀个模型在训练集上表现良好,但不能推⼴到测试集时,我们说这个模型是**“过拟合”(overfitting)**的。
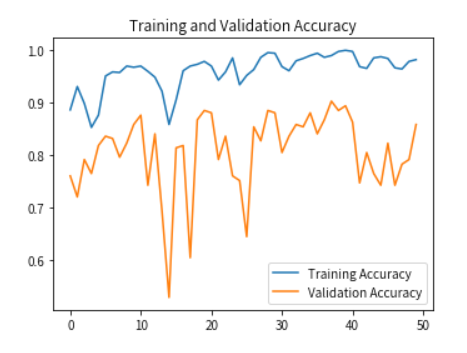
优化算法
通过优化算法可以搜索出最佳参数,可以理解为不断从“经验中学习”。多流⾏的优化算法通常基于⼀种基本⽅法-梯度下降(gradient descent),对各个参数进行检查,向减少损失的方向上优化参数。
了解各种机器学习的问题
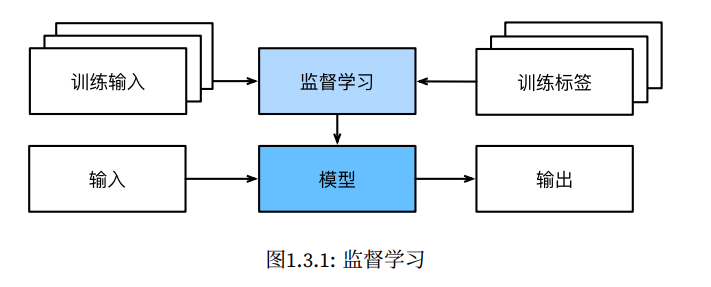
监督学习
每个“特征-标签”对都称为⼀个样本(example),利用这些样本得到一个模型,能够将任何输⼊特征映射到标签,判断出输入的样本在大概率的情况下是什么,从而实现预测的目的。
举⼀个具体的例⼦:假设我们需要预测患者是否会⼼脏病发作,那么观察结果“⼼脏病发作”或“⼼脏病没有发作”将是我们的标签。输⼊特征可能是⽣命体征,如⼼率、舒张压和收缩压。当训练好一个模型后,我们输入一个人的心率、舒张压和收缩压,就可以判断他心脏病有没有发作。
回归
回归(regression)是最简单的监督学习任务之⼀ ,当标签是数值时,就可以用到回归。我们的目标是⽣成⼀个模型,它的预测非常接近实际标签值 ,李沐老师举了一个很生动形象的例子来介绍什么是回归。
例如,你让⼈修理了排⽔管,你的承包商花了3个⼩时清除污⽔管道中的污物,然后他寄给你⼀张350美元的账单。⽽你
的朋友雇了同⼀个承包商两个⼩时,他收到了250美元的账单。如果有⼈请你估算清理污物的费⽤,你可以假
设承包商有⼀些基本费⽤,然后按⼩时收费。如果这些假设成⽴,那么给出这两个数据样本,你就已经可以
确定承包商的定价结构:每⼩时100美元,外加50美元上⻔服务费。
分类
识别手写字符其实是一个分类问题,将图像中的字符分为{0,1,2…a,b,c…} 。但分类中有一个很关键的问题,我们称之为层次分类(hierarchical classification) ——即宁愿错误地分⼊⼀个相关的类别,也不愿错误地分⼊⼀个遥远的类别 。
在动物分类的应⽤中,把⼀只狮⼦狗误认为雪纳瑞可能不会太糟糕。但如果我们的模型将狮⼦狗与恐⻰混淆,就滑稽⾄极了。
而且分类模型中识别每种类别错误的严重性是不等的,当我们在识别一个蘑菇是否为毒蘑菇时,尽管模型判断它80%的概率不是,即只有20%的概率是,我们应该如何做决策呢?

在这种情况下,食用蘑菇造成的损失为0.2 × ∞ + 0.8 × 0 = ∞,⽽丢弃蘑菇的损失为0.2 × 0 + 0.8 × 1 = 0.8,显然不食用会更划算一点.
搜索与推荐系统
比如在使用浏览器搜索内容时,搜索结果的排序也⼗分重要,我们的学习算法需要输出有序的元素⼦集。换句话说,如果要求我们输出字⺟表中的前5个字⺟,返回“A、 B、 C、 D、 E”和“C、 A、 B、 E、 D”是不同的。 推荐系统也是类似的,通过算法,根据用户的评分来合理推荐书籍.
序列学习
如果输⼊是连续的,我们的模型可能就需要拥有“记忆”功能,通过前一帧或前一段视频或音频的信息资料,来对之后的内容进行预测.
无监督学习
- 聚类(clustering)问题: 没有标签的情况下,对数据进行分类,如给定⼀组照⽚,我们能把它们分成⻛景照⽚、狗、婴⼉、猫和⼭峰的照⽚.
- 主成分分析(principal component analysis)问题: 通过少量的参数,来描述事务的属性,⽐如,⼀个球的运动轨迹可以⽤球的速度、直径和质量来描述。再⽐如,裁缝们已经开发出了⼀⼩部分参数,这些参数相当准确地描述了⼈体的形状,以适应⾐服的需要。
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题: 例如,如果我们有关于房价、污染、犯罪、地理位置、教育和⼯资的⼈⼝统计数据,我们能否简单地根据经验数据发现它们之间的关系?
- ⽣成对抗性⽹络(generative adversarial networks):为我们提供⼀种合成数据的⽅法 , 检查真实和虚假数据是否相同
深度学习
在深度学习中,模型用到了许多“层”的转换,每⼀层提供⼀个层次的表示.
例如,靠近输⼊的层可以表⽰数据的低级细节,⽽接近分类输出的层可以表⽰⽤于区分的更抽象的概念。由于表⽰学习(representation learning)⽬的是寻找表⽰本⾝,因此深度学习可以称为“多级表⽰学习”。
在计算机视觉领域,可以将Canny边缘检测器 与建⽴机器学习模型 合并到一起,而不是将其单独操作,提高了效率.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









