







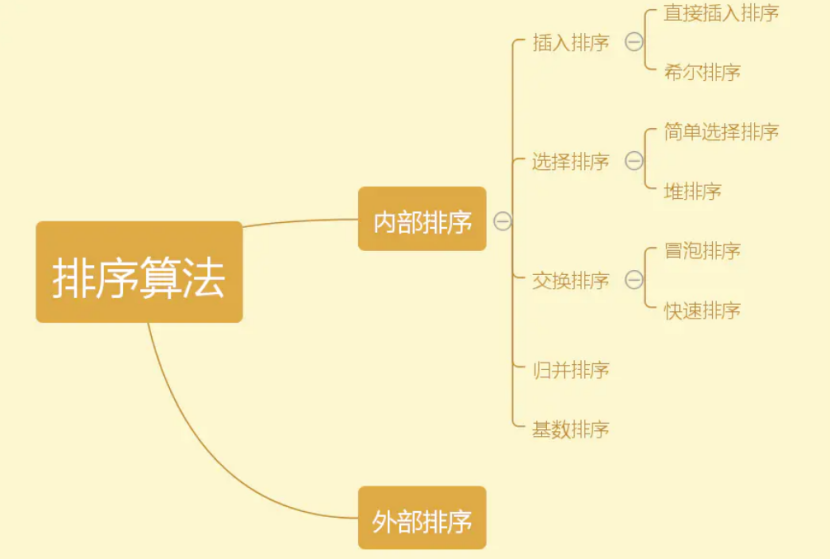
1.1 插入排序
1.11 直接插入排序
思想:将数组中的所有元素依次跟前面已经排好的元素相比较, 如果选择的元素比已排序的元素小,则交换,直到全部元素都比较过。
一句话:待排与前比,遇小则插入

def insert_sort(L):
# 遍历数组种的元素,其中0索引默认已排序,因此从1开始
for x in range(1,len(L)):
#将该元素依次与已排序好的前序数组比较,如果该元素小,则交换
for i in range(x-1,-1,-1):
if L[i]>L[i+1]:
temp=L[i+1]
L[i+1]=L[i]
L[i]=temp
return L
L=[2,3,5,1]
print('排序前的数组:',L)
print('排序后的数组:',insert_sort(L))

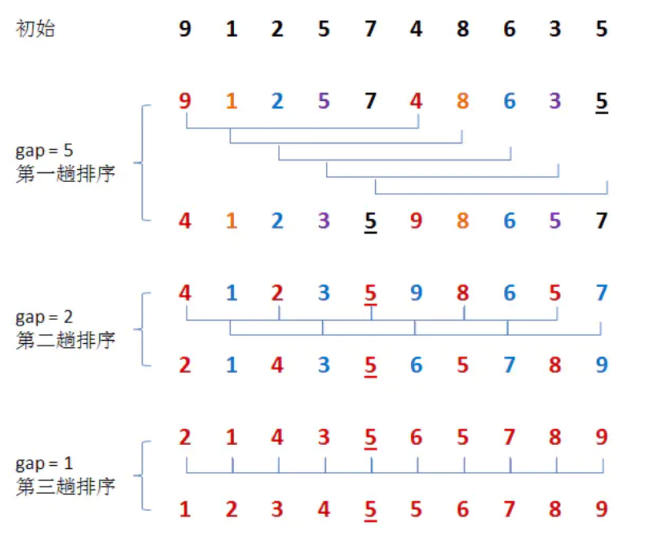
1.12 希尔排序
思想:将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
第一层循环:将gap依次折半,对序列进行分组,直到gap=1
第二、三层循环:也即直接插入排序所需要的两次循环。具体描述见上。
一句话:分组+直接插入排序
def insert_shell(L):
gap=(int)(len(L)/2)
while gap>=1:
#调用直接插入排序
for x in range(gap,len(L)):
#将该元素依次与已排序好的前序数组比较,如果该元素小,则交换
for i in range(x-gap,-1,-gap):
if L[i]>L[i+1]:
temp=L[i+1]
L[i+1]=L[i]
L[i]=temp
#gap依次对半
gap=(int)(gap/2)
return L
L=[2,3,5,1]
print('排序前的数组:',L)
print('排序后的数组:',insert_shell(L))
1.2 选择排序
1.21 简单选择排序
思想:从待排序序列中,找到关键字最小的元素;
如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;从余下的 N - 1 个元素中,找出关键字最小的元素,重复(1)、(2)步,直到排序结束。
因此我们可以发现,简单选择排序也是通过两层循环实现。
第一层循环:依次遍历序列当中的每一个元素
第二层循环:将遍历得到的当前元素依次与余下的元素进行比较,符合最小元素的条件,则交换。
一句话:待排的选最小,并与第一个交换
def select_sort(L):
#依次遍历序列中的元素
for x in range(0,len(L)):
