







目录
八、New Results & Demo with DALL-E Mega
前言:
本文代码节选与修改自:GitHub - adymaharana/storydalle
论文地址:https://arxiv.org/pdf/2209.06192.pdf
简介:将预训练的T2I的Transformer(DALLE)适应于可视化故事延续
特别的是,把DALLE改成适应story的输入和图片序列的输出后,为了增强可视化的连贯性和未见场景,作者修改了目标任务,即在story的基础上,还要输入一个初始图片作为起始信息,再生成对应的story的可视化,也就是StoryContinuation。虽然好像确实效果好了,但好像已经比原先任务简单了啊哈哈。
摘要:
最近的文本生成图像任务中,出现了很多大型的预训练的Transformer,表现出了出色的文本生成图像的能力。但是这些图像并不适应于故事可视化,故事可视化要求给定标题序列,生成一系列图片。
因此,我们首先提出了故事延续的任务,生成的视觉故事以源图像为条件,允许更好地泛化到有新角色的叙事
由于故事中图像之间需要连续性和明确的叙述,因此很难从头开始收集大规模数据集来训练大型模型。因此,我们建议利用文本-图像合成模型预先训练的知识来克服低资源场景,并改进故事延续的生成。
最后,我们用特定于任务的模块改进了预训练的T2I生成模型,a)序列图像生成,b)从初始图像复制相关元素。
然后,我们还探索了模型的微调,包括基于prompt的训练。
本文还又收集了一个新的数据集DiDeMoSV
本文还开发了基于生成对抗网络(GAN)的故事延续模型StoryGANc(应该是修改自StoryGAN吧),StoryDALL-E与其比较来演示我们方法的优点。
一、Introducation
...
我们需要去微调预训练模型,比如DALLE。为此,我们首先用额外的层“改造”模型,从初始场景复制相关的输出。然后,我们引入了一个用于生成故事嵌入的自注意块,在生成每个帧时提供故事的全局语义上下文。我们将这种方法命名为storyDALLE,并与基于GAN的模型也进行改造为StoryGANc进行比较。
我们还探讨了参数高效的提示调优框架,并引入了一个由任务特定的嵌入组成的提示,以引导预先训练的模型为目标域生成可视化。在这个模型的prompt调优版本的训练过程中,预先训练的权重被冻结,新参数从头学习,这既节省时间又节省内存。
-- 我们提出了一个新的任务: story continuation
-- 我们引入了StoryDALLE,一个适应于story continuation的预训练transformer,我们还改造了初始的StoryGAN,将StoryGANc与StoryDALLE比较
-- 我们将进行了比较实验和消融实验,证明StoryDALLE要比StoryGANc在三个数据集上的表现都要好
二、Related Work
文本生成图像T2I:文本到图像合成的大部分工作都集中在日益复杂的生成对抗网络的发展上
(甘斯)[8]。最近的研究利用了多阶段生成[56]、注意生成网络[49]、双重学习[36]、动态记忆[28,57]、语义分离[51]、显式对象建模[14]和对比损失[19,55]来进一步推动该任务的性能。DALL-E[38]是一个大型转换器语言模型,可以生成文本令牌和图像令牌。VideoGPT[50]适应了DALL-E架构于有条件的生成视频,从头训练。相反,我们使用了预训练的DALL-E和任务特定的模块进行重新拟合,以便从第一帧中有条件地生成图像序列。
