







背景
在写跨平台的C/C++代码过程中(本文的研究只限于C/C++范畴),经常会遇到中文字符串乱码的问题。比如,同一个源码,用MSVC编译/运行能正常显示中文字符串,但在linux下编译/运行显示中文字符串就乱码。
导致这种现象的根源就在于字符集编码不匹配导致,本文将探索隐藏在编程过程中鲜为人知的字符集转换问题,如果你彻底理解了以下几个字符集的概念,以及编程过程中哪些因素会影响这些字符集,将有助于你从根源上解决乱码问题。
源码字符集:
英文the source character set,是指源代码文件是使用何种编码字符集保存的。执行字符集:
英文the execution character set,是指源代码经过编译、链接后的可执行文件是使用何种编码字符集保存的,程序实际执行时,内存中的字符串编码就是执行字符集。运行环境编码:
是指操作系统(或者当前控制台环境)用于显示文字的编码字符集。
乱码的根源
源代码文件(源码字符集)经过编译/链接,生成可执行文件(执行字符集),最后程序运行于实际环境中(运行环境编码)。在这过程中如果有字符集不匹配,最终就无法显示预期的文字信息,甚至产生乱码。
编译器在编译源代码时,会将源码字符集转化为执行字符集,如果编译器不能正确识别源码字符集,就得不到正确的字符串数据。
可执行文件在实际运行环境中执行时,为了在控制台(或者其他UI)上显示出字符串,就要将执行字符集转化为运行环境的字符集。如果运行环境的字符集与执行字符集不同,也会导致乱码。
总结起来,要想使程序不会乱码,必须满足:
编译器准确识别了源码字符集,从而得到正确的字符串数据(执行字符集)。
运行环境的编码与执行字符集相同。
字符集
有关字符集的介绍,以下这篇文章讲解的很好,大家先看这篇文章,标题是“字符集编码与 C/C++ 源文件字符编译乱弹”,链接地址:http://jimmee.iteye.com/blog/2165685
此处引用其几个概念的定义:
- C locale
ANSI 发布的字符编码标准,编码空间 0x00-0x7F,占用1个字节,上学时学的 C 语言书后面的字符表中就是它,因为使用这个字符集中的字符就已经可以编写 C 程序源代码了,所以给这个字符集起一个 locale 名叫 C,所有实现的 C 语言运行时和系统运行时,都应该有这个 C locale,因为它是所有字符集中最小的一个,设置为其它 locale 时可能由于不存在而出错,但设置 C 一定不会出错,比如:当 Linux 的 LANG 配置出错时,所有的 LC_* 变量就会被自动设置为最小的 C locale。
- 单字节字符集(SBCS - Single-Byte Character Set)
像ASCII、ISO-8859-1 这种用1个字节编码的字符集,叫做单字节字符集(SBCS - Single-Byte Character Set)。
- 多字节字符集(MBCS - Multi-Byte Character Set)
像GB2312,GBK,GB18030这种用1-2、4个不等字节编码的字符集,叫做多字节字符集(MBCS - Multi-Byte Character Set)。
- GB2312,GBK,GB18030
GB18030:最新汉字编码字符集,向下兼容GBK,GB2312;
GBK:汉字扩展编码,向下兼容GB2312, 并包含BIG5(繁体)全部汉字;
GB2312:简化汉字编码字符集;
源码字符集
不同工具新建的源码文件编码格式不同
源代码都是由不同操作系统的不同编辑工具产生的,不同工具新建的源码文件编码格式不同,比如拿我电脑来说:
- 在Windows下用VS2010新建的源码文件是GB2312编码格式。
- 在Windows下用notepad++新建的源码文件是UTF-8编码格式。
- 在Linux下用VI新建的源码文件是UTF-8格式。
用以下工具可以方便确认文件的编码格式
Linux命令file:
# file main.c
main.c: UTF-8 Unicode (with BOM) C program text, with CRLF, LF line terminators