#假设当前位置是待排序的最小值
minimum=L[x]
#将该元素与剩下的元素依次比较寻找最小的元素
for i in range(x+1,len(L)):
if L[i]<minimum:
temp=L[i]
L[i]=minimum
minimum= L[i]
#将最小值赋给当前位置
L[x]=minimum
return L
L=[2,3,5,1,4]
print('排序前的数组:',L)
print('排序后的数组:',insert_shell(L))
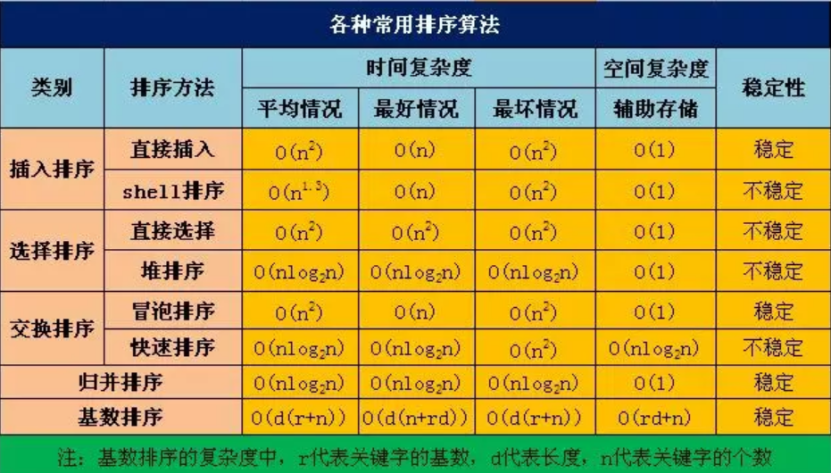
算法复杂度
O
(
n
2
)
O{(n^2)}
O(n2),

1.22 堆排序???
堆:本质是一种数组对象,特别重要的一点性质:任意的叶子节点小于(或大于)它所有的父节点。分为大顶堆和小顶堆,大顶堆要求节点的元素都要大于其孩子,小顶堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求。利用堆排序,就是基于大顶堆或者小顶堆的一种排序方法。下面,我们通过大顶堆来实现。一般升序采用大顶堆,降序采用小顶堆。
基本思想:
1.首先将序列构建称为大顶堆;
(这样满足了大顶堆那条性质:位于根节点的元素一定是当前序列的最大值)

2.取出当前大顶堆的根节点,将其与序列末尾元素进行交换;
(此时:序列末尾的元素为已排序的最大值;由于交换了元素,当前位于根节点的堆并不一定满足大顶堆的性质)
3.对交换后的n-1个序列元素进行调整,使其满足大顶堆的性质;
def build(arr, root, end):
while True:
child = 2 * root + 1 # 左子节点的位置
if child > end: # 若左子节点超过了最后一个节点,则终止循环
break
if (child + 1 <= end) and (arr[child + 1] > arr[child]): # 若右子节点在最后一个节点之前,并且右子节点比左子节点大,则我们的孩子指针移到右子节点上
child += 1
if arr[child] > arr[root]: # 若最大的孩子节点大于根节点,则交换两者顺序,并且将根节点指针,移到这个孩子节点上
arr[child], arr[root] = arr[root], arr[child]
root = child
else:
break
def heap_sort(arr):
n = len(arr)
first_root = n // 2 - 1 # 确认最深最后的那个根节点的位置
for root in range(first_root, -1, -1): # 由后向前遍历所有的根节点,建堆并进行调整
build(arr, root, n - 1)