故事可视化StoryVisualiaztion:大多数故事可视化模型遵循StoryGAN中介绍的框架
GAN[27],它包括一个循环文本编码器、一个图像生成器和图像以及故事鉴别器,用于训练GAN[46]。我们使用他们的模型作为起点,并像我们提议于适配故事延续的预训练transformer一样添加改进。
高效参数训练Parameter-Efficient Training:adapter-tuning的调优[12,15,30,45]和prompt-based的调优[23,26]等方法向预训练模型的冻结权值添加少量可训练参数,然后为目标任务学习这些参数。参数的稀疏更新[9,53]和低秩分解矩阵[16]也提供了参数高效的微调方法。[11,33] 结合这些方法为一个统一的方法来微调预先训练的模型。[1] 则' retro- fit '了一个带有cross attention层的预训练nlp模型在文本生成任务中,在每个time_step的单词预测中检索相关的tokens。我们使用retro-fit和prompt-based的调优使预训练的的图像合成模型适应story continuation.。
三、Methods
3.1 Story Continuation
传统的故事可视化,是给定一系列句子 S = [s 1 ,s 2 ,...,s T ],生成对应的一系列图片[ˆ x 1 , ˆ x 2 ,..., ˆ x T ]。这项任务有许多不同的潜在应用,如促进漫画的创作或在教育环境中创建可视化。然而,由于故事可视化任务的表述方式,目前的模型远远不能应用于这些设置。它太依赖于训练集中所看到的图像而生成新的可视化,因此我们只能生成训练集中有的人物,而且,story大多数是叙述类句子,缺少了对背景、设定、人物等等的信息,这些都是由模型自己推论出来的,所以生成的可能和预期的图像不符。期待模型生成全新的视觉属性在缺乏文本信息的情况下是不现实的。所以,故事延续通过给定初始图像来供关于故事背景和角色的初始信息来解决这些问题。
故事延续之中,模型额外接受一个初始的图像,模型可以访问角色的外观、故事发生的背景等等。在制作后续场景时,模型不再需要从头创建所有的视觉特征。解决了当前故事可视化模型中的泛化问题和有限信息问题。我们将第一帧称为源帧,并将序列中的其余帧称为源帧
[x 2,……,x t]作为目标帧。
想了想好像还挺有道理,因为我们实际上做过的就知道,文本里面的信息实际上太少了,实际上不足以生成那么丰富的视觉信息,不过咳咳,直接给图片又是不是有点bug了。
3.2 StoryDALL-E
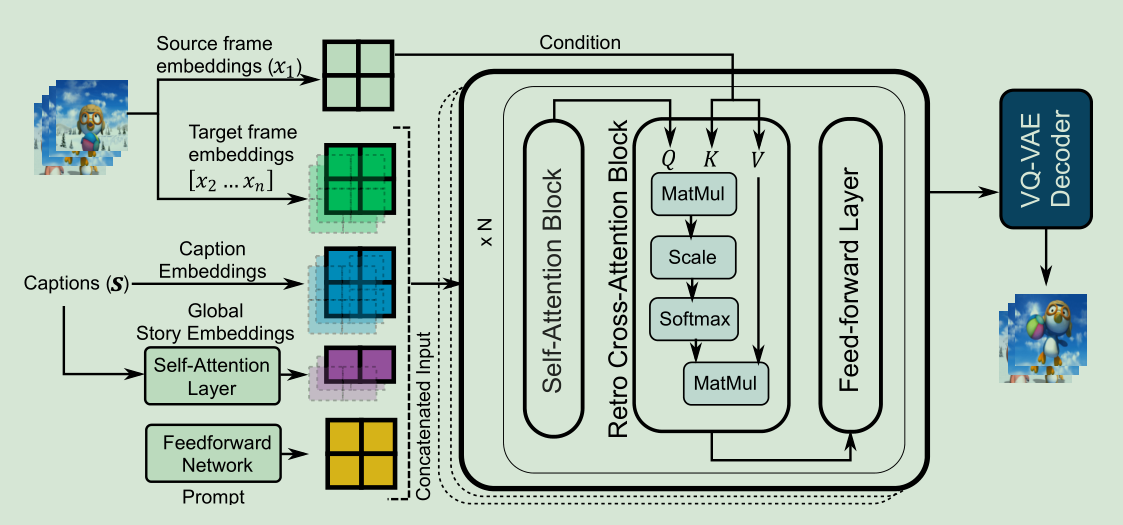
为了将文本到图像合成模型转换为故事延续模型,我们添加了两个特定于任务的模块。
1)Story Encoder用于编码全局故事信息
2)Retro Cross Attention Block接受源帧作为输入
在微调中,模型的所有参数都是被更新的。而在高效参数版本中,用FeedforwardNetowork学习范式嵌入,并将其作为prompt输送给模型,训练时,预训练模型的参数都将被冻结,而两个特定模块是从头开始训练的。
Global Story Encoder
