







在看整数对象之前,要先看一下python最基本的一个数据结构,即PyObject,它是python对象机制的核心
[Include/object.h]
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
可以看到PyObject的定义中,有一个整型变量ob_refcnt,这个与python的垃圾回收机制有关,是用来计数的,然后再来看一下__PyObject_HEAD_EXTRA的定义
[Include/object.h]
#ifdef Py_TRACE_REFS
/* Define pointers to support a doubly-linked list of all live heap objects. */
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
即如果定义了Py_TRACE_REFS,那么python的对象就都变成了一个双向列表,接下来看一下Py_ssize_t的定义
[Include/pyport.h]
typedef intptr_t Py_intptr_t;
typedef Py_intptr_t Py_ssize_t;
[Modules/_decimal/libmpdec/vcstdint.h]
#ifdef _WIN64 // [
typedef __int64 intptr_t;
typedef unsigned __int64 uintptr_t;
#else // _WIN64 ][
typedef _W64 int intptr_t;
typedef _W64 unsigned int uintptr_t;
#endif // _WIN64 ]
从定义里面可以看出来,在64位系统中,Py_ssize_t是一个64位带符号整型。而在32位系统中则为int._W64,这是为了在32位系统中兼容64位,即Py_ssize_t实际上就是一个int。_typeobject是python中的一个特殊的对象,主要包含了类型名,创建该类型对象时分配内存空间大小的信息等。
接下来时python的另一个特性,定长与不定长对象
这和python的可变对象与不可变对象时不同的概念。定长对象是指不包含可变长度数据的对象,比如整型对象,无论整型对象的值有多大都可以保存在整型变量中,即每个整型变量占用的内存大小是相同的。
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
这个就是不定长对象的定义,只是比定长对象多了一个变量ob_size,用来指明所容纳的元素的个数。
在python2中还会将整型分为int和long,而在python3中就只使用long了,即长整型
[Include/longintrepr.h]
typedef uint32_t digit;
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
typedef struct _longobject PyLongObject;
这里很是纳闷,为什么要用一个长度为1的数组来存储数据呢?(emmm,思考。。。。)
虽然在定义中包含了ob_size字段,但是并不能说整型是不定长对象
PyTypeObject PyLong_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"int", /* tp_name */
offsetof(PyLongObject, ob_digit), /* tp_basicsize */
sizeof(digit), /* tp_itemsize */
long_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
long_to_decimal_string, /* tp_repr */
&long_as_number, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
(hashfunc)long_hash, /* tp_hash */
0, /* tp_call */
long_to_decimal_string, /* tp_str */
PyObject_GenericGetAttr, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE |
Py_TPFLAGS_LONG_SUBCLASS, /* tp_flags */
long_doc, /* tp_doc */
0, /* tp_traverse */
0, /* tp_clear */
long_richcompare, /* tp_richcompare */
0, /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
long_methods, /* tp_methods */
0, /* tp_members */
long_getset, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
0, /* tp_dictoffset */
0, /* tp_init */
0, /* tp_alloc */
long_new, /* tp_new */
PyObject_Del, /* tp_free */
};
在这里面包含了整型类型的所有的元信息,下面看一下如何比较两个整型的大小
static PyObject *
long_richcompare(PyObject *self, PyObject *other, int op)
{
int result;
PyObject *v;
CHECK_BINOP(self, other);
if (self == other)
result = 0;
else
result = long_compare((PyLongObject*)self, (PyLongObject*)other);
/* Convert the return value to a Boolean */
switch (op) {
case Py_EQ:
v = TEST_COND(result == 0);
break;
case Py_NE:
v = TEST_COND(result != 0);
break;
case Py_LE:
v = TEST_COND(result <= 0);
break;
case Py_GE:
v = TEST_COND(result >= 0);
break;
case Py_LT:
v = TEST_COND(result == -1);
break;
case Py_GT:
v = TEST_COND(result == 1);
break;
default:
PyErr_BadArgument();
return NULL;
}
Py_INCREF(v);
return v;
}
更加具体的实现是在下面这个方法中
static int long_compare(PyLongObject *a, PyLongObject *b)
{
Py_ssize_t sign;
if (Py_SIZE(a) != Py_SIZE(b)) {
sign = Py_SIZE(a) - Py_SIZE(b);
}
else {
Py_ssize_t i = Py_ABS(Py_SIZE(a));
while (--i >= 0 && a->ob_digit[i] == b->ob_digit[i]);
if (i < 0)
sign = 0;
else {
sign = (sdigit)a->ob_digit[i] - (sdigit)b->ob_digit[i];
if (Py_SIZE(a) < 0)
sign = -sign;
}
}
return sign < 0 ? -1 : sign > 0 ? 1 : 0;
}
由于在定义的时候只使用了长度为1的int数组,所以简单来说,就是将两个数值直接进行比大小,加法与减法都大同小异没有什么太大的区别