for end in range(n - 1, 0, -1): # 调整完成后,将堆顶的根节点与堆内最后一个元素调换位置,此时为数组中最大的元素,然后重新调整堆,将最大的元素冒到堆顶。依次重复上述操作
arr[0], arr[end] = arr[end], arr[0]
build(arr, 0, end - 1)
# 测试数据
if __name__ == '__main__':
import random
arr=[16,14,10,8,7,9,3,2,4,1]
print("原始数据:", arr)
heap_sort(arr)
print("堆排序结果:", arr)

1.3 交换排序
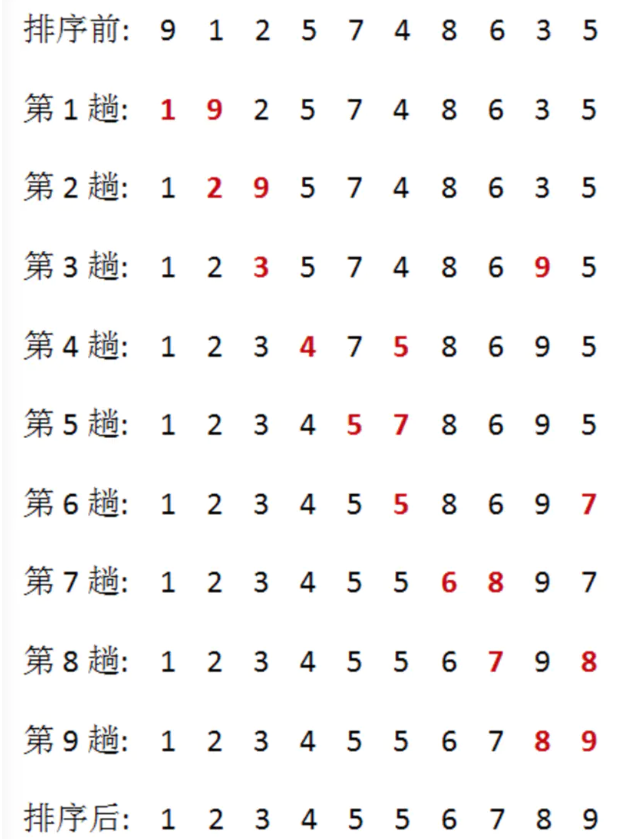
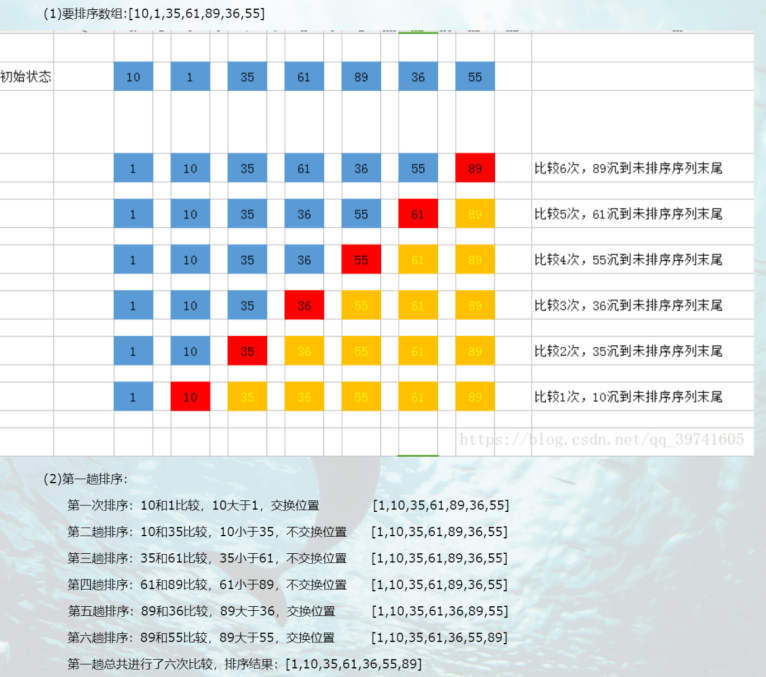
1.31 冒泡排序
思想:1.将序列当中的左右元素,依次比较,保证右边的元素始终大于左边的元素;
( 第一轮结束后,序列最后一个元素一定是当前序列的最大值;)
2.对序列当中剩下的n-1个元素再次执行步骤1。
3.对于长度为n的序列,一共需要执行n-1轮比较
(利用while循环可以减少执行次数)
一句话:左右比,最右最大
def bubble_sort(L):
ll= len(L)
# 需要ll-1轮交换
for x in range(1,ll):
#每一轮交换,都将序列当中的左右元素比较
for i in range(0,ll-x):
if L[i]>L[i+1]:
temp=L[i+1]
L[i+1]=L[i]
L[i]=temp
return L
L=[2,3,5,1]
print('排序前的数组:',L)
print('排序后的数组:',insert_sort(L))
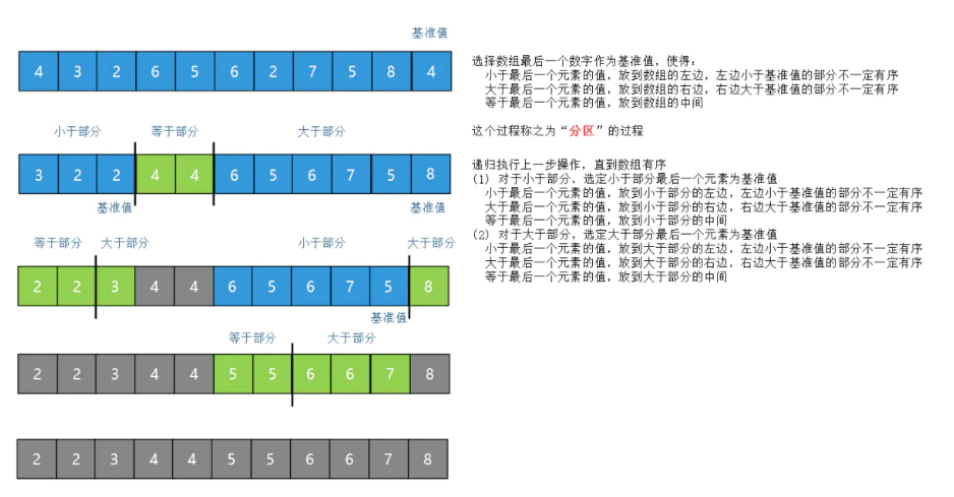
1.32 快速排序
一句话:选基点,比大小、放左右
def quick_sort(array, l, r):
if l<r:
q = partition(array, l, r)
#依次对基点左边、右边的位置重复上述过程
quick_sort(array, l, q - 1)
quick_sort(array, q + 1, r)
def partition(array, l, r):
#选取基点值
x = array[r]
i = l - 1
for j in range(l, r):
if array[j] <= x:
#如果比较的j元素比右的值大,i就不加1,i=j,进行下一次j+1,
#若j+1的元素比右边的值小,则会与i值交换
i += 1
array[i], array[j] = array[j], array[i]
array[i + 1], array[r] = array[r], array[i+1]
