







UP中关中断,挂起任务等对临界区保护的做法,在SMP中不再适用,因为它阻碍了同时执行理念,降低了CPU利用率。主要不同是在taskLock与intLock上。SMP提供四中同步与互斥锁:
- 任务与中断级的spinLock
- 任务与中断级CPU指定
- 原子操作
- 内存屏障
1、spinLock的互斥与同步
UP(单核)中的信号量用于任务的互斥与同步在SMP中同样适用,而spinLock则是SMP中用来替换taskLock与intLock的函数。spinLock也称自旋锁具备全内存屏障的属性,也就是要在临界区内的内存读写操作可以按顺序执行而不受多CPU影响,保证更新顺序。spinLock使用FIFO处理加锁请求,避免了死锁。spinLock是被核占用,而不任务占用,会造成核忙等,增加系统延迟。如下图所示
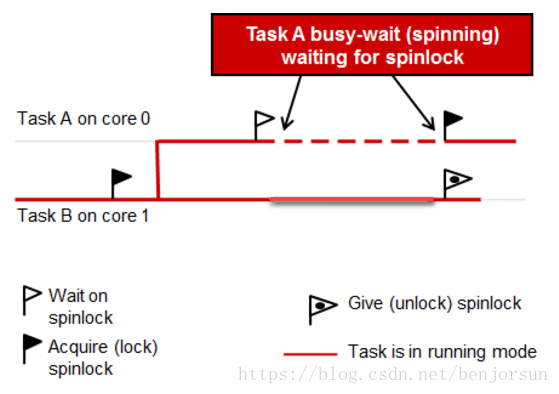
spinLock分为中断级与任务级。
中断级spinLock:
- 关闭本地核的中断。
- 关闭本地核任务抢占。
- 其它核的任务抢占与中断不受影响。
任务级spinLock
- 关闭本地核任务抢占。
- 其它核任务与中断不受影响。
对于中断级的spinLock分为确定的spinLock与非确定的spinLock。
对于确定性的spinLock,是保证了公平性,谁先请求谁先得到。而非确定性spinLock则是谁先抢到谁先得到。

上表是确定性spinLock使用的api,我们也可以使用SPIN_LOCK_ISR_DECL静态初始化一个isr_spinLock。

对于非确定性spinLock有一个好的中断延迟,因为在等待获得spinLock期间,中断不被锁定。
任务级spinLock相当于替换了单核的taskLock,但是有个重要提示,那就它只锁定本地CPU任务抢占。

最后还有一个spinLock的调试版本,当调用spinLock重启后会记录下相关信息。需要添加INCLUDE_SPINLOCK_DEBUG组件,请查阅vxworks api文档。
2、任务与中断的CPU指定
CPU指定的互斥必须使用CPU亲和性将ISR或者任务绑定到指定CPU才有效,这是使用任务与中断CPU指定互斥的前提。


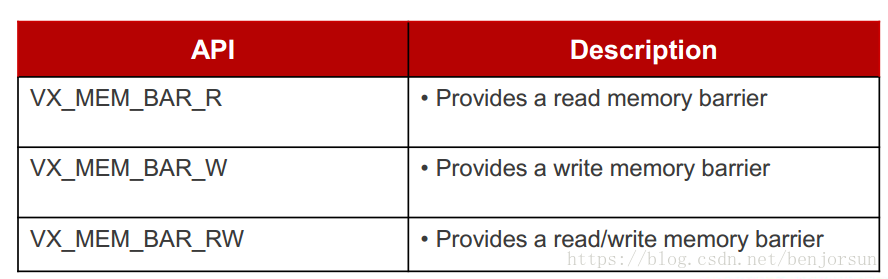
3、内存屏障
内存屏障是为了强制CPU进行顺序内存操作,不乱顺执行。

上面这个例子,core1在轮询flag,当core2设置flag=1时,core1同步打印value。在core2上,flags是最后设置的,但是core2可能乱序执行value=2;flag=1的语句,造成core1打印value=0;