在Windows下,没有便利的命令可用,可以使用各种编辑工具的“另存为”间接查看,比如Microsoft Visual Studio 2010菜单“文件 > 高级保存选项”。或者,如果你的windows下有安装git,可以打开git bash按linux的方式查看。或者,如果你是windows 10版本,也可以利用原生支持的Linux Bash命令行查看。
文件编码格式转换
Linux下可以使用iconv进行转化,如
# iconv -f UTF-8 -t GB2312 main.c
Windows很多编辑工具的“另存为”都有转换编码格式的选项。比如Microsoft Visual Studio 2010菜单“文件 > 高级保存选项”。
执行字符集
源码编译成可执行文件,源码字符集会转换成执行字符集,可执行文件中的字符串常量就是执行字符集,可以通过WinHex、hd 等16进制查看工具,对执行文件进行查看。可执行文件中的字符串常量字节流,跟程序运行起来内存中的字节流是一样的。
先看下编译器如何识别源码文件,编译过程中又是如何将源码字符集转化为执行字符集的。拿Microsoft Visual Studio 2010和GCC做举例。
MSVC(SP1)
识别“源码字符集:
源码文件有BOM签名的,就按BOM的编码来解析源文件;否则使用本地Locale字符集解析源文件(随系统设置而变)。转化“执行字符集”:
对于char类型,如果有设置预处理选项“#pragma execution_character_set”,编译源码时,转换为预编译所设定的执行字符集;否则使用本地Locale作为执行字符集。对于wchar_t类型,总是使用UTF-16编码。
注意:#pragma execution_character_set预处理指令是在Microsoft Visual Studio 2010 SP1以上才有,Microsoft Visual Studio 2010要打上SP1补丁才支持。所以代码要类似这样写:
#if _MSC_VER >= 1600 /* 1600 is Microsoft Visual Studio 2010 */
#pragma execution_character_set("utf-8")
#endif
GCC
GCC的源码字符集与执行字符集默认都是UTF-8编码,也就是说默认情况下GCC都是按UTF-8来解析源码,编译后的执行字符集也是UTF-8。当然GCC也提供改变默认情况的编译选项(注意是编译过程中的选项,不是链接过程)。
-finput-charset=charset 用于指定源码字符集
-fexec-charset=charset 用于指定执行字符集
除了前两个选项外,还有一个:
-fwide-exec-charset=charset
以下的测试程序,能佐证上面的观点:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#if _MSC_VER >= 1600 /* 1600 is Microsoft Visual Studio 2010 */
#pragma execution_character_set("utf-8")
#endif
int main(int argc, char *argv[])
{
char *str = "123汉ABC";
char *p;
printf("%d |", strlen(str));
for(p=str; *p; p++) {
printf(" %.2X", (unsigned char)(*p));
}
printf(" | %s\n", str);
return 0;
}以下表格个字段含义解释:
源码字符集:使用WinHex查看源码中字符串常量字节流,使用Microsoft Visual Studio 2010菜单“文件 > 高级保存选项”来转换源码字符集。
执行字符集:使用WinHex查看可执行文件中字符串常量的字节流。
是否设置windows预编译选项:#pragma execution_character_set(“utf-8”)
是否设置Linux编译选项:-finput-charset和-fexec-charse