#返回基点存放的位置
return i + 1
data = [45,3,2,6,3,78,5,44,22,65,46]
quick_sort(data, 0, len(data)-1)
data#结果:[2, 3, 3, 5, 6, 22, 44, 45, 46, 65, 78]
def quicksort(array) :
if len(array) < 2 :
return array #基线条件:为空或者只包含一个元素
else :
pivot = array[0] #递归条件
less = [i for i in array[1:] if i <= pivot] #小于的放左边
greate = [i for i in array[1:] if i > pivot] #大于的放右边
return quicksort(less) + [pivot] + quicksort(greate)
array = [1,5,2,3,7,6]
print(quicksort(array))

快速排序的时间复杂度平均情况为
O
(
l
o
g
n
)
O{(logn)}
O(logn),最差情况为
O
(
n
2
)
O{(n^2)}
O(n2)
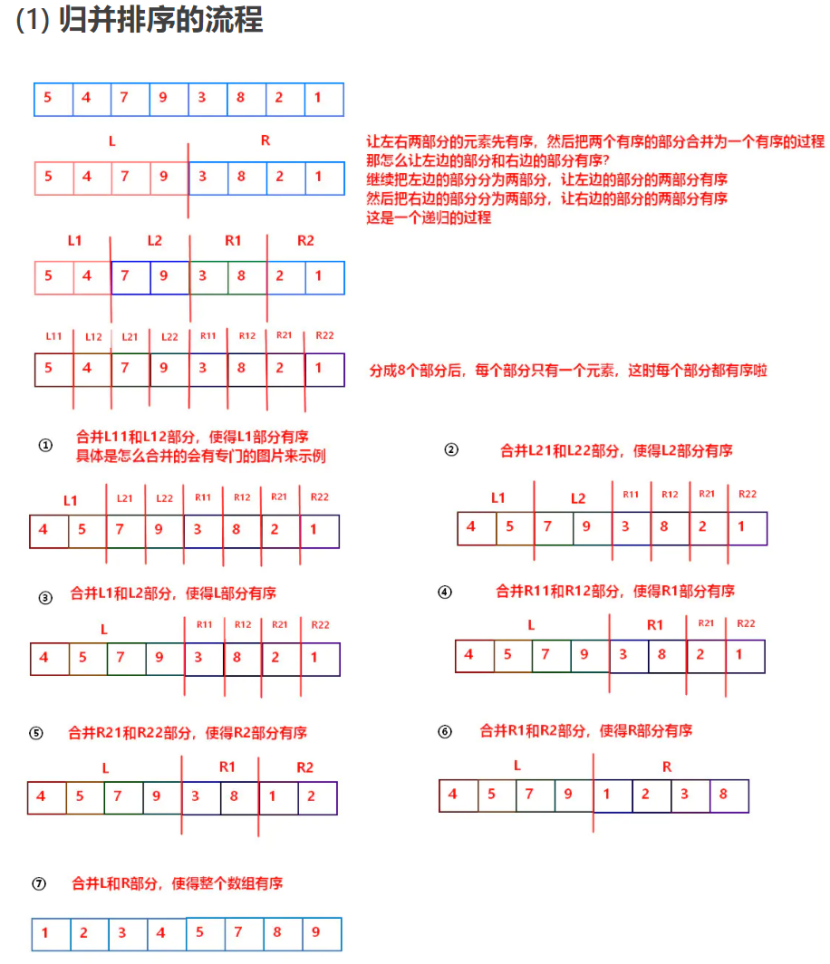
1.4 归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个典型的应用。它的基本操作是:将已有的子序列合并,达到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
def merge(s1,s2,s):
"""将两个列表是s1,s2按顺序融合为一个列表s,s为原列表"""
# j和i就相当于两个指向的位置,i指s1,j指s2
i = j = 0
while i+j<len(s):
# j==len(s2)时说明s2走完了,或者s1没走完并且s1中该位置是比s2中的小
if j==len(s2) or (i<len(s1) and s1[i]<s2[j]):
s[i+j] = s1[i]
i += 1
else:
s[i+j] = s2[j]
j += 1
def merge_sort(s):
"""先不断对列表分组,一直递归道每组只有一个元素为止,再调用merge函数合并,再合并的过程中就完成了排序"""
n = len(s)
# 剩一个或没有直接返回,不用排序
if n < 2:
return
# 拆分
mid = n // 2
s1 = s[0:mid]
s2 = s[mid:n]
# 子序列递归调用排序
merge_sort(s1)
merge_sort(s2)