之前的模型大多都用LSTM作为编码器,不过时间和内存都很大啦,所以我们用并行式的self-ATTention来作为Global Story Encoder。
同时我们还加入了正弦位置编码![]()
之后,在每个time_step,故事编码将会被逐句加入到单句编码之中(caption_Embedding)
Retro-fitted Cross-Attention Blocks:
Cross-Attention:文本信息作为Q,而源图片信息作为K和V,进行注意力计算
如框架图和下面公式所见,文本信息先经过一个self-ATTN,然后和源图片信息做Cross-Attn,然后接着经过MLP,最后再经过归一化层输出。
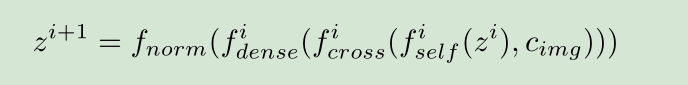
此处交叉自注意力可以随意拿信息,而不用像Self-ATTN一样mask。
Fine-Tune:
StoryDALL-E可以进行整个模型的微调,来学习上面两个新特定模型的权重。然而,Prompt-learing在翻新模型的训练过程中冻结预训练的模型权重,也可以达到这种性能,但是它的参数量比较小,计算资源规模更小了
Prompt:
基于模板范式的学习,直接冻结整个预训练模型,而增加少量的可训练参数去优化于下游任务(其实就是多了一层输入模板变换,当然也可以人工设置模板,不过作者直接用了网络学习模板范式嵌入)
本文中,增加了一个Feedforward层来对输入进行变换,然后添加到和caption_emb一起,再与StoryEmb拼在一起作为Prompt,作为初始的输入。正式地,对于每层transformer block的输入可以描述为:
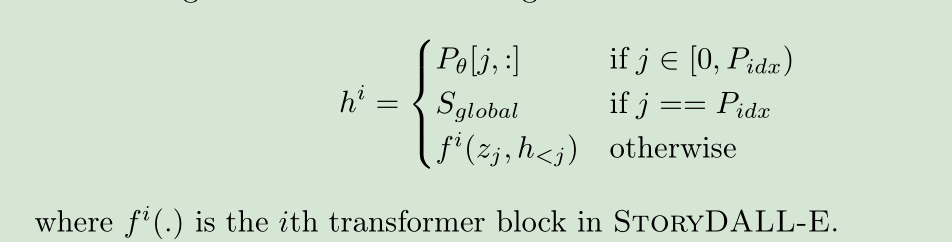
细节:
源图片将被一个预训练的VQVAE的Decoder给压缩成image token,和上述讲述的文本token一起作为输入。然后就是输进去模型,进行自回归建模。如果是微调,那么模型全部更新。如果是基于Prompt的,那么冻结模型,只更新新增的两个模块与Prompt嵌入层。
3.3 StoryGANc
之前的工作都是用GAN实现的故事可视化任务,现在我们也改进了基于GAN用于故事延续任务(也就是多一个源图片帧信息的输入)
整体结构完全用StoryGAN,区别一是使用了预训练的文本编码器(比如Clip),二是加入了Contextual attention来融合源图片信息和输入文本。
四、Dataset

PororoSV
FlintstonesSV
DiDeMoSV(本文新收集):人物更多、更加基于现实、更加挑战(不过我还是觉得这个数据集太杂乱了,这种现实的数据集,很难生成,也没有固定的人物,对于一个物品或者名词,每张图长得都不一样啊。。。)
五、Experiments
1)预训练模型:
StoryDALL-E:整体用的是minDALL-E的预训练模型(minDALL-E用的是预训练的VQGAN-VAE)
StoryGANc:文本编码器用的是预训练的Clip和distilBERT
2)设置:
StoryDALL-E:训练了5个epoch,对于fine-tune是1e-04的学习率(AdamW, Cosine Scheduler),对于prompt-tuning的是5e-04的学习率 (AdamW, Linear Decay Scheduler)
StoryGANc:训练了120个epoch,G和D的学习率分别是1e-04和1e-05.
