







最近开始看一下算法部分,尤其是MIT课程里面,讲到算法和复杂度的部分
先来讲讲排序吧
第一种:选择排序
假设序列有n个元素
他的做法是,将初始化位置定在0,然后找出序列1到n-1里面最小值,和初始化位置交换
随后,将初始化位置定在1,然后在2到n-1的里面找最小值,和初始化位置交换
以此类推,最后再比较n-2和n-1位置的值,完成排序
用python来实现如下
def selSort(ls):
for i in range(len(ls)-1):
print (ls)
mindex=i #初始化位置是0, 也就是i=0
minval=ls[i] #假设最小是目前是第0位的元素
j = i+1 #被比较的元素将从第1位开始,也就是永远比初始位置大1,用j来代表
while j<len(ls): #当被比较位置没有超出元素索引范围时
if minval>ls[j]: #如果当前最小值大于被比较的值
mindex=j #那么刷新最小值的下标
minval=ls[j] #同时刷新最小值的值
j=j+1 #无论if的情况如何,j自加1向后一位开始下一轮比较
tmp = ls[i] #将ls[i],也就是初始位置的值赋给tmp最为过渡
ls[i]=ls[mindex] #将ls[mindex],也就是刷新后的最小值,赋给当前轮数的初始位置
ls[mindex]=tmp #将tmp里面储存的值,也就是初始位置的值,赋值给原来mindex。
#其实,最后三步的作用就是将ls[i]和ls[mindex]来进行交换,tmp起过渡作用然后用代码进行测试
def testSelSort():
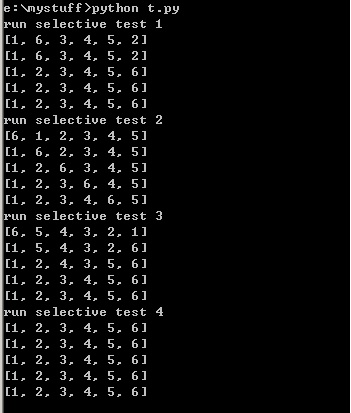
test1 = [1,6,3,4,5,2]
input('run selective test 1')
selSort(test1)
test2 = [6,1,2,3,4,5]
input('run selective test 2')
selSort(test2)
test3 = [6,5,4,3,2,1]
input('run selective test 3')
selSort(test3)
test4 = [1,2,3,4,5,6]
input('run selective test 4')
selSort(test4)
testSelSort()可以来看下运行的结果
第二种:冒泡排序
所谓的冒泡排序,意思就是,通过比较和即刻发生的交换,在队列里比较大的元素,像冒泡一样排到队列的最后
def bubbleSort(ls):
for i in range(len(ls)): #这里的for循环,只是起到计数作用,有几个元素,就要比较几轮
print (ls)
for j in range(len(ls)-1): #因为是比较形式,所以只需要range到len-1的范围
if ls[j] > ls[j+1]: #因为在比较的时候是用j和j+1比较
temp = ls[j] #如果发现有当前元素比下一个元素大的情况
ls[j]=ls[j+1] #立刻发起交换位置
ls[j+1]=temp用代码进行测试
def testBubbleSort():
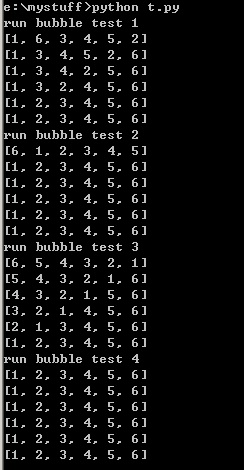
test1 = [1,6,3,4,5,2]
input('run bubble test 1')
bubbleSort(test1)
test2 = [6,1,2,3,4,5]