红色显示的就是“汉”的编码:“汉”的GBK编码为BA BA,UTF-8编码为E6 B1 89
Microsoft Visual Studio 2010编译器测试数据:
GCC(版本gcc version 4.4.5)测试数据:
运行环境编码
如果运行环境编码(字符集)与执行字符集不同,也会导致乱码,从上面的测试数据中也能看出来这点。为了显示正确的字符,可以通过修改运行环境编码(字符集),让其跟执行字符集保持一致即可。
Windows控制台运行环境编码
要查看windows控制台当前的运行环境编码,可以在cmd.exe输入chcp,或者在cmd.exe标题栏右键属性查看,显示结果类似“活动的代码页: 936”。
如果要修改编码,可在cmd.exe输入CHCP [nnn]回车,其中nnn指定的是代码页的编号。比如将控制台的字符集改为UTF-8:chcp 65001
代码页(Code Page)是字符集编码的别名,也有人称”内码表”。如936是简体中文(GBK)的代码页编号,65001是UTF8的代码页编号。
Linux终端运行环境编码
我们知道linux系统有六个字符终端(tty1~tty6)和一个图形桌面(GUI窗口,tty7),从图形桌面切换到字符终端,只需按快捷键CTRL+ALT+F1,或CTRL+ALT+F2……CTRL+ALT+F6。要切换回图形桌面,只需按快捷键CTRL+ALT+F7。
“终端”在历史早期是属于硬件设备,我们现在说的linux终端(Terminal ),主要包括两种类型:“虚拟终端”和“模拟终端”。
虚拟终端:指的是字符终端tty1~tty6;
模拟终端:指的是图形桌面中的终端,我更喜欢它的另外一个名称“终端模拟程序(Terminal Emulation Program)”或者“终端模拟器(Terminal Emulator)”,它是一个程序,明显的特征是带有窗口,如Ubuntu默认的终端模拟器GNOME,还有我们平常在Windows系统中远程登录(SHH/Telnet等)到linux中用的终端也是终端模拟器。
网上很多资料说linux终端要支持中文,只要修改locale环境变量即可,但这些方法对我都不奏效,不管是在字符终端,还是图形桌面终端,修改locale不能让我上面的测试程序在终端中打印出GBK编码的“汉”字(打印出来都是乱码)。可能是我我研究的还不够深入,不过我使用以下这些方法也能让我打印出GBK编码的“汉”字,不管这种方法主不主流,那不是本文讨论的范畴,我要强调的一件事是:运行环境编码(字符集)与执行字符集不同,也会导致乱码,如果两个字符集一样,就不会乱码。
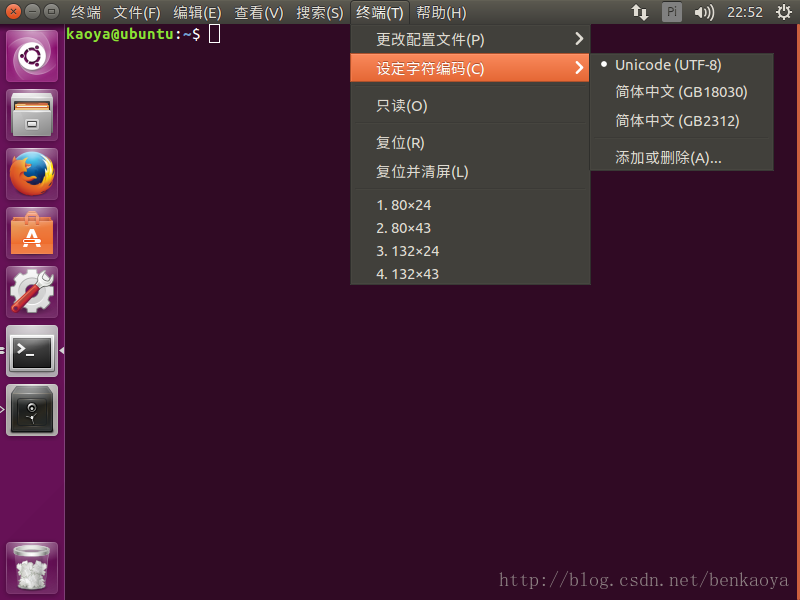
先说说图形桌面的终端模拟器,终端模拟器要支持中文比较简单,只要在窗口标题栏菜单中设定字符编码即可。如Ubuntu的图形桌面默认的终端是,GNOME 桌面的终端模拟器,要改变其字符编码格式,在菜单“终端 > 设定字符编码”中改变,如下图所示。Windows下远程登录的终端模拟器也是如此修改,毕竟他们都是带有窗口的程序而已,修改起来简单。
tty1~tty6字符终端要显示中文就比较麻烦了,几乎任何一种linux发行版,在tty1~tty6字符终端中都无法正常显示中文(中文会显示成乱码),即使你在图形桌面(tty7)中已经安装中文语言支持(已经能够在终端模拟器中显示中文),也是没个卵用。
要在tty1~tty6中显示中文,就得装一些中文化接口的软件,如cce、zhcon或fbterm等。
zhcon是一个工作在Linux控制台下的多内码中文平台。 它能够在控制台上显示简体中文、繁体中文、日文、韩文等双字节字符。它的项目主页是:http://sourceforge.net/projects/zhcon
下面就拿zhcon举例(我的环境是Ubuntu环)。
安装
# sudo apt-get install zhcon
启动
# zhcon
不带参数运行zhcon,默认的编码是gb2312,要utf8编码就要带参数:
# zhcon --utf8 --drv=auto
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