# 合并,实际上下面一行调用的s是不断细分的和,s1+s2=s
merge(s1,s2,s)
data = [45,3,2,6,3,78,5,44,22,65,46]
merge_sort(data)
data#结果:[2, 3, 3, 5, 6, 22, 44, 45, 46, 65, 78]
1.5 基数排序
1.51 桶排序
桶排序也称为箱排序(Bin Sort),其基本思想是:设置若干个桶,依次扫描待排序的记录R[0],R[1],…,R[n-1],把关键字在某个范围内的记录全都装入到第k个桶里(分配),然后按序号依次将各非空的桶首尾连接起来(收集)。
对于桶排序来说,分配过程的时间是O(n);收集过程的时间为O(m)(采用链表来存储输入的待排序记录)或O(m+n)。因此,桶排序的时间为O(m+n),若桶个数m的数量级为O(n),则桶排序的时间是线性的,即O(n)。
排序一个数组[5,3,6,1,2,7,5,10]值都在1-10之间,
建立10个桶:[0 0 0 0 0 0 0 0 0 0] 桶,[1 2 3 4 5 6 7 8 9 10] 桶代表的值,遍历数组,
第一个数字5,第五个桶加1[0 0 0 0 1 0 0 0 0 0]
第二个数字3,第三个桶加1[0 0 1 0 1 0 0 0 0 0]
遍历后[1 1 1 0 2 1 1 0 0 1]
输出[1 2 3 5 5 6 7 10]
前面说的排序算法 ,大部分时间复杂度都是O( n 2 n^2 n2),也有部分排序算法时间复杂度是O( n l o g n nlogn nlogn)。而桶式排序却能实现O(n)的时间复杂度。但桶排序的缺点是:首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间,其次待排序的元素都要在一定的范围内等等。
1.52 基数排序
基数排序是对桶排序的一种改进,这种改进是让“桶排序”适合于更大的元素值集合的情况,而不是提高性能。
基数排序是 将整数按位数切割成不同的数字,然后对每个位数上的数字进行分别比较。
基数排序的方式可以采用LSD (Least sgnificant digital) 或 MSD (Most sgnificant digital)方法,LSD 的排序方式由键值的最右边开始,而 MSD 则相反,由键值的最左边开始。LSD的基数排序更适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好。比如看下图:

1.53 实例分析
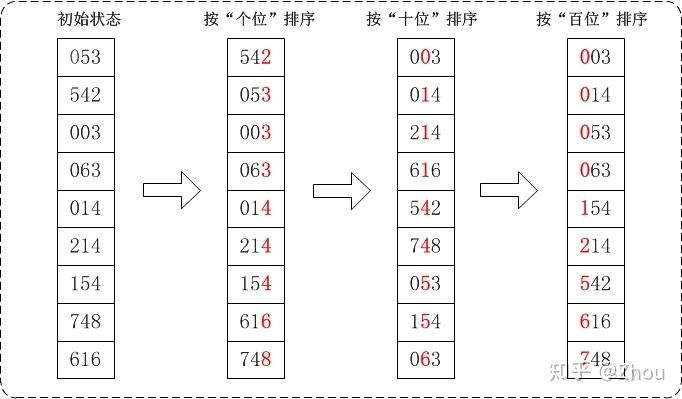
假设我们有输入数组A {53, 3, 542, 748, 14, 214, 154, 63, 616}. 这里数组位数比较小,所以我们采用LSD 的基数排序。