input('run bubble test 2')
bubbleSort(test2)
test3 = [6,5,4,3,2,1]
input('run bubble test 3')
bubbleSort(test3)
test4 = [1,2,3,4,5,6]
input('run bubble test 4')
bubbleSort(test4)
testBubbleSort()来看看测试结果
第三种:二分搜索
二分搜索主要是每次取队列的中间值,和答案进行比较,这样每次都能够去掉50%的错误答案。
来看一下代码
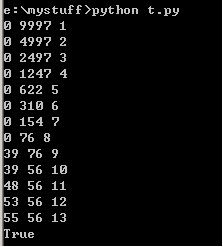
def bsearch(s,e,first,last,calls): #s为设定的范围,e为答案值,first为起始位置,last为最后位置,calls是运行次数
print (first,last,calls) #每次运行前都打印一下当前的范围和运行次数
if (last-first)<2: #如果最后元素的位数减去最初元素的位数小于2
return s[first] == e or s[last] == e #则要么第一个元素是答案,要么另外一个元素是答案
mid = first + (last-first)//2 #不然,提取中间值的位数
if s[mid] == e: #如果队列中间值正好是e,则返回True
return True
if s[mid]>e: #如果队列中间值大于e
return bsearch(s,e,first,mid-1,calls+1) #则将最大位数刷新为mid-1这个值,运行次数加1
return bsearch(s,e,mid+1,last,calls+1) #否则,就代表中间值小于e,刷新初始位置为mid这个值,运行次数加1
def search(s, e):
print (bsearch(s, e, 0, len(s) - 1, 1))
search(range(1,9999),56)
第四种:插入排序方法
他的主要思路是,先将整体序列划分为2部分,一部分是有序序列,另一部分是待排序列
他每次会将待排序列里面的一个元素,和有效序列里面的进行比较,并找到自己合适的位置进行插入.
下面用代码自己做一遍
def insert(ls):
length = len(ls) #列表总长度为lenght
for i in range(1,length): #从列表的第二个元素开始提取
print (ls)
key = ls[i] #待排序的元素为第i位,他的值为key
j=i-1 #被比较的起始位置为i-1,并赋值给j,从右往左开始比较
while j>=0: #当被比较的元素没有超出范围的时候
if ls[j]>key: #如果被比较的元素大于待排序元素的话
ls[j+1]=ls[j] #则将当前被比较的数,向后移动一位
ls[j]=key #同时,将待排序的数字,移动到原来待排序的位置,起始也就是交换位置,但是通过key来作为过渡
j-=1
return ls这里有一个概念特别要记住,他是从右往左开始比较,也就是说当你的 i 比如是4的时候,他是从位数3开始,再2,再0,这样比较下来的
测试用例如下
print (insert([3,2,5,6,4,5,3,2,1,9]))结果正常

第五种:归并排序
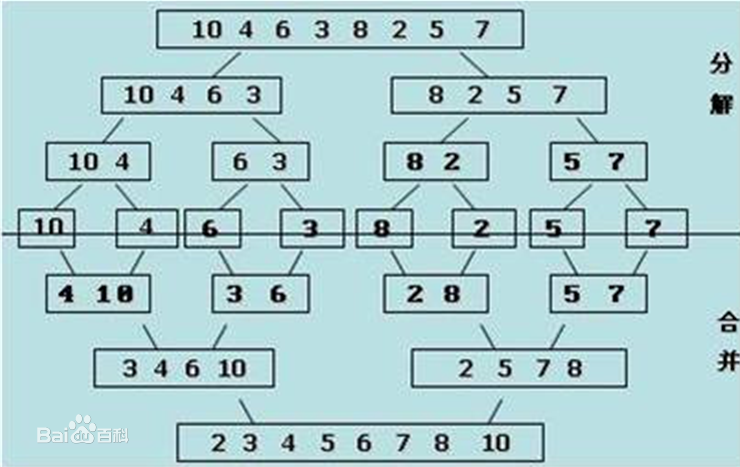
