






论文阅读 | TCSVT 2025 | T2EA:用于红外与可见光图像融合的目标感知泰勒展开近似网络

题目:T2EA: Target-Aware Taylor Expansion Approximation Network for Infrared and Visible Image Fusion
会议:IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY(TCSVT)
论文:https://ieeexplore.ieee.org/document/10819442
代码:https://github.com/MysterYxby/T2EA
年份:2025
1.摘要&&引言
在图像融合任务中,关键是生成高质量图像,以突出关键目标,同时增强场景的可理解性。为了完成这一任务,并在生成适合视觉任务(如目标检测和分割)的融合结果时,提供强大的可解释性和泛化能力,我们提出了一种新颖的可解释分解方案,并开发了一种用于红外和可见光图像融合的目标感知泰勒展开近似 T 2 E A T^{2}EA T2EA网络。
T 2 E A T^{2}EA T2EA 包括以下关键步骤:首先,通过设计的泰勒展开近似(TEA)网络,将可见光和红外图像都分解为特征图。然后,利用双分支特征融合(DBFF)网络对泰勒特征图进行分层融合。接下来,通过逆泰勒展开,将各层的融合图合成为理想的融合结果。最后,结合一个分割网络来优化融合网络的参数,使融合结果更适合目标分割。为了验证 T 2 E A T^{2}EA T2EA网络的有效性,我们首先讨论泰勒展开层数和融合策略的选择。然后,在三个数据集(MSRS、TNO 和 LLVIP)上,对选定的最先进方法生成的定量和定性实验结果,在测试、泛化以及目标检测和分割方面进行比较。
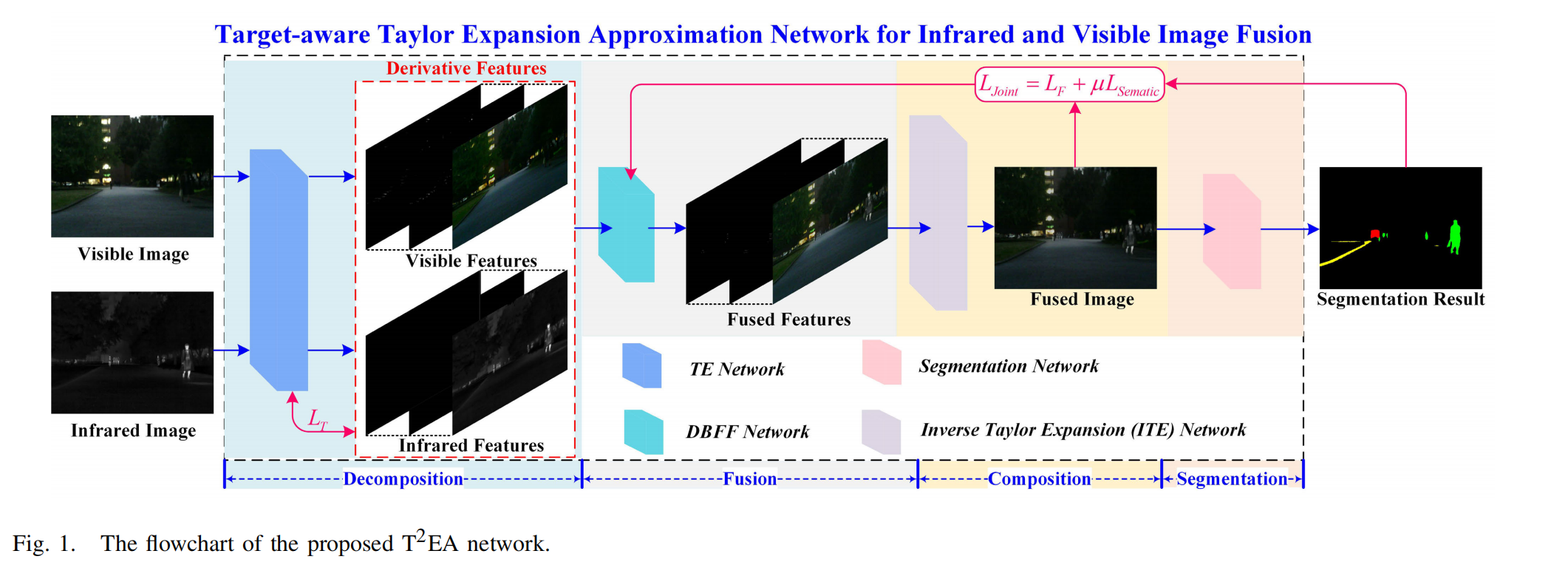
图1. 所提出的 T 2 E A T^{2}EA T2EA网络流程图。
2.目标感知泰勒展开近似 T 2 E A T^{2}EA T2EA网络
在本节中,将介绍目标感知泰勒展开近似( T 2 E A T^{2}EA T2EA)网络的各个组件,包括泰勒展开近似网络、双分支特征融合网络和目标感知融合特征优化训练策略。
2.1 泰勒展开近似网络
泰勒展开理论:泰勒展开作为一种重要的数学工具,已广泛应用于计算机视觉任务,如图像恢复、光流估计和去噪模型构建。根据泰勒展开定理,当 f ( x ) ( x ∈ ( a , b ) ) f(x)(x \in(a, b)) f(x)(x∈(a,b)) 具有 n 阶导数时,它可以在 x 0 ( x 0 ∈ ( a , b ) ) x_{0}(x_{0} \in(a, b)) x0(x0∈(a,b)) 处展开如下:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) 1 ! ( x − x 0 ) + ⋯ + f ( n ) ( x 0 ) n ! ( x − x 0 ) n = f ( x 0 ) + ∑ k = 1 n f ( k ) ( x 0 ) k ! ( x − x 0 ) k , \begin{aligned} f(x) & =f\left(x_{0}\right)+\frac{f'\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\cdots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n} \\ & =f\left(x_{0}\right)+\sum_{k=1}^{n} \frac{f^{(k)}\left(x_{0}\right)}{k !}\left(x-x_{0}\right)^{k}, \end{aligned} f(x)=f(x0)+1!f′(x0)(x−x0)+⋯+n!f(n)(x0)(x−x0)n=f(x0)+k=1∑nk!f(k)(x0)(x−x0)k,
其中 “!” 表示阶乘运算。 f ( x ) f(x) f(x)、 f ( x 0 ) f(x_{0}) f(x0) 和 ∑ k = 1 n f ( k ) ( x 0 ) k ! ( x − x 0 ) k \sum_{k=1}^{n} \frac{f^{(k)}(x_{0})}{k !}(x-x_{0})^{k} ∑k=1nk!f(k)(x0)(x−x0)k 分别表示源可见光或红外图像、基本大尺度特征图和导数特征。从泰勒展开公式(1)可以看出,其各级特征图之间具有密切的相关性,这将有助于网络将原始图像的全局多结构转移到融合结果中。
为了充分提取图像特征图,开发了一个映射网络来近似基本层,同时为导数特征设计一个共享导数网络。
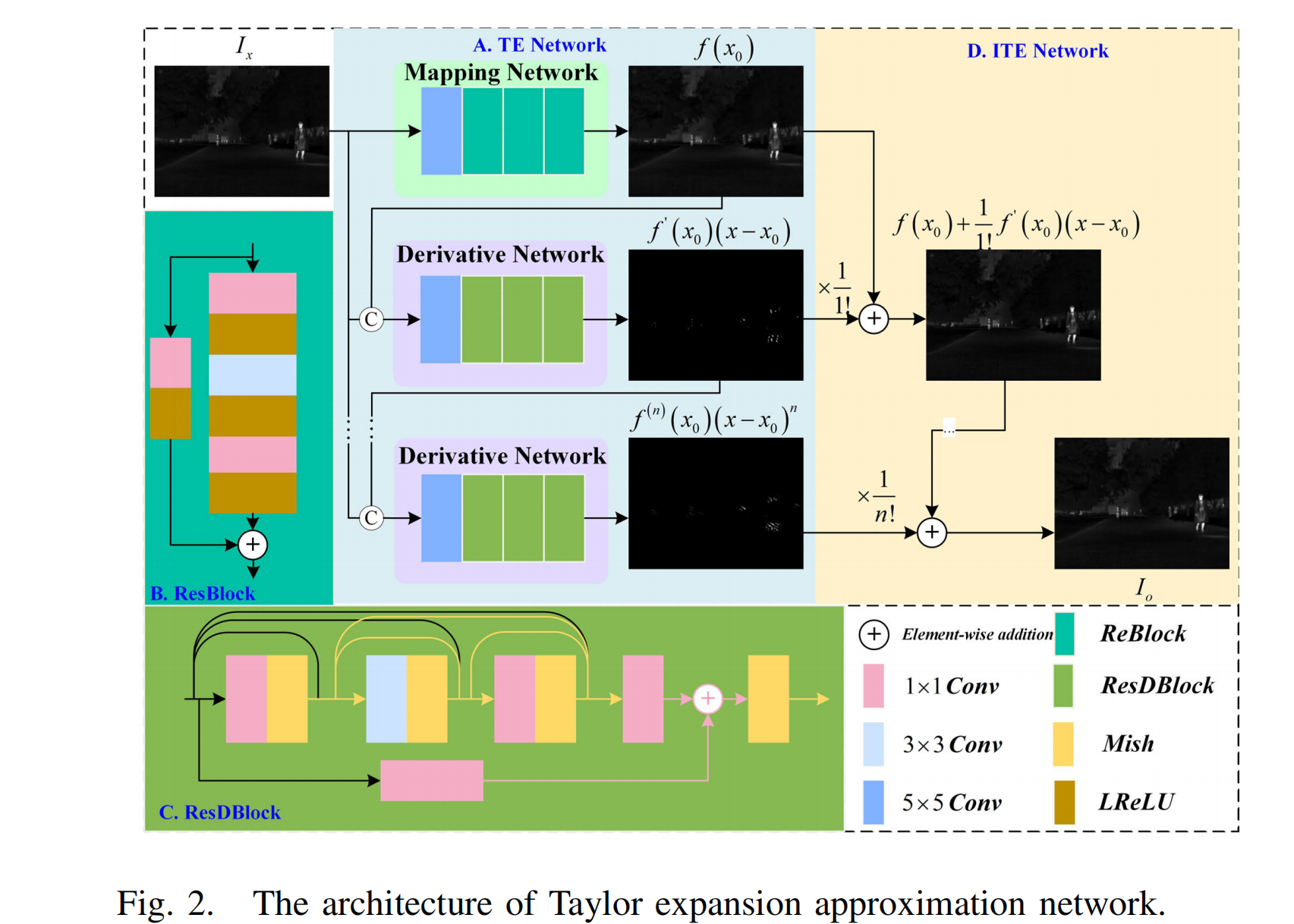
