







如何面试大厂系列
| 序号 | 内容 | 链接地址 |
|---|---|---|
| 1 | 大厂面试时,面试官会考查哪些能力? | https://blog.csdn.net/belongtocode/article/details/117810750 |
| 2 | 如何在国内互联网大厂面试中游刃有余? | https://blog.csdn.net/belongtocode/article/details/117810951 |
| 3 | 如何全面、高效地准备大厂的技术面试? | https://blog.csdn.net/belongtocode/article/details/117811162 |
| 4 | 在大厂面试中,如何应对算法能力考察? | https://blog.csdn.net/belongtocode/article/details/117811339 |
| 5 | 大厂技术面试中的开放类问题该怎么答? | https://blog.csdn.net/belongtocode/article/details/117811446 |
你好,我是李方圆。
你有没有过这样的经历呢?接连面试几家大厂,都栽在算法题上,明明已经花费了很多时间准备算法题了,还是无法通过算法面试。其实,这是很多面试者面临的困扰,问题到底出在哪里呢?这节课我就带你剖析一下面试官是如何考察你的算法能力,你又该怎么在解题过程中充分展现自己的算法能力。
算法能力的考察,通常包括基础 Coding 能力 + 专业知识的掌握程度。你的代码基本功好不好,面试官看你手写算法就能知道,比如说判断你有没有考虑到各种边界条件、有没有设计一些测试用例校验代码等等,通过这些判断就能清楚地了解你写代码的习惯和思考过程。所以,在做面试题的时候,我们就需要一些应对技巧,给面试官留下好印象。
对于 Coding 题目的设计,不同的面试官会有不同的风格,大体上分为两类,一类面试官喜欢考察你数据结构的基本功,以数组、排序、查找、堆栈、二叉树类型基础题居多,这些题目我们在复习数据结构时容易遇到;另一类面试官喜欢多一些“变化”,倾向于考察解决实际问题类的算法题,这些题目就需要我们在面试时“透过现象看本质”,转化为基本数据结构的问题来解决,一般在 LeetCode 中等和困难模式的题目都属于这一类。
不论是哪一类面试官,都会基于 LeetCode 平台上已有的题目,再结合公司业务做一些延伸拓展。这可以看作是“T”字型的考察方法,大致分为基础问题、结合业务的拓展问题和知识点横向拓展问题这三类。
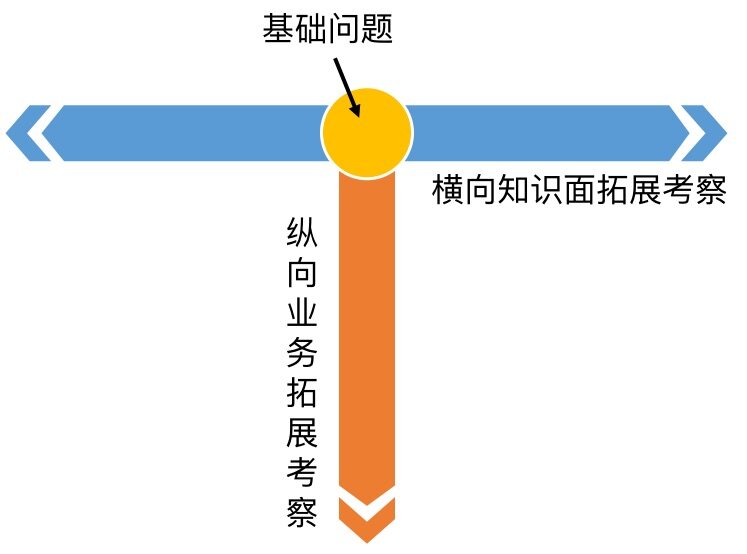
如何应对这三类面试题呢?下面我们以一道字符串类型的算法题为例详细说明。
基础问题
首先,对于基础问题,面试官可能会给定一个字符串 s,和一个包含非空单词的字典 d,需要判断 s 切分出的单词是否都在字典 d 中。需要注意的是,字典中一个单词可以被使用多次,且字典中没有重复的单词。例如:
s = "happynewyear",d=["happy", "new", "year"],返回 True
s = "happynewyear",d=["happy", "new", "ear"],返回 False
这道题怎么解?如果你经常刷题,不难知道这是 LeetCode 的第 139 题,是一道动态规划题,当然最简单的解题思路是利用深度优先遍历求解。以下是基于 Python 的深度优先遍历实现的简单方法,供你参考:
def word_break_dfs(s, d):
if s in d:
return True
cur_word = ''
for i, ch in enumerate(s):
cur_word += ch
if cur_word in d:
if word_break_dfs(s[i+1:], d):
return True
return False
我们先看深度优先遍历的求解方案。深度优先遍历的思想会从头开始遍历 s 中的每个字符,当遍历到可拆分的分割点 i 时,会创建一个新的“分支”,将剩余字符串 s[i+1:] 看做一个新的字符串继续探索是否可拆分,重复以上步骤,直到存在一条路径上,到最后一个字符,拆分出的单词均在词典 d 中,返回 True,否则返回 False。这个方法容易理解,但性能比较低下,因为每个“分支”都会重复地判断 s[j:k](其中 j>i, k<len(s))的子串是否在词典中。巧的是,这正是动态规划擅长解决的问题。下面我们以动态规划的方法重新求解。
我们可以将已经判断过的字符串是否可拆分存放在一个 dp 数组中,即 dp[i] 表示子串 s[:i] 能否满足拆分条件,并且我们可知:当 s[:j] 可拆分时(j<i),若 s[j:i] 可拆分,则 s[i] 也可拆分。下图展示了“happynewyear”的 dp 数组中是否可分的结果。