都是在一个A6000GPU上训练的
3)指标:
FID:目标分布和生成分布的差异
F1 score:生成的图片中的角色和实际文本应有人物的匹配程度
Frame accuracy:生成的图片中的角色和实际文本应有人物的完全一致程度
六、Results
(1)指标评估:
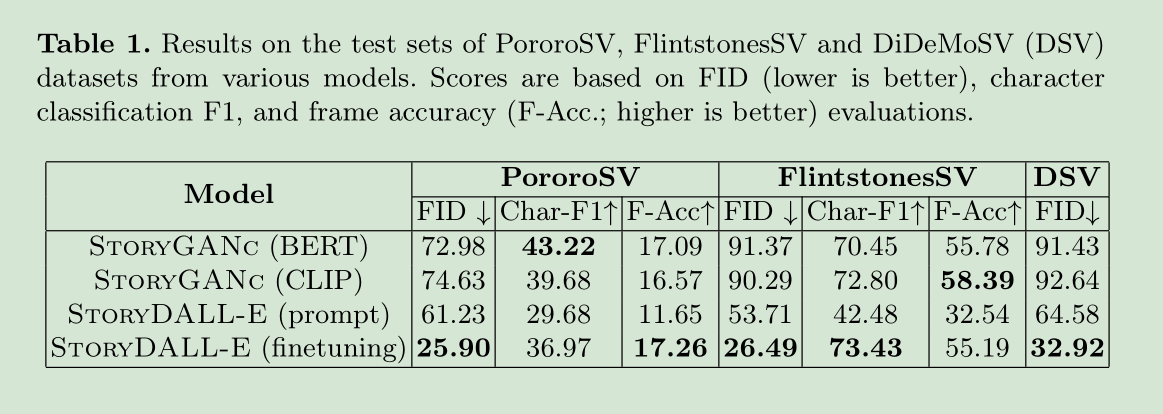
(2)消融实验: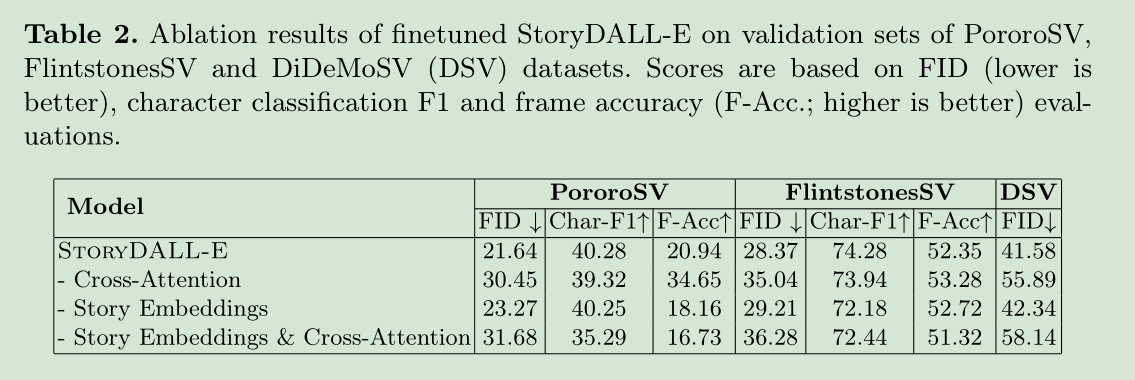
(3)人类评估: 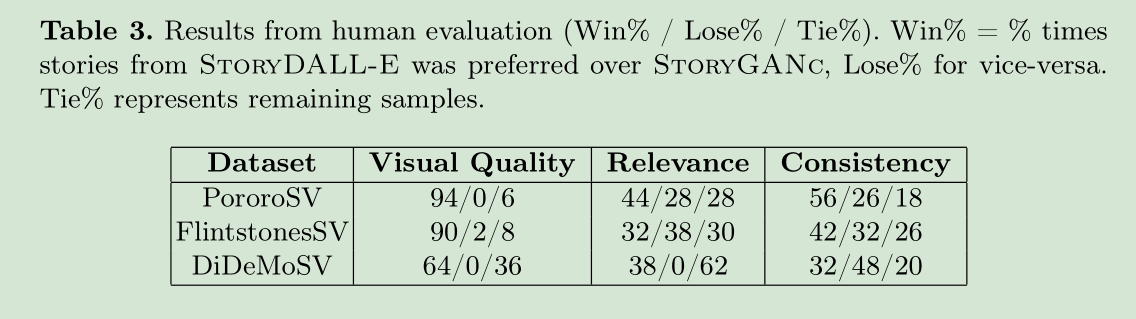
(4)测试效果:

七、Analysis
7.1 Qualitative Analysis
StoryDALL-E在预训练期间接触各种现实世界的概念,这些概念可以在生成过程中发挥作用。例如,经过预先训练的知识和复制机制,帮助StoryDALL-E模型理解“电视”,并为“弗雷德在电视里说话”生成图像,图4 (b))。