图2. 泰勒展开近似网络的架构。
- 网络架构:公式(1)中有两个主要组件需要估计,即基础层
f
(
x
0
)
f(x_{0})
f(x0) 及其导数层(如
f
k
(
x
0
)
f^{k}(x_{0})
fk(x0),
k
∈
[
1
,
n
]
k \in[1, n]
k∈[1,n])。为了充分提取它们的特征,我们探索了一个映射网络
Φ
b
(
⋅
)
\Phi_{b}(\cdot)
Φb(⋅) 来计算基础层(可表示为
f
(
x
0
)
=
Φ
b
(
f
(
x
)
)
f(x_{0})=\Phi_{b}(f(x))
f(x0)=Φb(f(x))),并为每个导数组件设计一个导数网络
Φ
d
(
⋅
)
\Phi_{d}(\cdot)
Φd(⋅)。
从公式(1)可以看出,相邻的导数组件具有密切的相关性。除了后者是前者的导数外,还有一个与 f ( x ) f(x) f(x) 和 f ( x 0 ) f(x_{0}) f(x0) 相关的附加项 ( x − x 0 ) (x - x_{0}) (x−x0)。为了解决这个问题,我们将 f ( x ) f(x) f(x) 和 f k ( x 0 ) ( k ∈ [ 1 , n ] ) f^{k}(x_{0})(k \in[1, n]) fk(x0)(k∈[1,n]) 连接起来作为 Φ d \Phi_{d} Φd 的输入进行推理,可表示为:
f ( x ) = Φ b ( f ( x ) ) + ∑ k = 1 n Φ d ( C o n c a t ( f ( k − 1 ) ( x 0 ) , f ( x ) ) ) k ! , f(x)=\Phi_{b}(f(x))+\sum_{k=1}^{n} \frac{\Phi_{d}\left( Concat \left(f^{(k-1)}\left(x_{0}\right), f(x)\right)\right)}{k !}, f(x)=Φb(f(x))+k=1∑nk!Φd(Concat(f(k−1)(x0),f(x))),
-
映射网络:图 2(A)所示的网络从图像中提取全局信息,以防止大尺度细节丢失。可以看出,它由一个核大小为 5×5 的卷积层和三个 ResBlock 组成。ResBlock 的具体框架如图 2(B)所示,包括三个核大小为 1×1 的卷积层、一个核大小为 3×3 的卷积层,以及每个卷积层后的四个 Leaky ReLU(LReLU)层,以增强网络稳定性1011。
-
导数网络:该网络由一个核大小为 5×5 的卷积层和三个 ResDBlock 组成。图 1(C)展示了 ResDBlock 的具体框架。为了在特征提取过程中尽可能保留精细特征,在 ResBlock 中引入了密集连接和 Mish 激活函数12。
损失函数:为了获得理想的泰勒分解特征图,我们使用泰勒损失:
L T = L p i x e l + λ L g r a d (3) L_{T}=L_{pixel }+\lambda L_{grad } \tag{3} LT=Lpixel+λLgrad(3)
来优化泰勒展开近似网络,以获得映射网络和导数网络的最优参数,其中 L p i x e l L_{pixel } Lpixel 和 L g r a d L_{grad } Lgrad 分别表示像素损失和梯度细节损失, λ \lambda λ 是一个超参数,用于约束它们的大小差异。
像素损失 L p i x e l L_{pixel } Lpixel 在像素级别衡量两个图像之间的差异,定义为:
L p i x e l = 1 H W ∥ I x − I o ∥ 1 (4) L_{pixel }=\frac{1}{H W}\left\| I_{x}-I_{o}\right\| _{1} \tag{4} Lpixel=HW1∥Ix−Io∥1(4)
其中 I x I_{x} Ix 和 I 0 I_{0} I0 分别表示输入图像(红外或可见光图像)和泰勒展开近似网络的输出。H 是图像的高度,W 是图像的宽度, ∥ ⋅ ∥ 1 \|\cdot\|_{1} ∥⋅∥1 表示 L 1 L_{1} L1 范数。通常,我们期望通过逆泰勒变换,网络从源图像分解的特征图能完全用于重建结果。
除了像素级损失,我们提出了一种梯度细节损失:
L g r a d = 1 H W ∥ ∣ ∇ I o ∣ − m a x ( ∣ ∇ I x ∣ , ∣ ∇ I n ∣ ) ∥ 1 L_{grad }=\frac{1}{H W}\left\| \left|\nabla I_{o}\right|-max \left(\left|\nabla I_{x}\right|,\left|\nabla I_{n}\right|\right)\right\| _{1} Lgrad=HW1∥∣∇Io∣−max(∣∇Ix∣,∣∇In∣)∥1