他的主题思想是:把整个序列都打碎,每次从中间打碎,直到每个子序列的元素个数都是1,就认为这个子序列是有序的,再进行合并
他合并的方法是通过每个子序列进行比较,比较后将比较小的值放入结果序列
可以用下图来观察过程
来用代码写一下
def mergesort(seq):
if len(seq) <= 1: #如果列表元素只有一个,直接返回
return seq
mid = len(seq)//2 #将列表一分为二
left = mergesort(seq[:mid]) #这样分的话,在遇到奇数个数元素序列时,左半部永远比右半部少一个
right = mergesort(seq[mid:]) #左右分了以后,再次递归调用mergesort,继续把分裂出来的子序列继续分,直到子序列长度为一
return merge(left,right) #调用合并函数,也是递归合并
def merge(left,right):
result=[] #结果列表
i=0 #一号指针
j=0 #二号指针
while i<len(left) and j<len(right): #当左半部和右半部内都还有元素的时候
#这一个while特别关键,因为当left或者right两者有一个没有元素的时候
#他代表的是:另外一半的元素可以直接排在这个元素后面了
if left[i] <= right [j]: #如果左边的元素小于等于右边的元素,则在结果列表中插入左边的元素
result.append(left[i]) #并把一号指针往右移动一位
i += 1
else: #如果右边元素比较大,则插入右边的元素
result.append(right[j]) #并把二号指针向右移动一位
j += 1
result += left[i:] #这也是一个关键部分,当左边或者右边任意一边的元素被迭代完以后
result += right[j:] #直接可以把当前指针的后面部分全部插入已排序号的result了
print (result) #左半部和右半部都插一次,因为肯定有一个半边是空的,所以无所谓
return result
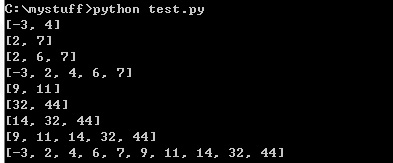
mergesort([-3,4,6,2,7,9,11,14,44,32])
来看一下测试结果
我顺便在合并的函数里面打印出整个过程,可以看到他的运作过程
然后这里再多写一点关于归并排序复杂度的解释
归并排序分为2个过程,一个是分解(类似二分),另外一个是合并
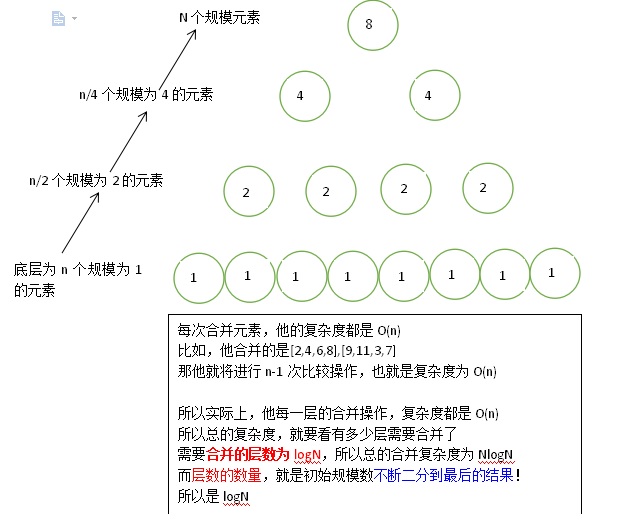
画了一个图,自己理解下整个过程,从下往上是进行归并的过程
归并这个操作的复杂度是多少呢?
比如你有2个列表[1,3,5,7],[2,4,6,8],你要归并成一个列表的复杂度是7次比较,也就是n-1,那么,复杂度就是O(n)
如下图,最下层有n个规模为1的序列,再上去是n/2个规模为2的序列,以此类推,再上去是n/4个规模为4的序列
所以,他其实每一层的总元素规模,都是n,那么,每一层的归并总复杂度,都是O(n),那需要归并的有几层呢?
如下面的例子,一共是3层,那么,其实也就是log8,也就是3,所以层数应该是logN
这个logN,回头想想是什么?实际上代表的是总规模在分解过程中的复杂度,也就是二分.
所以,归并操作的总复杂度,是NlogN















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