代码实现如下:
def word_bread_dp(s, d):
if not d:
return False
n = len(s)
dp = [False] * (n+1)
dp[0] = True
for i in range(1, n+1):
for j in range(i):
if dp[j] and s[j:i] in d:
dp[i] = True
return dp[-1]
在实际面试中,如果你能给出以上解法,面试官肯定对你比较满意了,而如果你能进一步给出优化解法,面试官将会眼前一亮。
上述动态规划解法,能否再进行优化呢?答案是肯定的,在第二层 for 循环时,我们是否需要把 0≤j<i 的每一个 s[j:i] 都做一次判断呢?假设字典中最长单词长度为 max_len,如果 len(s[j:i])> max_len,那么这个单词肯定不会出现在字典中。因此,我们可以在程序最开始预先计算 max_len,再将 j 的循环开始位置设为 i-max_len。这里有一个小细节就是你有没有考虑到 i-max_len<0 的情况,因此 j 的循环范围为 max(i-max_len, 0),详细代码如下:
def word_bread_dp2(s, d):
if not d:
return False
n = len(s)
dp = [False] * (n+1)
dp[0] = True
max_len = max(map(len, d + ['']))
for i in range(1, n+1):
for j in range(max(i-max_len, 0),i):
if dp[j] and s[j:i] in d:
dp[i] = True
return dp[-1]
这里需要注意,求解 max_len 时,用到了 Python 的 map 方法,d+[’’] 是为了防止 d 为空的情况。
结合业务的拓展问题
基于前面的基础问题,对于结合面试公司业务的拓展问题,面试官问:在实际应用中,自然语言处理(NLP)阶段拿到的文本有可能是图像识别的结果,用户在输入英文时也经常出现少输空格的情况。给定一个输入的字符串 happynewyear,请问你能否结合单词词典,将粘连的句子加空格还原为 happy new year?如果可以,请返回所有满足条件的句子。
这道题实际上就是将基础问题在求解过程中的全部解“打印”出来。解题的思路与基础问题类似,但需要在校验能否拆分的同时,记录到“当前”为止的拆分结果。
def word_break_II(s, d):
result = []
dfs(s, d, '', result)
return result
def dfs(s, d, path, result):
if word_bread_dp(s, d):
if not s:
result.append(path[:-1])
return
for i in range(1, len(s) + 1):
if s[:i] in d:
dfs(s[i:], d, path + s[:i] + ' ', result)
我们来看这段代码,给出了一种 Python 的解题思路,利用深度优先遍历的方法,记录所有可能的结果,用 dfs() 函数实现。其中的 4 个参数,s 是当前字符串,d 是字典,path 存放遍历过程中到 s[i] 为止可拆分的句子结果,仅当遍历完 s 全部字符并且均可拆分时,才将该条路径结果存入 result 列表。函数中利用了基础问题中的动态规划解法的函数 word_bread_dp(),来减少重复判断已经校验过的子串是否可分。
知识点横向拓展问题
最后考察的是知识点横向拓展问题,还是基于前两道题。题目是:对于多个候选句子,哪个句子为真实句子的可能性最大?如果用机器学习的方法来完成这个任务,你会怎么做?
当我们拿到多个候选句子时,判断哪个为真实句子的可能性最大,本质是要判断句子存在的合理性和通顺性,考察的知识点是语言模型(Language Model),语言模型的 Perplexity 值可以评估句子的合理性。
那什么是语言模型?如果你只回答了 BERT、ELMo、LSTM 是语言模型,那肯定不是面试官想要的答案。你可以从 N-gram 语言模型的基本概念、简单推导过程、Perplexity 公式如何为句子合理性打分,以及其它的语言模型和简单应用这几方面来作答。
除此以外,在知识点横向扩展考察题中,面试官还会考察候选人的 NLP 基础知识。如果你有一定 NLP 基础,你可能很快联想到,英文单词的拆分和中文分词任务类似,是一个序列标注问题。那你也不难想到,面试官会进一步询问你,如果让你从零完成这个任务,从数据的准备到模型的选型,再到模型效果的评估,你怎么做?
在下面这张表格里,我列出了两种不同的回答,你可以对比感受一下:
哪种回答更好呢?我相信你已经有答案了。而且,通过对以上这三道面试题的模拟解答,我相信你也初步掌握了解答思路,最后建议你在平时多刷题、多练习,进一步思考每一道算法题在实际工作中的应用。

参考文章:整理于极客时间每日一课
https://time.geekbang.org/dailylesson/detail/100056892


















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