它与泰勒展开近似(TEA)网络一起训练网络参数,使参数尽可能多地表示原始图像中的信息,其中 ∇ \nabla ∇、 ∣ ⋅ ∣ |\cdot| ∣⋅∣ 和 m a x ( ⋅ ) max (·) max(⋅) 分别表示 Sobel 运算、绝对值和最大值运算。 I n I_{n} In 表示由导数网络分解的特征图( Z n Z_{n} Zn 是特征图的数量,即泰勒层数,是一个超参数,将在消融研究中讨论)。通过优化公式(3)中的联合损失,TEA 网络将原始图像分离为多层特征图。
2.2双分支特征融合(DBFF)网络
2.2.1架构:
为了从红外和可见光图像生成高质量的融合图像,我们引入了如图3所示的双分支特征融合(DBFF)网络。从图中可以看出,有两个并行的分支(架构相同),分别用于从红外和可见光特征图中提取特征。每个分支都包含一个卷积层和两个梯度残差密集块(GRDB)模块,以有效提取浅层特征。如图3所示,GRDB源于ResBlock,但又与之不同,它包含两个分支(轻量级密集网络和梯度残差网络)。在轻量级密集残差网络中,有两个3×3卷积层和一个1×1卷积层,通过密集连接充分提取特征。
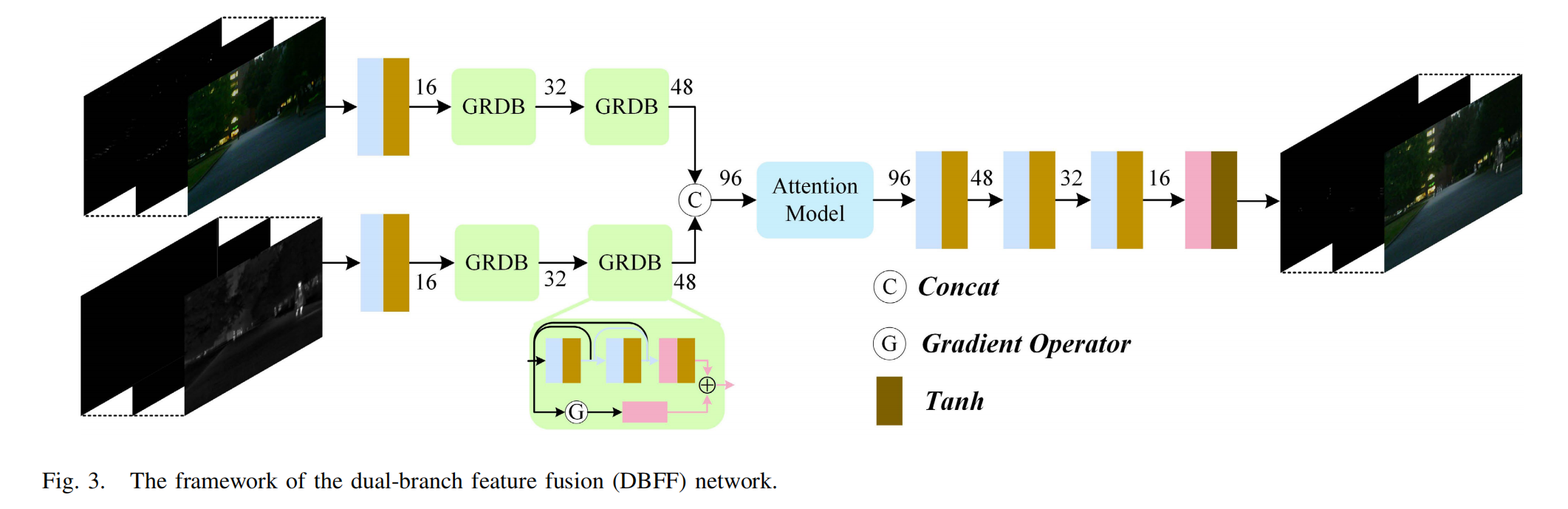
图3. 双分支特征融合(DBFF)网络框架。
梯度残差网络计算梯度图以评估特征幅度,并使用1×1卷积层对通道维度进行标准化。最后,将提取的两个浅层特征通过逐元素相加的方式进行融合。注意,每个卷积层之后都使用了Leaky ReLU(LReLU)激活函数。
在将泰勒展开同一层的红外和可见光特征进行拼接后,我们采用了一个注意力模型、三个连续的3×3卷积层(每层之后的激活函数为LReLU)以及一个1×1卷积层(其后续激活函数为Tanh)。如上文所述,Transformer中的自注意力机制能有效解决长距离依赖问题,但考虑到其复杂性,我们采用了文献[75]中详细介绍的空间 - 通道注意力机制(CBAM)。融合网络中的填充设置相同,步长设置为1。由于我们的网络不涉及任何下采样操作,因此融合图像的尺寸与源图像一致。
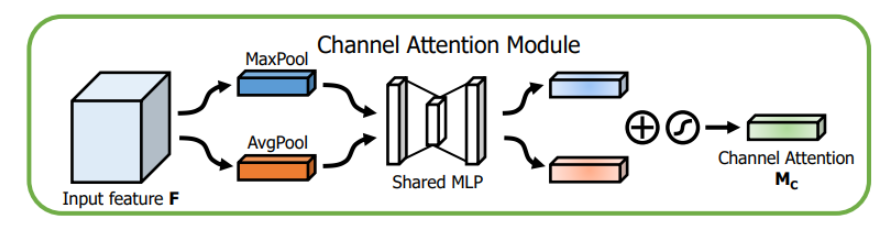
CBAM(Convolutional Block Attention Module)是轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块。
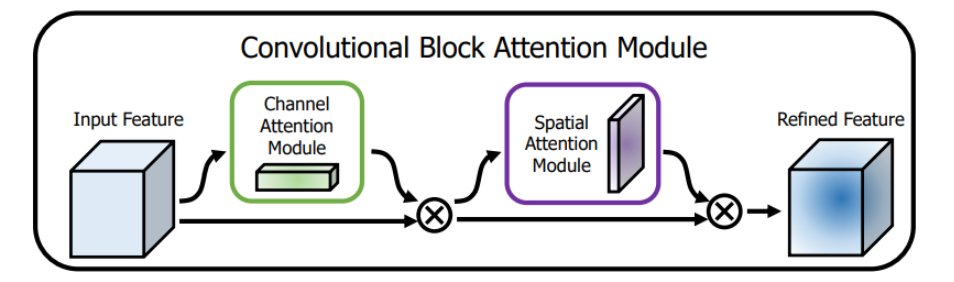
CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
通道注意力模块:通道维度不变,压缩空间维度。该模块关注输入图片中有意义的信息
将输入的feature map经过两个并行的MaxPool层和AvgPool层,将特征图从CHW变为C11的大小,然后经过Share MLP模块,在该模块中,它先将通道数压缩为原来的1/r(Reduction,减少率)倍,再扩张到原通道数,经过ReLU激活函数得到两个激活后的结果。将这两个输出结果进行逐元素相加,再通过一个sigmoid激活函数得到Channel Attention的输出结果,再将这个输出结果乘原图,变回CHW的大小。
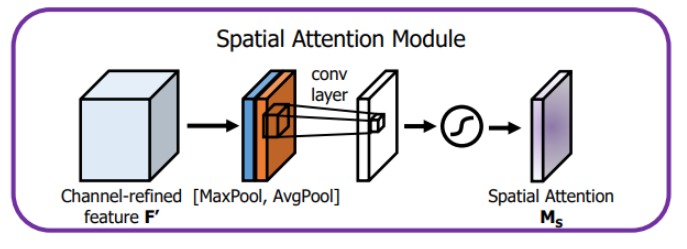
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息
将Channel Attention的输出结果通过最大池化和平均池化得到两个1 * H * W 的特征图,然后经过Concat操作对两个特征图进行拼接,通过7 * 7卷积变为1通道的特征图(实验证明7 * 7效果比3 * 3 好),再经过一个sigmoid得到Spatial Attention的特征图,最后将输出结果乘原图变回CHW大小
2.2.2损失函数:
为了充分发挥融合模型的效能,生成高质量的融合图像,我们使用以下损失函数来优化网络参数:
L F = L i n t + α L t e x ( 6 ) L_{F}=L_{int }+\alpha L_{tex } \quad(6) LF=Lint+αLtex(6)
其中, L i n t L_{int } Lint 表示强度损失,用于约束融合图像的整体强度,其计算公式为:
L i n t = 1 H W ∥ I f − max ( I r , I v i s ) ∥ 1 L_{int }=\frac{1}{HW}\left\| I_{f}-\max \left(I_{r}, I_{vis}\right)\right\| _{1} Lint=HW1∥If−max(Ir,Ivis)∥1
这里
I
f
I_{f}
If、
I
r
I_{r}
Ir 和
I
v
i
s
I_{vis}
Ivis 分别代表融合图像、红外图像和可见光图像。
L
t
e
x
L_{tex }
Ltex 代表纹理细节损失,定义为:
L
t
e
x
=
1
H
W