这里我们加上写屏障,意思是屏障前的写操作全部完成再执行flag=1的操作。
内存屏障分为:
4、原子操作
原子操作是针对内存中单项数据进行的,这些操作不被中断及任务打断。原子操作在进行简单数据更新时,可以用来替换spinLock,分为arithmetic, logical, read/write, compare/swap四个逻辑组。原子操作需要内存对齐。
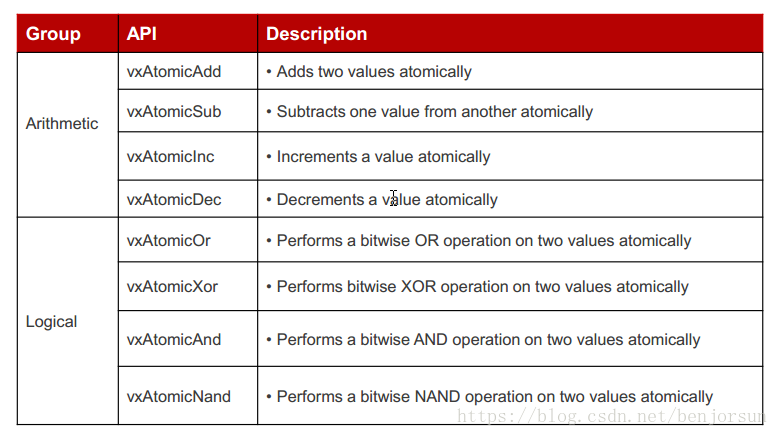
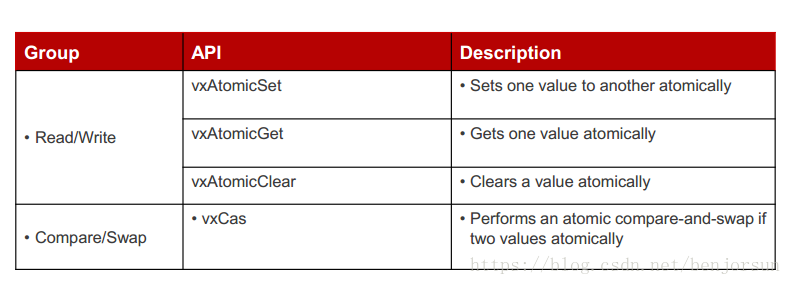
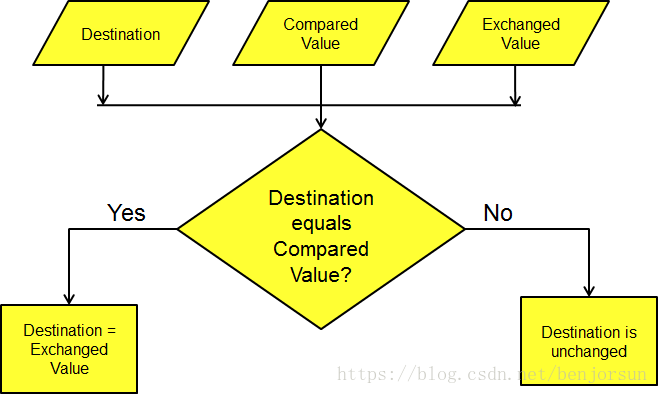
最后说一下vxCasp这个原子操作,它是一个复合操作。意思就是对比和交换数据,但是
只有当目标和比较值相等才交换数据。
5、CPU信息与管理
最后补充一点CPU信息与管理的信息。
CPU空闲状态:

系统空闲状态:
KernelIsSystemIdle,只能在isr中调用,在task中调用永远返回false。
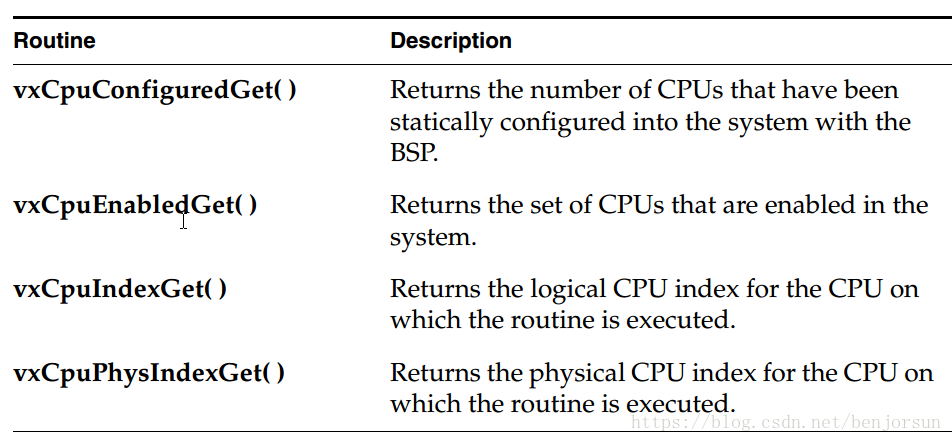
CPU使用:


















 2228
2228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