然而,StoryDALL-E的图像的整体质量也不能接近人类产生的图像。正如第6节所讨论的,对于包含多个人物的帧尤其如此。这表明,虽然目前的模型能够尝试这项任务,但在模型普遍产生一致和连贯的图像之前,还有很多工作要做。
我们还检验了StoryDALL-E在训练集少出现(图a)甚至未见的人物(图b)上的生成,

StoryDALL-E能成功复制关于源图上面的元素,比如比如紫色的裙子(上)和蓝色的制服(下)。
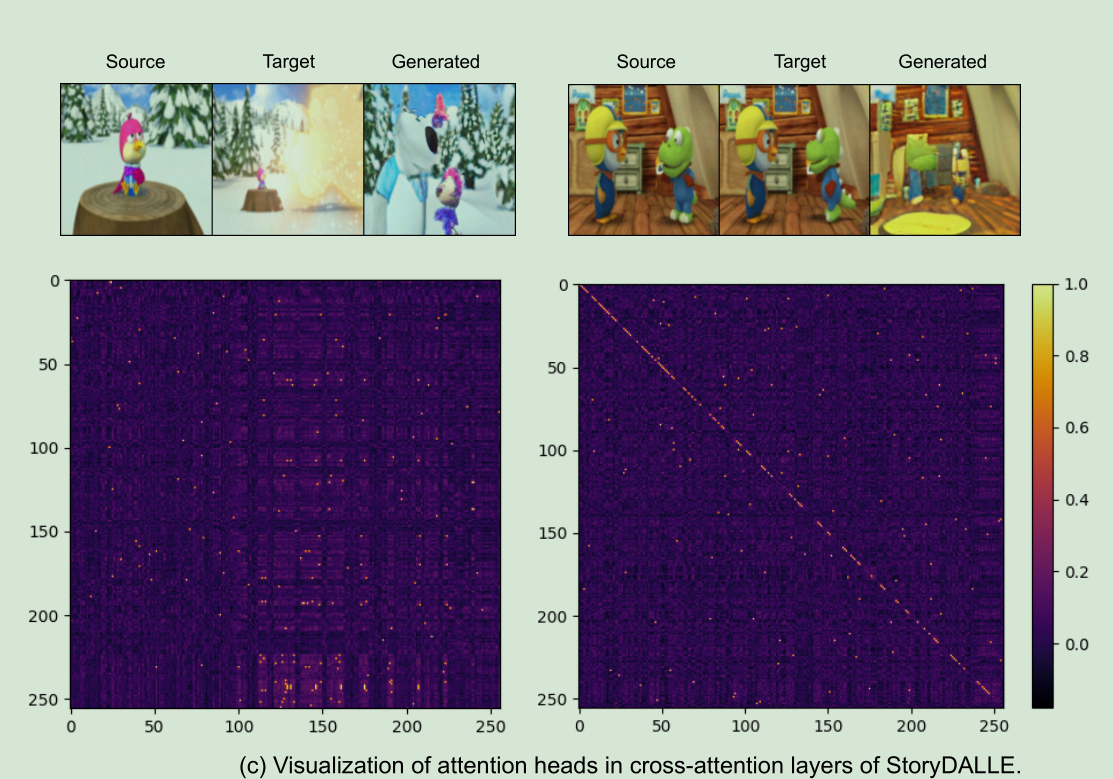
7.2 Retro-fitted Cross-Attention
我们分析了Cross Attention中的注意力得分情况,回顾一下,Cross Attention是将源图的信息作为K和V,输入的文本信息作为Q,进行注意力计算。