∥
∣
∇
I
f
∣
−
max
(
∣
∇
I
r
∣
,
∣
∇
I
v
i
s
∣
)
∥
1
L_{tex }=\frac{1}{HW}\left\| \left|\nabla I_{f}\right|-\max \left(\left|\nabla I_{r}\right|,\left|\nabla I_{vis}\right|\right)\right\| _{1}
Ltex=HW1∥∣∇If∣−max(∣∇Ir∣,∣∇Ivis∣)∥1
该损失函数用于学习网络参数,使这些参数能够很好地表示精细的细节信息,并将其从原始图像传递到融合图像中。 α \alpha α 是一个加权参数,用于平衡两者的差异。通过使用这个联合损失函数,DBFF 网络可以同时实现最优的强度和纹理分布,从而兼顾目标和场景的细节。
2.3 目标感知融合特征优化
图像融合的目的不仅是为了增强对场景的理解,还在于使融合结果中的目标得到突出,这有助于检测方法准确地检测到它们。基于这一点,我们进一步利用了一个分割网络(在我们的工作中,我们采用了参考文献[76]中改进的双边分割网络(IBisNet))来优化融合特征。由于我们的任务是优化双分支特征融合(DBFF)网络的参数,在训练DBFF网络时,分割网络的参数被固定为与IBisNet中的参数相同。
2.3.1损失函数:
为了训练 DBFF 网络,使其生成具有丰富纹理且目标突出、视觉效果良好的图像,我们设计了一个联合损失函数,它包括融合损失 L F L_{F} LF 和提出的语义分割损失 L s e m a n t i c L_{semantic} Lsemantic:
L J o i n t = L F + μ L s e m a n t i c (9) L_{Joint }=L_{F}+\mu L_{semantic } \tag{9} LJoint=LF+μLsemantic(9)
该联合损失函数用于优化网络参数。在公式 (9) 中, μ \mu μ 是一个可变的超参数,用于平衡融合损失和语义损失,将在第三节 C2 小节中详细讨论。
L s e m a n t i c L_{semantic} Lsemantic 的计算公式为:
L s e m a n t i c = L m a i n + β L a u x (10) L_{semantic }=L_{main }+\beta L_{aux } \tag{10} Lsemantic=Lmain+βLaux(10)
其中, β \beta β 用于消除数量级差异,两个子语义损失,即主语义损失 L m a i n L_{main} Lmain 和辅助语义损失 L a u x L_{aux} Laux,分别定义如下:
{ L m a i n = − 1 H W ∑ h = 1 H ∑ w = 1 W ∑ c = 1 C I s o ( h , w , c ) log ( I s m ( h , w , c ) ) L a u x = − 1 H W ∑ h = 1 H ∑ w = 1 W ∑ c = 1 C I s o ( h , w , c ) log ( I s a ( h , w , c ) ) \left\{\begin{array}{l} L_{main }=-\frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} \sum_{c=1}^{C} I_{so}^{(h, w, c)}\log \left(I_{sm}^{(h, w, c)}\right) \\ L_{aux }=-\frac{1}{H W} \sum_{h=1}^{H} \sum_{w=1}^{W} \sum_{c=1}^{C} I_{so}^{(h, w, c)}\log \left(I_{sa}^{(h, w, c)}\right) \end{array}\right. ⎩ ⎨ ⎧Lmain=−HW1∑h=1H∑w=1W∑c=1CIso(h,w,c)log(Ism(h,w,c))Laux=−HW1∑h=1H∑w=1W∑c=1CIso(h,w,c)log(Isa(h,w,c))
其中, I s o ∈ R C × H × W I_{so} \in \mathbb{R}^{C ×H ×W} Iso∈RC×H×W 是由分割标签 I l a b e l ∈ ( 1 , C ) H × W I_{label } \in(1, C)^{H ×W} Ilabel∈(1,C)H×W 导出的独热向量。分割网络生成主分割结果 R C × H × W \mathbb{R}^{C ×H ×W} RC×H×W 和辅助分割结果 I s a I_{sa} Isa,以优化 DBFF 网络的参数。
2.3.2多阶段训练策略:
由于我们实验室计算机设备计算能力的限制,采用了一种多阶段训练策略,以获得良好的融合性能,该策略包括:
-
