







本文采用多变量输入多变量输出LSTM进行了双色球的号码预测,预测的是2023年10月28日的双色球号码,明日开奖,一起期待吧。
下面是人工智障的实现代码
首先需要爬取双色球的历史数据,本文爬取了2003年至今的双色球开奖号码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#爬取2003年2月23日至今的双色球开奖号码
import requests
import os
from bs4 import BeautifulSoup
def download(url,page):
html = requests.get(url).text
soup = BeautifulSoup(html,'html.parser')
list = soup.select('div.ball_box01 ul li')
ball = []
for li in list:
ball.append(li.string)
write_to_excel(page,ball)
print(f"第{page}期开奖结果录入完成")
def write_to_excel(page,ball):
f = open('C:/Users/kaiyang/Desktop/blog/彩票/双色球开奖结果.csv','a',encoding='utf_8_sig')
f.write(f'第{page}期,{ball[0]},{ball[1]},{ball[2]},{ball[3]},{ball[4]},{ball[5]},{ball[6]}\n')
f.close()
def turn_page():
url = "http://kaijiang.500.com/ssq.shtml"
html = requests.get(url).text
soup = BeautifulSoup(html,'html.parser')
pageList = soup.select("div.iSelectList a")
for p in pageList:
url = p['href']
page = p.string
download(url,page)
def main():
if(os.path.exists('双色球开奖结果.csv')):
os.remove('双色球开奖结果.csv')
turn_page()
if __name__ == '__main__':
main()
然后就要定义人工智障LSTM的网络结构同时对其进行训练。
- 网络结构
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
# 自定义数据集类
class CustomDataset(Dataset):
def __init__(self, csv_file, n_steps):
self.data = pd.read_csv(csv_file)
self.data = self.data.iloc[:, 1:].values
self.data = self.data.astype('float32')
self.n_steps = n_steps
# 数据标准化
self.data[:,0:6]=self.data[:,0:6]/33.0;
self.data[:,6:7]=self.data[:,6:7]/16.0;
def __len__(self):
return len(self.data) - self.n_steps
def __getitem__(self, idx):
X = self.data[idx:idx+self.n_steps]
y = self.data[idx+self.n_steps]
sample = {'X': X, 'y': y}
return sample
# 自定义网络类
class LSTMNet(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size,device):
super(LSTMNet, self).__init__()
self.hidden_size = hidden_size
self.device=device
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(self.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
- 训练并保存模型
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
from model import CustomDataset,LSTMNet
def main():
for n_steps in range(5,35,5):
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义超参数
input_size = 7
hidden_size = 128
num_layers = 3
output_size = 7
learning_rate = 0.0001
num_epochs = 10
batch_size = 32
# 创建数据集和数据加载器
dataset = CustomDataset('C:/Users/kaiyang/Desktop/blog/彩票/data.csv', n_steps)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 实例化网络
model = LSTMNet(input_size, hidden_size, num_layers, output_size,device).to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss()
# criterion=nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
LOSS=[];
total_step = len(dataloader)
for epoch in range(num_epochs):
loss_ave=[];
for i, data in enumerate(dataloader):
# inputs = torch.tensor(data['X']).float().to(device)
# labels = torch.tensor(data['y']).float().to(device)
inputs = data['X'].float().to(device)
labels = data['y'].float().to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_ave.append(loss.item())
if (i+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
LOSS.append(np.mean(loss_ave))
# plt.figure()
# plt.plot(LOSS)
# plt.show()
model.eval()
with torch.no_grad():
test_data = dataset.__getitem__(0)
test_input = torch.tensor(test_data['X']).unsqueeze(0).float().to(device)
true_output = test_data['y']
predicted_output = model(test_input).squeeze().cpu().numpy()
temp1 = 33.0*true_output[0:6]
out1=np.clip(temp1, 1, 33) # 限制在指定范围内
print(out1)
temp2=16.0*true_output[6:7]
out2=np.clip(temp2, 1, 16) # 限制在指定范围内
true_output = np.concatenate((out1,out2))
true_output = np.round(true_output) # 四舍五入到最近的整数
temp1 = 33.0*predicted_output[0:6]
out1=np.clip(temp1, 1, 33) # 限制在指定范围内
temp2=16.0*predicted_output[6:7]
out2=np.clip(temp2, 1, 16) # 限制在指定范围内
predicted_output = np.concatenate((out1,out2))
predicted_output = np.round(predicted_output) # 四舍五入到最近的整数
print("True Output:", true_output)
print("Predicted Output:", predicted_output)
# 保存模型
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}, '{}day_model.pth'.format(n_steps))
if __name__ == '__main__':
main()
这里分别采用5天、10天、15天、20天、25天、30天的数据进行了预测,发现区别不是很大
最后输入最近的开奖号码,对未来的开奖号码进行预测
import torch.optim as optim
import pandas as pd
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
from model import CustomDataset,LSTMNet
import torch
import torch.nn as nn
from model import LSTMNet,CustomDataset
def main():
for n_steps in range(5,35,5):
# 加载模型
input_size = 7
hidden_size = 128
num_layers = 3
output_size = 7
learning_rate = 0.0001
num_epochs = 10
batch_size = 32
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTMNet(input_size, hidden_size, num_layers, output_size,device).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 加载模型的权重参数和优化器状态
checkpoint = torch.load('{}day_model.pth'.format(n_steps))
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 测试模型
dataset = CustomDataset('C:/Users/kaiyang/Desktop/blog/彩票/data.csv', n_steps)
model.eval()
with torch.no_grad():
csv_file='C:/Users/kaiyang/Desktop/blog/彩票/data.csv'
data = pd.read_csv(csv_file)
data = data.iloc[-n_steps:, 1:].values
data = data.astype('float32')
print("Input:", data)
# 数据标准化
data[:,0:6]=data[:,0:6]/33.0;
data[:,6:7]=data[:,6:7]/16.0;
test_input = torch.tensor(data).unsqueeze(0).float().to(device)
predicted_output = model(test_input).squeeze().cpu().numpy()
print("Predicted Output:", predicted_output)
temp1 = 33.0*predicted_output[0:6]
out1=np.clip(temp1, 1, 33) # 限制在指定范围内
temp2=16.0*predicted_output[6:7]
out2=np.clip(temp2, 1, 16) # 限制在指定范围内
predicted_output = np.concatenate((out1,out2))
predicted_output = np.round(predicted_output) # 四舍五入到最近的整数
print("Predicted Output:", predicted_output)
header = ['green1', 'green2', 'green3', 'green4', 'green5', 'green6', 'red']
predicted_output=np.reshape(predicted_output,(1,7))
df = pd.DataFrame(predicted_output)
df.to_csv('predict.csv', mode='a', header=False, index=False)
if __name__ == '__main__':
main()
预测号码
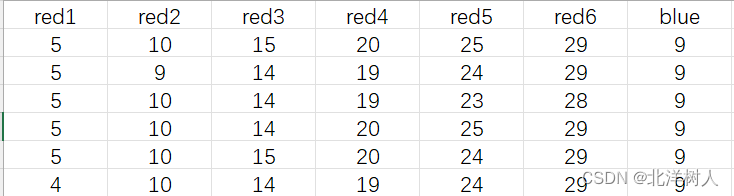
预测果然很智障,当然也和网络设计的有关,或者数据本来就是随机的数据,当然无法学习到什么。明天就是见证奇迹的时刻了。

















 3808
3808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