左图中,发现注意力矩阵在中间的得分比较高,说明它懂得注意抓取到了源图的人物信息。
右图中,源图和此句对应图片几乎是一样的,同样注意力矩阵的得分也都是沿着对角线上最高,说明它也懂得这两个差不多
因此Cross attention被证明是有效的
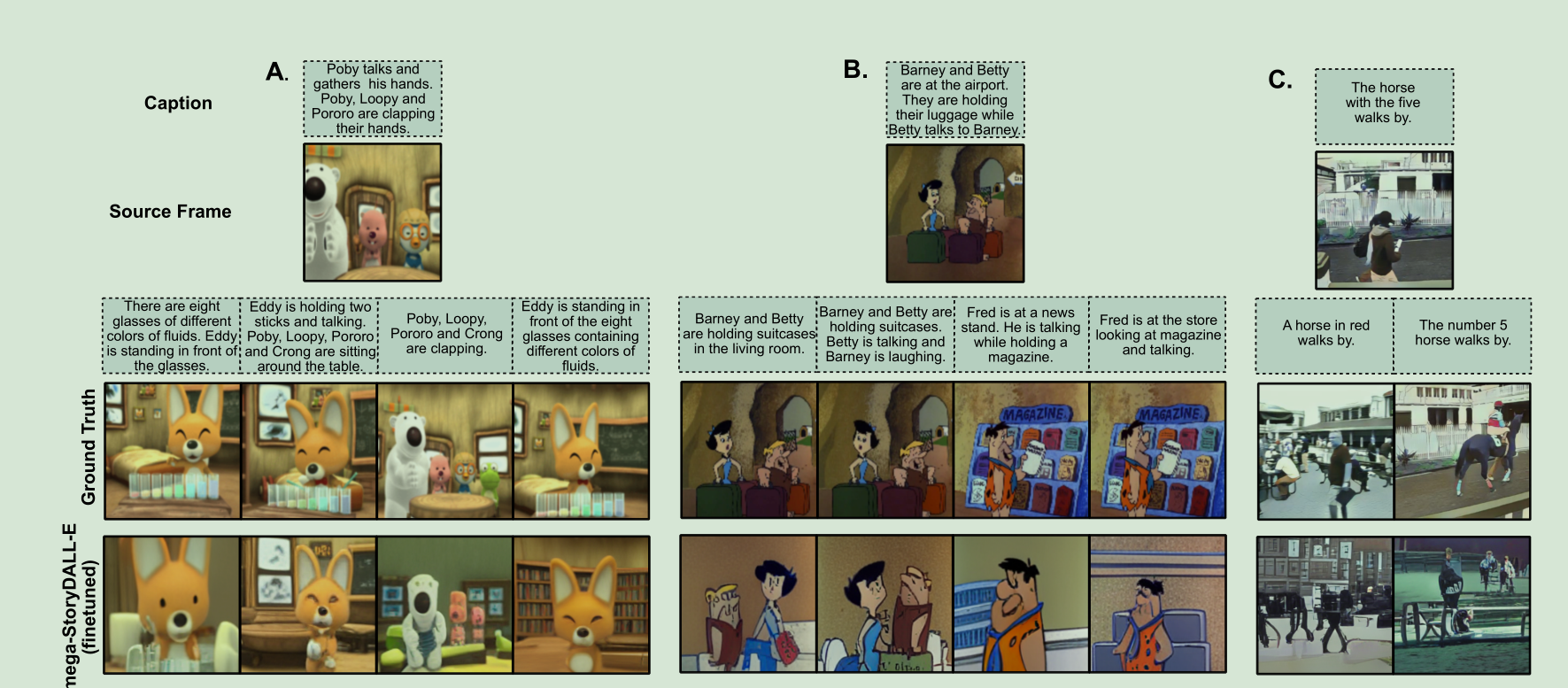
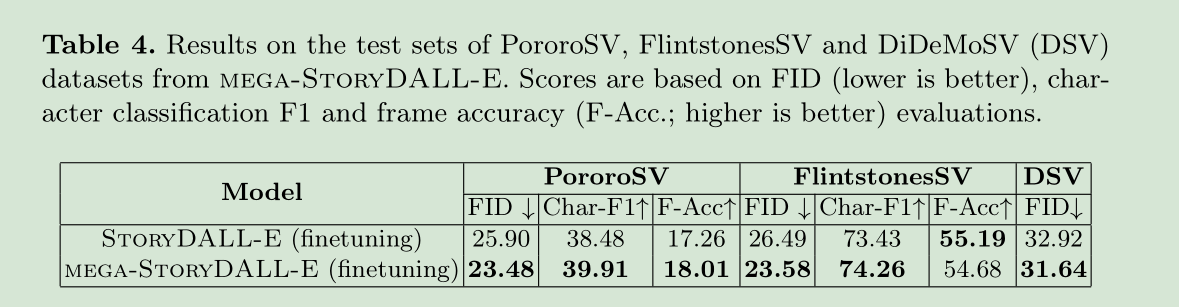
八、New Results & Demo with DALL-E Mega
对DALL-E新发布的版本DALL-E Mega,也做了一个以它为主框架的版本,测得分数如下:
而且还有一个在线网站开放了DALL-E Mega的Demo,开放供测试玩耍,有兴趣的可以去看看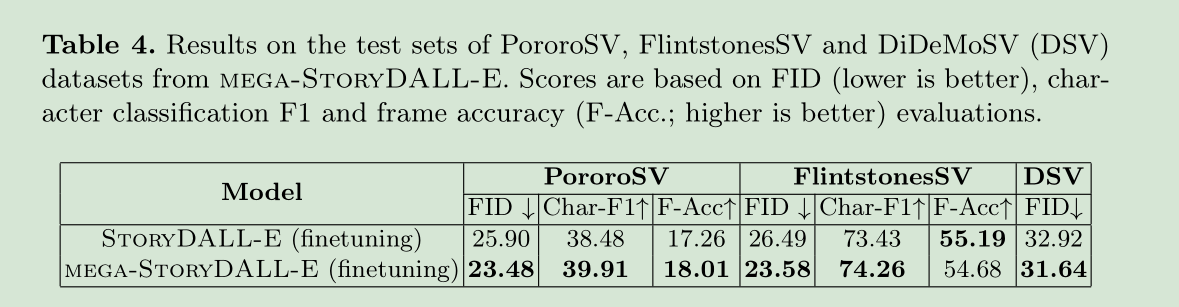
九、Conclusion
我们引入了一个叫做故事延续的新任务,以便使故事可视化任务更有利于真实世界的用例。除了重新格式化两个现有的故事可视化数据集,我们还提出了一个新的数据集DiDeMoSV。
我们的模型StoryDALL-E基于一种 retro-fitting方法,用于适应预训练的基于transformer的文本到图像合成模型,在故事延续数据集上优于基于gan的模型。
我们还添加了新的、改进的结果和一个Demo系统,使用了最新的、更大的DALL-E Mega模型
我们希望这些数据集和模型能够推动未来故事延续方面的工作,我们的工作也能鼓励探索更复杂的图像合成任务的文本到图像合成模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