阶段1:TEA网络:为了获得最优的多层泰勒特征图,利用公式(3)中的损失函数训练泰勒展开近似(TEA)网络(其架构见图2),对原始图像进行分解。
-
阶段2:TEA+DBFF。其架构包括图1中的分解(图2(A)中的TE网络)+融合(图3中的DBFF网络)+合成(图2(D)中的ITE网络)。在这个阶段,TEA网络的参数固定,我们使用损失函数(6)训练DBFF网络,以获得用于融合结果的网络参数。
-
阶段3:TEA+DBFF+分割:为了进一步优化 DBFF 网络的融合参数以用于目标分割,我们采用一项高级视觉任务(参考文献 [76] 中的 IBisNet 分割)并将其融入到阶段 2 的方案中。在训练阶段,TEA 和分割网络的参数都固定下来,以便优化 DBFF 网络的参数。使用损失函数 (9) 来训练 DBFF 网络。
值得注意的是,损失函数中的超参数 μ 会随着迭代次数动态调整,其计算公式为:
μ = I N T ( i t e r / 10 ) + 1 (12) \mu=INT(iter / 10)+1 \tag{12} μ=INT(iter/10)+1(12)
其中, I N T ( • ) INT(•) INT(•) 和 i t e r iter iter 分别代表取整运算和迭代次数。期望融合网络生成适合分割任务的融合图像,随着迭代次数的增加,融合模型表现更好,语义损失(变得更加重要,这意味着 μ 会增大)能够引导融合网络的训练,使其更适合目标分割任务。
3.实验
为验证 T 2 E A T^{2}EA T2EA 网络的有效性,安排了以下实验内容:测试的实验准备、讨论泰勒展开层选择和融合策略的消融研究、验证其前沿性能和泛化能力的对比实验、展示融合结果在视觉任务中进一步应用的实验,以及验证其效率的计算复杂度分析。
3.1实验准备
-
环境与数据集:我们在 MSRS 数据集上验证 T 2 E A T^{2}EA T2EA 网络的可行性,该数据集选取了 1038 对红外与可见光图像(共 2076 张,分辨率为 640×480 像素)用于训练。所有实验均在一台配备 Intel® Xeon® CPU E5 - 2620 V3 @ 2.40GHZ、16GB 内存和 NVIDIA Tesla P100 GPU 的电脑上,使用 Pytorch 软件实现。
-
参数设置:我们按照第三节 C2 小节中提出的三个阶段训练 T 2 E A T^{2}EA T2EA 网络。在阶段 1,利用 2076 张图像(1038 对红外与可见光图像)训练 TEA 网络。在阶段 2 和阶段 3,同样使用这些图像训练 DBFF 网络。采用 Adam 优化算法优化网络性能,学习率设为 0.00001。公式 (3) 中的参数 λ \lambda λ 根据经验设为 0.3,公式 (5) 中的参数 n n n 将在消融实验中讨论。参考文献 [76],公式 (6) 中的参数 α \alpha α 和公式 (10) 中的参数 β \beta β 分别设为 10 和 0.1。
-
对比方法和评估指标的选择:为展示 T 2 E A T^{2}EA T2EA 的优越性,我们将其与七种前沿融合方法进行定量和定性比较,包括 DenseFuse、DRF、FusionGAN、MFIFusion、SeAFusion、UMF - CMGR、CDDFuse、LRRNet 和 CrossFuse。需要注意的是,这些选定的前沿融合方法均在相同的数据集和训练环境下进行训练。在客观评估中,采用定量指标,包括熵(EN)、标准差(SD)、互信息(MI)、平均梯度(AG)、视觉质量保真度(VIF)和结构相似性(SSIM)来评估其性能。具体而言,EN 和 AG 值越大,细节越丰富;MI 和 SSIM 值越高,融合图像与源图像之间的相关性越强;SD 和 VIF 值越高,可视化的对比度越高。
3.2消融研究

而熵(EN)用于评估不同泰勒展开层数(即导数层数)下我们的 T 2 E A T^{2}EA T2EA 。需要注意的是,结构相似性指数(SSIM)用于评估泰勒展开近似(TEA)网络。图4展示了随着(泰勒展开近似网络导数层)数量变化的定量SSIM和EN值。
-
参数 n n n 对重建结果的影响:为获得最优的泰勒展开特征图,我们使用 SSIM 值,通过第三节 C2 小节中介绍的“阶段 1”策略,分析 MSRS 数据集上不同参数 n n n 对 TEA 网络输出的影响,并使用 EN 值讨论其对最终融合结果的影响。图 4(a) 和 4(b) 分别展示了随着参数 n n n 变化的 SSIM 和 EN 值。从图中可以观察到,当 n = 2 n = 2 n=2 时,TEA 网络的 SSIM 值最佳,同时 T 2 E A T^{2}EA T2EA 方法的 EN 值最佳,这表明泰勒展开层为 2 时,输出特征图的细节最丰富。同时,我们在补充材料中提供了可视化示例,也可验证这一结论。因此,在后续实验中我们将其设为 2。
-