- 我们这里先在数位较短的数前面的位数上补上零,比如53补上至053,3补上至003,14补上至014,63补上至063。现在的数组表现形式为{053, 003, 542, 748, 014, 214, 154, 063, 616}。我们将它们放置至一个个单独的桶中。
- 现在我们首先按照“个位”上数字大小对数组中的数进行排序,排序后结果是{542, 053, 003, 063, 014, 214, 154, 616, 748}.
- 接着按照“十位”上数字大小对数组中的数进行排序,排序后结果是{003, 014, 214, 616, 542, 748, 053, 154, 063}.
- 最后按照“百位”上数字大小对数组中的数进行排序,排序后结果是{003, 014, 053, 063, 154, 214, 542, 616, 748}. 这也是我们的最终输出数组B。
def radix_sort(s):
"""基数排序"""
i = 0 # 记录当前正在排拿一位,最低位为1
max_num = max(s) # 最大值
j = len(str(max_num)) # 记录最大值的位数
while i < j:
bucket_list =[[] for _ in range(10)] #初始化桶数组
for x in s:
bucket_list[int(x / (10**i)) % 10].append(x) # 找到位置放入桶数组
print('第{}轮桶:'.format(i))
print(bucket_list)
s.clear()#清空s中的元素,使其为空列表
for x in bucket_list: # 放回原序列
for y in x:
s.append(y)
print('第{}轮列表:'.format(i))
print(s)
i += 1
if __name__ == '__main__':
a = [53,3,542,748,14,214,154,63,616]
radix_sort(a)

1.5 归并排序和快速排序的区别
1.联系
原理都是基于分而治之,首先把待排序的数组分为两组,然后分别对两组排序,最后把两组结果合并起来。
2.区别
进行分组的策略不同,合并的策略也不同。
归并的分组(按位置一半一半)策略:是假设待排序的元素存放在数组中,那么把数组前面的一半元素作为一组,后面一半作为另一组。
快速排序的分组(按值的大小)策略:则是根据元素的值来分的,大于某个值的元素一组,小于某个值的元素一组。
快速排序在分组的时候已经根据元素的大小来分组了,而合并时,只需要把两个分组合并起来就可以了。
归并排序则需要对两个有序的数组根据大小合并。















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