不同融合策略的讨论:我们的研究中有三种融合策略,包括 DBFF + 分割(DBFFSeg,先使用公式 (6) 中的损失函数对源图像进行训练,再使用公式 (9) 中的损失函数微调 DBFF 的参数)、TEA + DBFF(TEADBFF,按照第三节 C2 小节中的“阶段 2”策略进行训练),以及 TEA + DBFF + 分割( T 2 E A T^{2}EA T2EA,按照第三节 C2 小节中的“阶段 3”策略进行训练)。为验证它们的优越性,我们在 MSRS 数据集(选取了 361 对可见光和红外图像)上进行测试。
图 5 展示了两个典型的可视化对比结果。
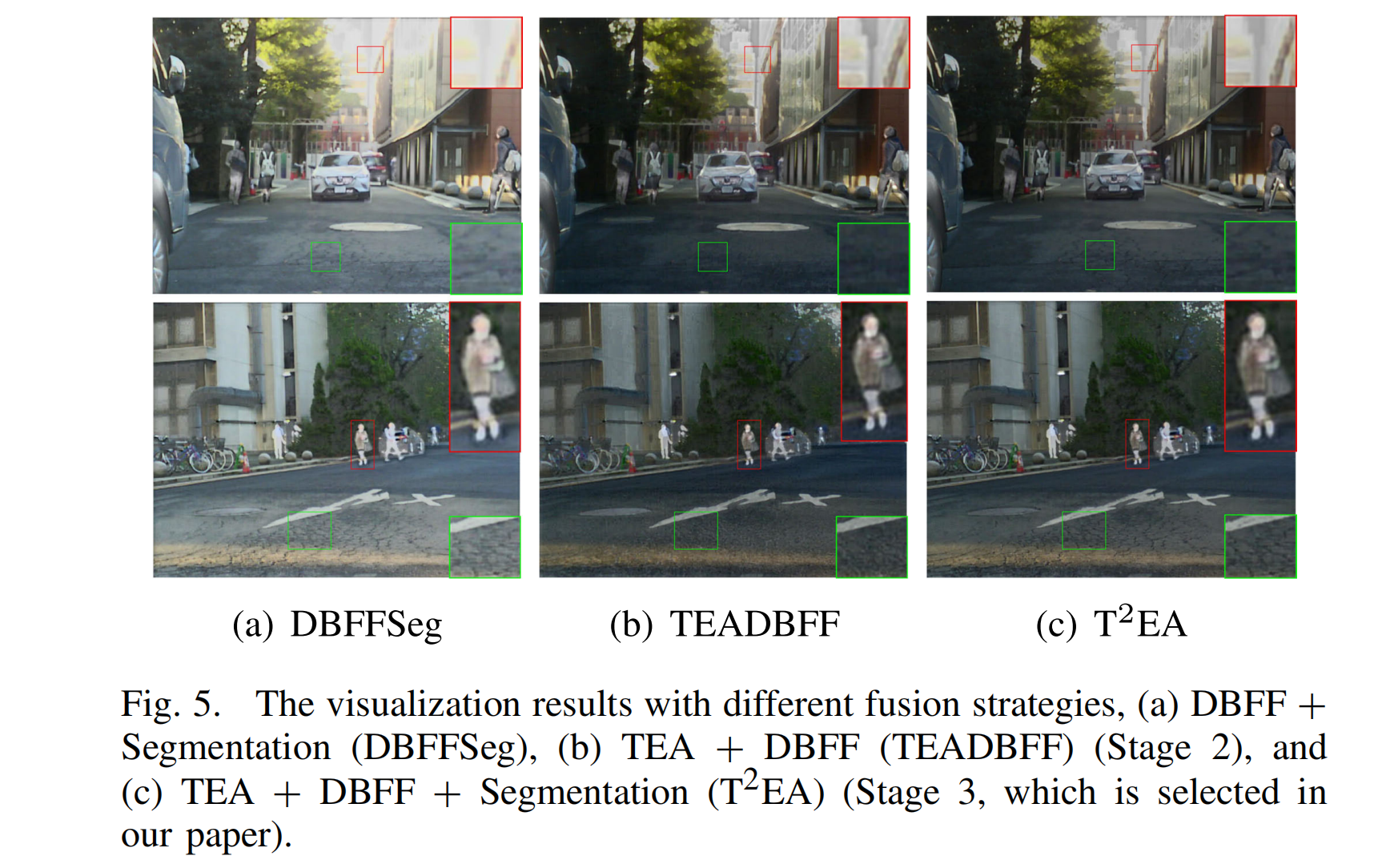
图5. 不同融合策略的可视化结果,(a) DBFF + 分割(DBFFSeg),(b) TEA + DBFF(TEADBFF,阶段2),以及© TEA + DBFF + 分割((T^{2}EA),阶段3,本文选用该策略)。
从图中可以发现,它们在融合结果中突出目标(如人)方面都表现良好。然而,DBFFSeg 和 TEADBFF 融合方案存在各自的缺点。例如,DBFFSeg 使用单一特征集生成融合结果,导致过曝光,过曝光区域的丰富细节丢失(如图 5(a) 所示)。TEADBFF 通过使用 TEA 网络解决了过曝光问题,但生成的融合结果对比度低,暗区细节无法保留(如图 5(b) 所示)。相比之下, T 2 E A T^{2}EA T2EA 通过同时使用 TEA 和分割网络,能够自适应地调整融合结果的光照,在可见光图像强度不均匀时,抑制过曝光区域并提高低光区域的对比度(如图 5© 所示)。我们在表 I 中也提供了它们的定量评估结果。从表中可以看出, T 2 E A T^{2}EA T2EA 方法在定量性能上表现最佳,证明了其优越性,这与可视化对比分析结果一致。此外,我们还提供了分割方法 在融合结果上产生的平均交并比(mIoU)值。从该值可以看出,我们的融合结果由于其最佳的 mIoU 值,更有利于物体分割。同时,我们在补充材料中提供了大量由这三种融合策略生成的实验结果,并进一步用于视觉任务。通过比较,我们发现 T 2 E A T^{2}EA T2EA 网络优于另外两种方法,因此在后续实验中选择它作为我们的报告方法,与其他前沿融合方法进行比较。
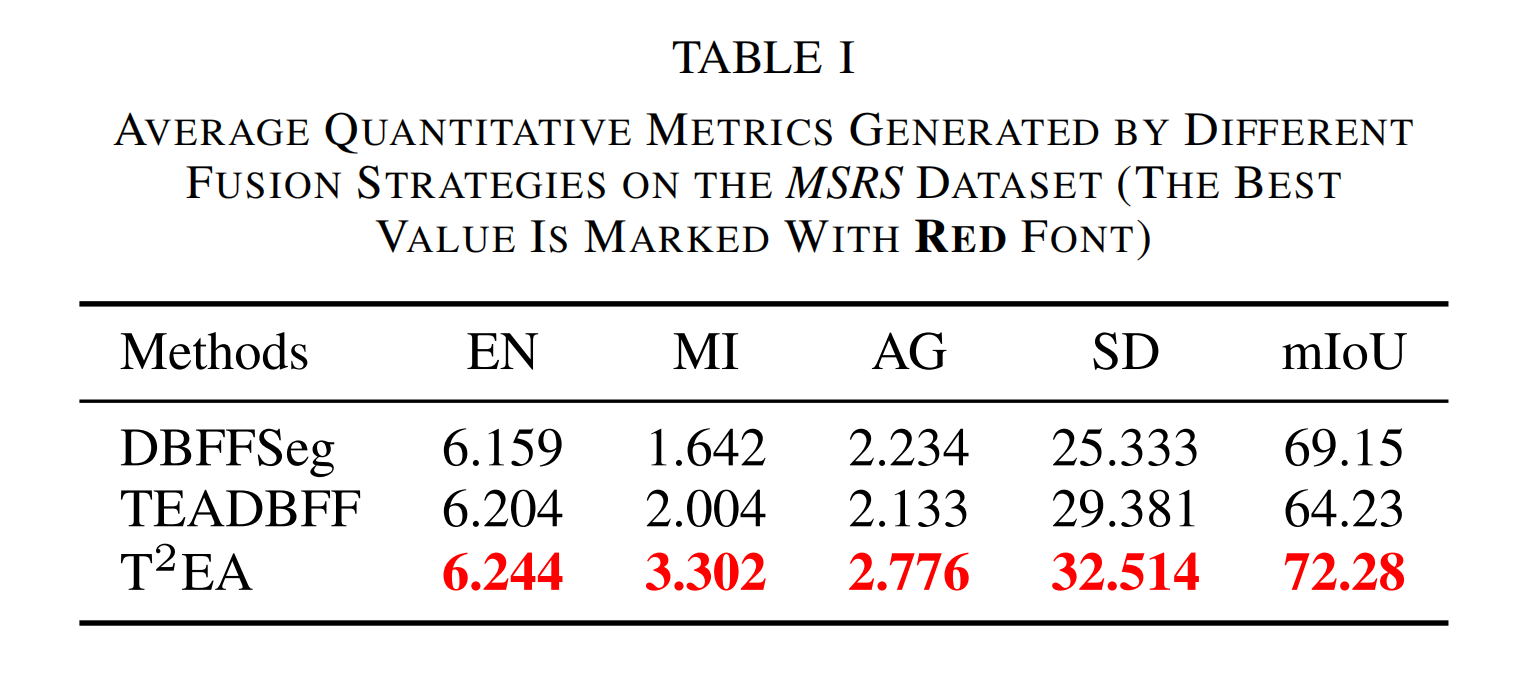
表I 不同融合策略在MSRS数据集上生成的平均定量指标(最佳值用红色字体标记)
3.3 前沿融合方法的比较

图6. 对MSRS数据集中“00016N”图像的可视化比较。

图7. 对MSRS数据集中“00024N”图像的可视化比较。
-
定性评估:图 6 和图 7 展示了选定的前沿融合方法在 MSRS 数据集的“00016N”和“00024N”图像上生成的可视化结果。从图中可以看出,这些方法都能有效地生成融合结果,但在保留细节和突出目标方面各有优缺点:
• (1) DRF(如图 6(d) 和图 7(d) 所示)和 FusionGAN(如图 6(e) 和图 7(e) 所示)能够生成高对比度的融合图像并突出目标,但丢失了许多有用的纹理,导致结果模糊。• (2) 尽管 DenseFuse(如图 6© 和图 7© 所示)和 MFIFusion(如图 6(f) 和图 7(f) 所示)可以将尽可能多的细节从可见光图像转移到融合结果中,但它们仍然过度平滑了暗区的结构,导致结果对比度低。
• (3) 通过在融合框架中引入语义网络,SeAFusion(如图 6(g) 和图 7(g) 所示)生成了具有显著目标的融合结果。然而,它仍然丢失了可见光图像的许多精细细节,导致融合结果对人类可视化的对比度较低。
• (4) UMF - CMGR(如图 6(h) 和图 7(h) 所示)在突出目标(如人)方面表现良好,并提高了融合结果的对比度,但代价是低亮度区域的细节丢失。
• (5) CDDFuse(如图 6(i) 和图 7(i) 所示)生成的融合结果中,红外图像中的物体和可见光图像中的细节都得到了突出,但它们的对比度(在放大的红色框中可以看到)仍然有待提高。
• (6) LRRNet 和 CrossFuse 都更注重保留可见光图像中的丰富细节,导致红外图像中的许多精细细节丢失,尤其是目标曝光不足(如图 6(j)、图 7(j) 以及图 6(k)、图 7(k) 所示)。与上述融合方法相比,我们的 T 2 E A T^{2}EA T2EA 方法生成的融合结果最佳,更适合人类可视化,因为它在保留红外图像中突出目标的同时,保留了可见光图像中的更多细节(如图 6(l) 和图 7(l) 所示)。
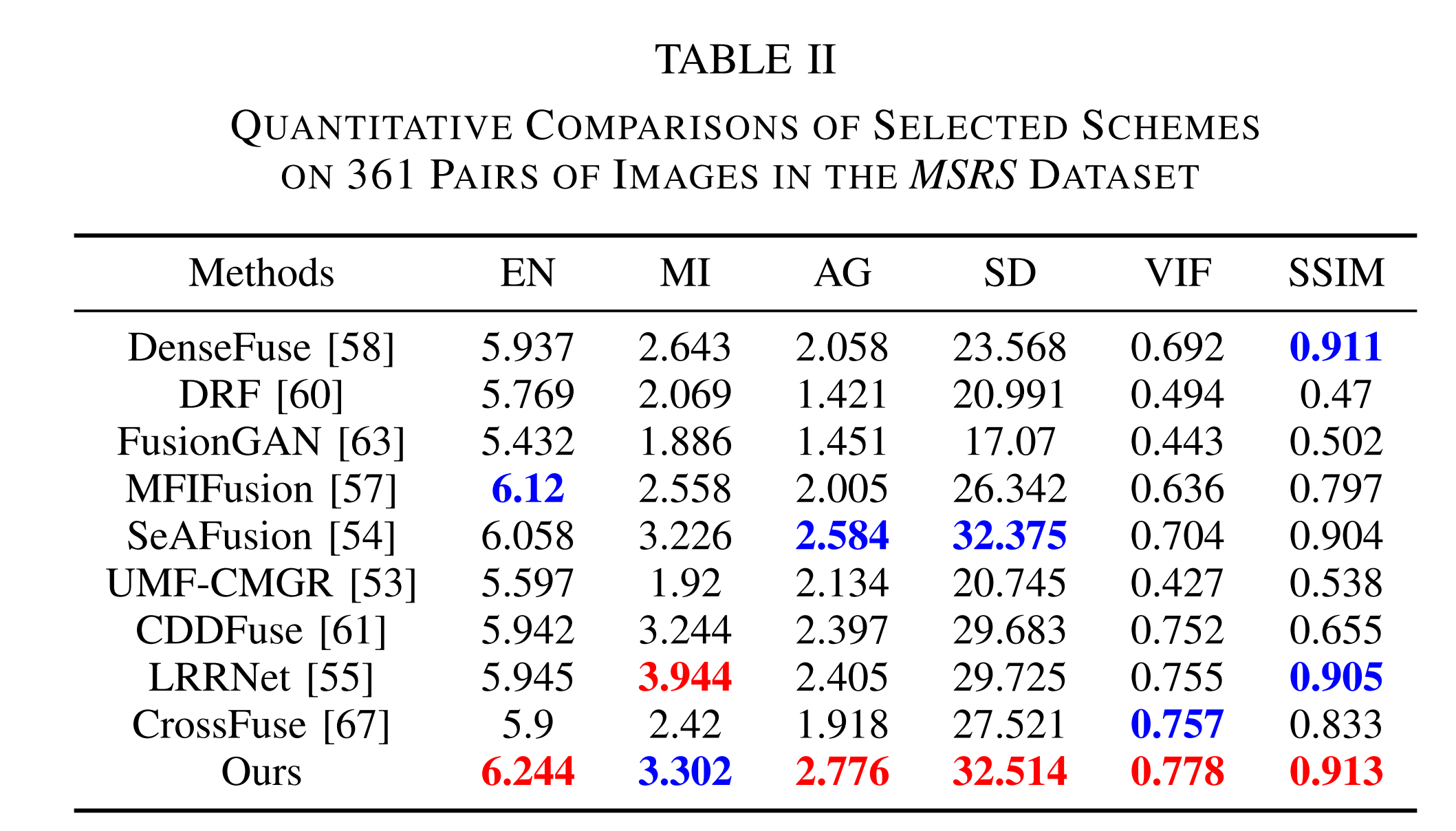
表二 在MSRS数据集中361对图像上所选方案的定量比较
- 定量评估:它们的定量结果如表 II 所示。从表中可以观察到,我们的 T 2 E A T^{2}EA T2EA 方法在所有定量指标上均取得了最佳值,进一步表明 T 2 E A T^{2}EA T2EA 方法在保留融合结果的细节和突出物体方面具有强大的能力,有利于可视化。
3.4 泛化实验

图8. 对TNO数据集中“Bunker”图像的可视化比较。

图9. 对TNO数据集中“Meeting_016”图像的可视化比较。

图10. 对LLVIP数据集中“230024”图像的可视化比较。

图11. 对LLVIP数据集中“200090”图像的可视化比较。
为验证上述前沿融合方法的泛化能力,我们分别从 TNO Human Factors 和 LLVIP 数据集中选取 21 对和 177 对红外与可见光图像,测试它们的图像适应性,并进行定性和定量评估。
-
主观评估:图 8 和图 9 展示了将前沿融合方法应用于 TNO 数据集的“Bunker”和“Meeting_016”图像的可视化结果,图 10 和图 11 展示了应用于 LLVIP 数据集的“230024”和“200090”图像的可视化结果。从结果中可以得出以下观察结论:
• (1) DRF 可以产生高对比度的融合结果,但丢失了可见光图像的许多重要细节,如图 8(d) 红色框中的白色目标以及图 9(d)、图 10(d) 和图 11(d) 中人物的边缘。• (2) FusionGAN 和 MFIFusion 生成的融合结果过度平滑。如图 8(e) - 11(e) 和图 8(f) - 11(f) 所示,暗区的丰富结构和突出目标的边缘都变得模糊。
• (3) 与第四节 C 小节中的讨论相同,SeAFusion 产生了令人满意的融合结果,其中物体得到了很好的突出(如图 10(g) 和图 11(g) 所示)。然而,由于过度强调大尺度物体,融合结果中精细的小尺度结构可能会被平滑掉,如图 9(g) 的绿色框以及图 10(g) 和图 11(g) 的红色框中所示。
• (4) DenseFuse 和 UMF - CMGR 在白天图像融合时,以降低对比度为代价突出融合结果中的目标(如图 8© - 9© 和图 8(h) - 9(h) 所示),在夜间图像融合时,过度平滑低亮度区域的细节(如图 10© - 11© 和图 10(h) - 11(h) 所示)。
• (5) CDDFuse 在融合结果中尽力突出目标并保留良好的细节,如图 8(i) - 11(i) 所示。然而,它在保留过曝光区域的精细细节方面表现不佳,如图 9(i) 和图 9(j) 所示。
• (6) LRRNet 产生的结果(如图 8(j) - 11(j) 所示)和 CrossFuse 生成的结果(如图 8(k) - 9(k) 所示)对比度低,低光区域的丰富细节无法区分(如图 10(j)、图 11(j) 和图 10(k) 放大的红色框中所示)。相反,我们的 T 2 E A T^{2}EA T2EA 方案在保留细节、提高对比度和突出目标方面具有图像适应性(如图 8(l) - 11(l) 所示)。
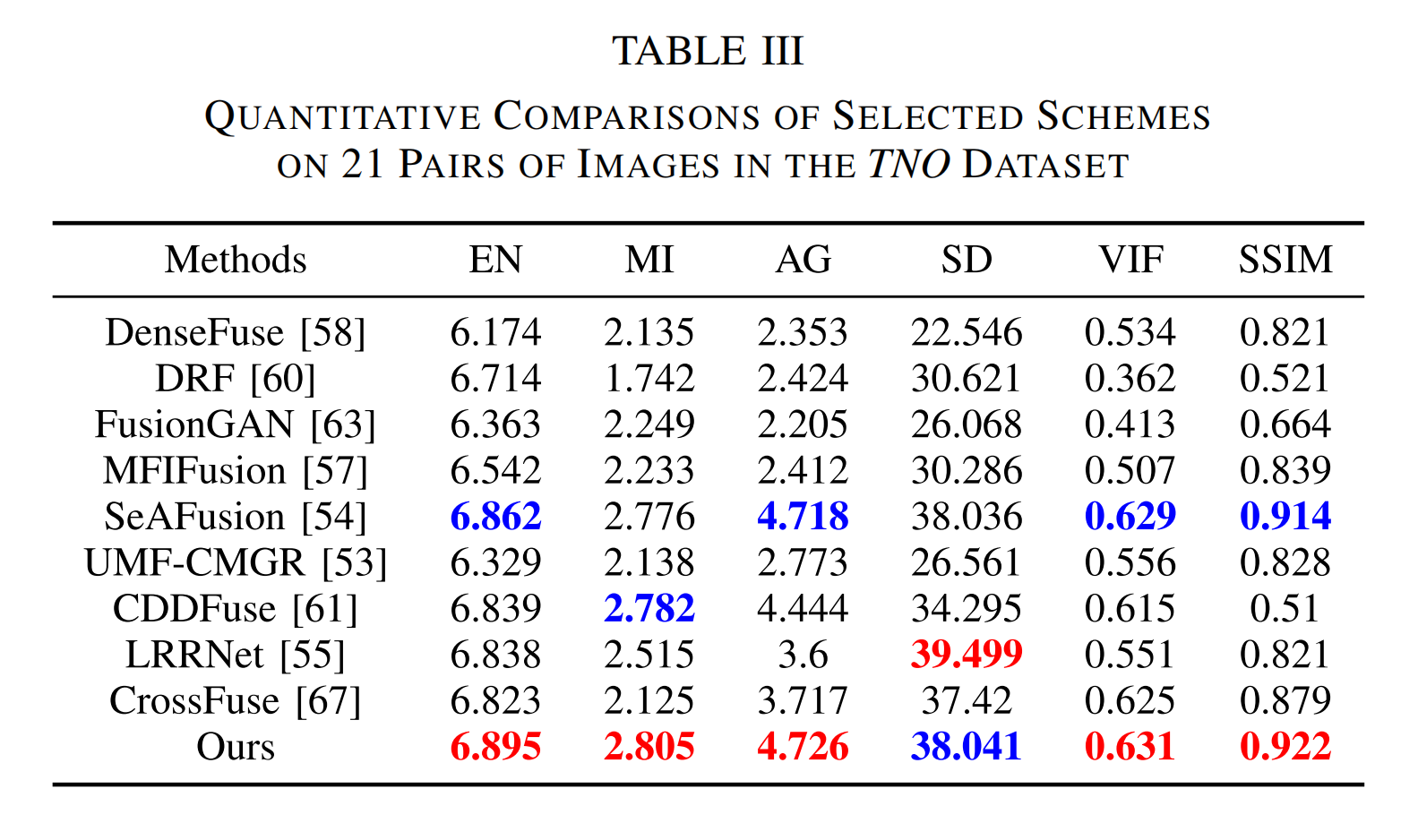
表三 在TNO数据集中21对图像上所选方案的定量比较
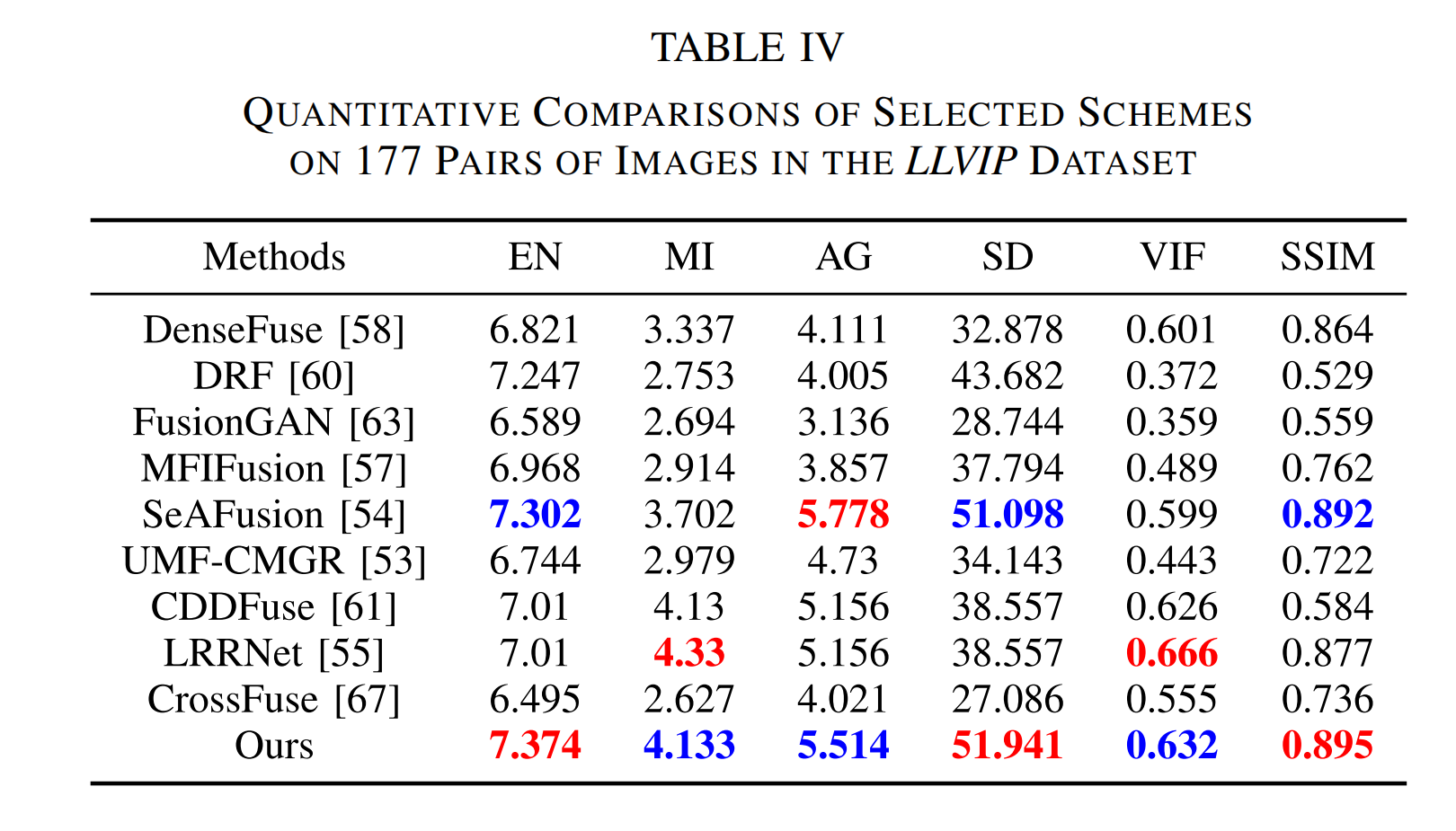
表四 在LLVIP数据集中177对图像上所选方案的定量比较
- 客观评估:表 III 和表 IV 分别提供了前沿融合方法在 TNO 和 LLVIP 数据集上产生的平均定量指标。从表中可以发现,我们的 T 2 E A T^{2}EA T2EA 方法在 EN 和 SSIM 指标上均取得了最佳值,进一步验证了其在从红外和可见光图像向融合结果中保留丰富细节方面优于其他方法,这与可视化对比结果一致。总之,定量评估和定性评估相结合,验证了我们的 T 2 E A T^{2}EA T2EA 方法在图像适应性和泛化方面的强大能力,使其非常适合广泛的视觉任务。
3.5 融合结果在视觉任务中的应用
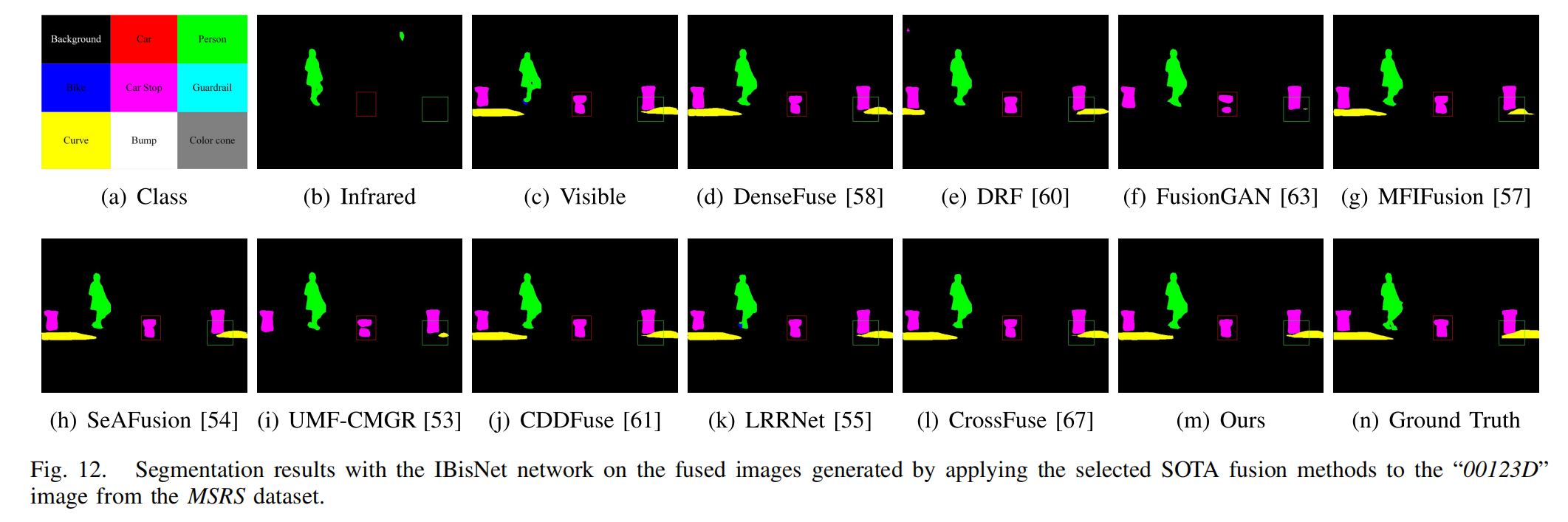
图12. 将选定的前沿融合方法应用于MSRS数据集中的“00123D”图像所生成的融合图像,使用改进的双边分割网络(IBisNet)进行分割的结果。

图13. 将选定的前沿融合方法应用于MSRS数据集中的“00504D”图像所生成的融合图像,使用改进的双边分割网络(IBisNet)进行分割的结果。

图14. 将选定的前沿融合方法应用于MSRS数据集中的“00637D”图像所生成的融合图像,使用YOLOv5网络进行检测的结果。

图15. 将选定的前沿融合方法应用于MSRS数据集中的“00689D”图像所生成的融合图像,使用YOLOv5网络进行检测的结果。
在本小节中,将上述比较的前沿方法生成的融合结果用于视觉任务(分割和检测)实验,这些结果可进一步验证它们在广泛应用中的能力。
-
分割任务:我们在 MSRS 数据集(其中包括一个真值分类数据集)上,使用预训练模型改进的 BisNet(IBisNet)网络,从融合结果中分割目标。IBisNet 方法在红外、可见光和融合图像上产生的视觉分割结果如图 12 和图 13 所示。从这些结果可以观察到,大多数物体可以从融合结果中分割出来,但仍存在缺点,例如物体不完整,如图 12 和图 13 中标记的绿色和红色框所示,甚至图 12(f) 和图 13(d) - 13(j) 中的曲线、图 13(i) 中的凸起以及图 13(d)、图 13(e)、图 13(f) 和图 13(g) 中的自行车都缺失。相比之下,由于我们的融合策略中使用了源图像的语义信息,在我们的融合图像上的分割结果更准确,更接近真值图(如图 12(m) 和图 13(m) 所示)。此外,我们还提供了它们的分割精度,如表 V 所示。在这里,使用交并比(IoU)测量九个类别的像素差异,以评估它们的分割性能。与其他前沿方法产生的融合结果相比,IBisNet 网络在我们的融合结果上对所有类别的精度以及平均 IoU(mIoU)都达到了最佳。这些比较与定性讨论中的结果一致,进一步表明我们的融合结果更有利于分割任务。
-
检测任务:我们还使用 YOLOv5 在融合结果上进行物体检测实验,以验证它们在广泛应用中的强大优势。图 14 和图 15 展示了两个典型的物体检测可视化示例场景。从这些示例中可以观察到,尽管对比的融合算法可以提高图像质量,但它们的融合结果仍然存在许多问题,如第四节 C 小节中分析的那样,不利于物体检测,例如精度低(图 14(f) 中的人和图 15(d) 中的汽车)和物体缺失(除了我们在图 14 中的融合结果外,所有融合结果中的自行车以及图 15(e)、图 15(h) 和图 15(i) 中的汽车)。尽管“00638D”场景(图 14)中的自行车在暗区且较小,但 YOLOv5 仍然可以从我们的融合结果中准确检测到它,验证了我们的 T 2 E A T^{2}EA T2EA 方法在保留小尺度物体方面表现良好。在“00689N”夜间场景(图 15)中,高对比度、细节丰富且目标突出的场景有助于 YOLOv5 提高检测精度。同时,表 VI 中给出了包括精度、召回率和平均精度均值(mAP)在内的定量指标值,以评估检测性能,其中 mAP@0.5、mAP@0.7 和 mAP@0.9 分别表示 IoU 阈值为 0.5、0.7 和 0.9 时的 mAP 值。通过比较可以发现,与其他融合方法相比,YOLOv5 在我们的融合结果上每个 IoU 阈值下生成的值都是最高的。这一结论与视觉分析结果一致,也说明了语义分割是我们 T 2 E A T^{2}EA T2EA 网络中提高融合性能的重要因素。
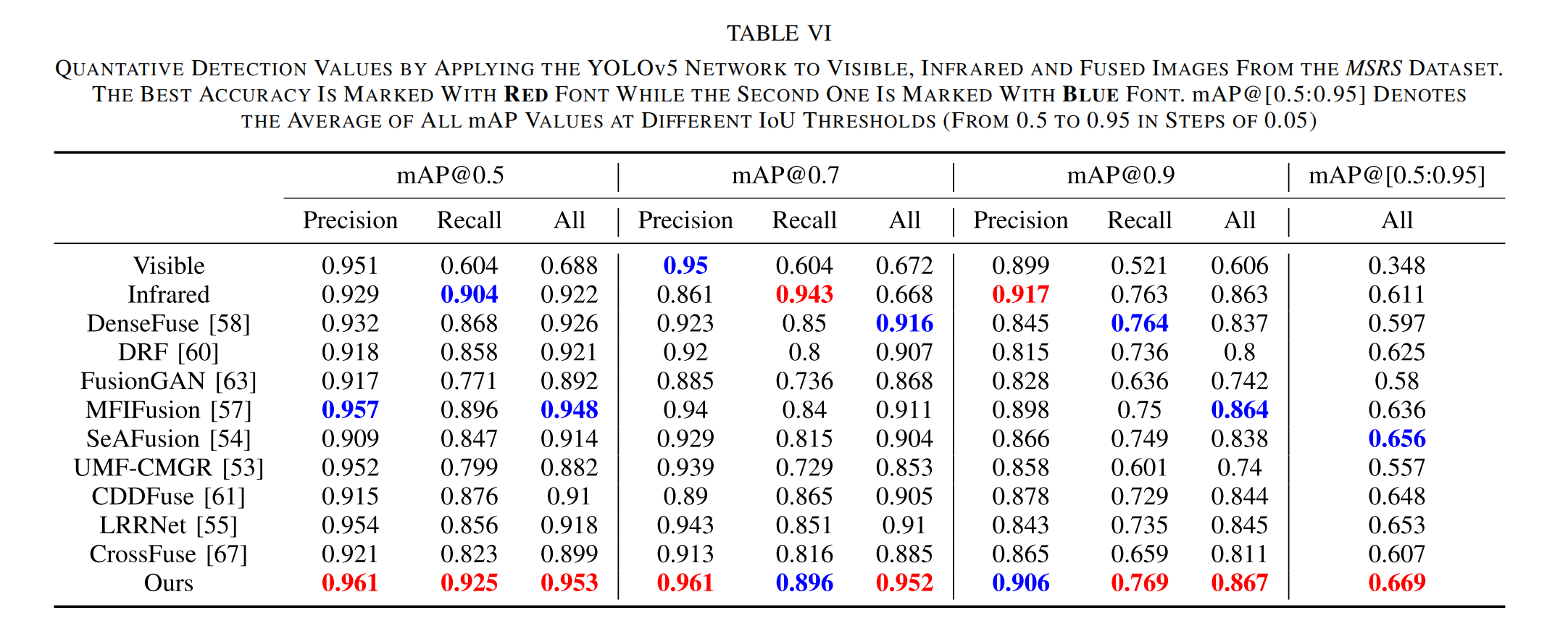
表VI 将YOLOv5网络应用于MSRS数据集中的可见光图像、红外图像和融合图像得到的定量检测值。最佳精度用红色字体标记,次佳精度用蓝色字体标记。mAP@[0.5:0.95]表示在不同交并比(IoU)阈值(从0.5到0.95,步长为0.05)下的所有平均精度均值(mAP)值的平均值。
3.6计算复杂度
为了测试这些方法在运行时间和参数数量方面的效率,我们在三个数据集上进行了实验。在表 VII 中,我们比较了它们的时间成本和使用的参数数量。从表中可以看出,除了在 LLVIP 数据集上,LRRNet 在参数数量最少的情况下表现最佳。相比之下,除了在 LLVIP 数据集上,我们的
T
2
E
A
T^{2}EA
T2EA 网络比 LRRNet 和 SeAFusion 稍慢。然而,考虑到它们在视觉任务中出色的融合结果,我们的
T
2
E
A
T^{2}EA
T2EA 方法在广泛应用中仍然是一种具有竞争力的方法。
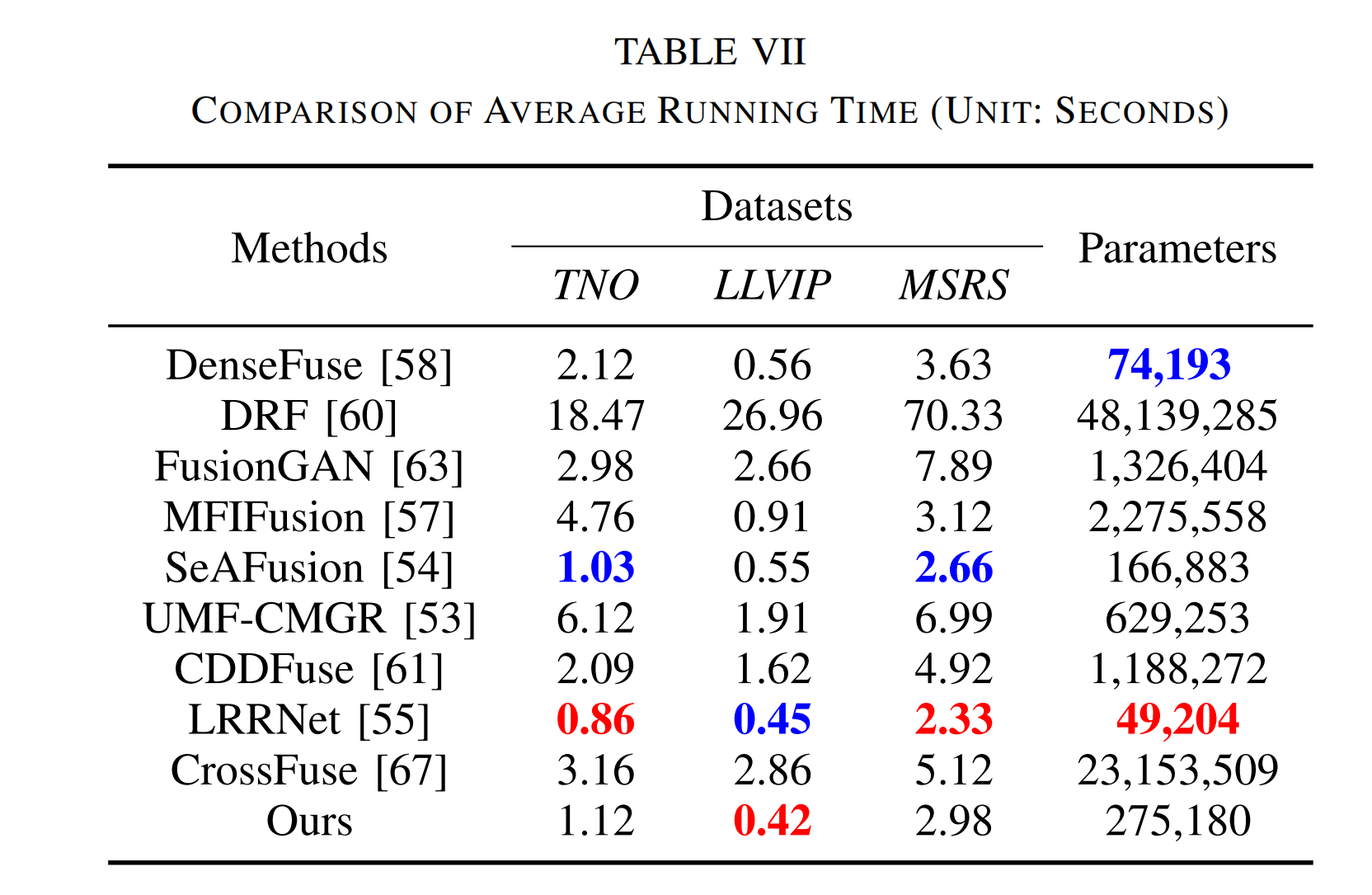
表七 平均运行时间比较(单位:秒)
4.结论
将红外图像中突出显示的物体融入可见光图像的真实场景以用于物体检测,这是一项长期且普遍的研究。为了获得理想的融合结果,本文提出了一种目标感知的泰勒展开近似 T 2 E A T^{2}EA T2EA网络,用于红外与可见光图像融合。所开发的 T 2 E A T^{2}EA T2EA方案包含泰勒展开近似(TEA)、双分支特征融合(DBFF)和语义分割这三个网络。它们各自承担不同的任务,例如,TEA用于图像分解和特征图合成,DBFF用于分解图的融合,语义分割用于融合特征的优化。它们的架构和损失函数已在第三节中详细介绍。在实验中,我们首先讨论了泰勒展开层的选择以及融合策略对融合结果的影响。然后,我们进行了多项对比实验来验证所提出的 T 2 E A T^{2}EA T2EA策略的优势,例如,通过定量和定性比较来验证其出色的融合性能,通过泛化实验来验证其在图像适应性方面的强大能力,通过广泛的应用来展示其在视觉任务中的高可见性 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