乘法采用的是更高效的Karatsuba算法,普通乘法复杂度一般都是O(n^2),而这个算法,仅有O(nlog3),这个算法是将大数分成两段较小的数,通过三次加法和位移以及加法完实现的
假设有两个数可以写成下面这种形式
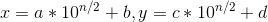
n为数字的位数,如果数字为偶数位,则a,c为两个数的前(n/2)位,若位奇数的话,a,c可以为前(n/2)+1位。那么x*y就变成了下面这样
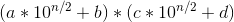
进一步计算这个等式
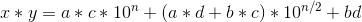
按照这个公式是没有办法在一次计算过程中只进行三次乘法的,在进行化简,我们要算的只是bc+ad的值。然后再通过位移就可以得出答案了。
python源码中的实现
static PyLongObject *
k_mul(PyLongObject *a, PyLongObject *b)
{
Py_ssize_t asize = Py_ABS(Py_SIZE(a));
Py_ssize_t bsize = Py_ABS(Py_SIZE(b));
PyLongObject *ah = NULL;
PyLongObject *al = NULL;
PyLongObject *bh = NULL;
PyLongObject *bl = NULL;
PyLongObject *ret = NULL;
PyLongObject *t1, *t2, *t3;
Py_ssize_t shift; /* the number of digits we split off */
Py_ssize_t i;
/* (ah*X+al)(bh*X+bl) = ah*bh*X*X + (ah*bl + al*bh)*X + al*bl
* Let k = (ah+al)*(bh+bl) = ah*bl + al*bh + ah*bh + al*bl
* Then the original product is
* ah*bh*X*X + (k - ah*bh - al*bl)*X + al*bl
* By picking X to be a power of 2, "*X" is just shifting, and it's
* been reduced to 3 multiplies on numbers half the size.
*/
/* We want to split based on the larger number; fiddle so that b
* is largest.
*/
if (asize > bsize) {
t1 = a;
a = b;
b = t1;
i = asize;
asize = bsize;
bsize = i;
}
/* Use gradeschool math when either number is too small. */
i = a == b ? KARATSUBA_SQUARE_CUTOFF : KARATSUBA_CUTOFF;
if (asize <= i) {
if (asize == 0)
return (PyLongObject *)PyLong_FromLong(0);
else
return x_mul(a, b);
}
/* If a is small compared to b, splitting on b gives a degenerate
* case with ah==0, and Karatsuba may be (even much) less efficient
* than "grade school" then. However, we can still win, by viewing
* b as a string of "big digits", each of width a->ob_size. That
* leads to a sequence of balanced calls to k_mul.
*/
if (2 * asize <= bsize)
return k_lopsided_mul(a, b);
/* Split a & b into hi & lo pieces. */
shift = bsize >> 1;
if (kmul_split(a, shift, &ah, &al) < 0) goto fail;
assert(Py_SIZE(ah) > 0); /* the split isn't degenerate */
if (a == b) {
bh = ah;
bl = al;
Py_INCREF(bh);
Py_INCREF(bl);
}
else if (kmul_split(b, shift, &bh, &bl) < 0) goto fail;
ret = _PyLong_New(asize + bsize);
if (ret == NULL) goto fail;
#ifdef Py_DEBUG
/* Fill with trash, to catch reference to uninitialized digits. */
memset(ret->ob_digit, 0xDF, Py_SIZE(ret) * sizeof(digit));
#endif
/* 2. t1 <- ah*bh, and copy into high digits of result. */
if ((t1 = k_mul(ah, bh)) == NULL) goto fail;
assert(Py_SIZE(t1) >= 0);
assert(2*shift + Py_SIZE(t1) <= Py_SIZE(ret));
memcpy(ret->ob_digit + 2*shift, t1->ob_digit,
Py_SIZE(t1) * sizeof(digit));
/* Zero-out the digits higher than the ah*bh copy. */
i = Py_SIZE(ret) - 2*shift - Py_SIZE(t1);
if (i)
memset(ret->ob_digit + 2*shift + Py_SIZE(t1), 0,
i * sizeof(digit));
/* 3. t2 <- al*bl, and copy into the low digits. */
if ((t2 = k_mul(al, bl)) == NULL) {
Py_DECREF(t1);
goto fail;
}
assert(Py_SIZE(t2) >= 0);
assert(Py_SIZE(t2) <= 2*shift); /* no overlap with high digits */
memcpy(ret->ob_digit, t2->ob_digit, Py_SIZE(t2) * sizeof(digit));
/* Zero out remaining digits. */
i = 2*shift - Py_SIZE(t2); /* number of uninitialized digits */
if (i)
memset(ret->ob_digit + Py_SIZE(t2), 0, i * sizeof(digit));
/* 4 & 5. Subtract ah*bh (t1) and al*bl (t2). We do al*bl first
* because it's fresher in cache.
*/
i = Py_SIZE(ret) - shift; /* # digits after shift */
(void)v_isub(ret->ob_digit + shift, i, t2->ob_digit, Py_SIZE(t2));
Py_DECREF(t2);
(void)v_isub(ret->ob_digit + shift, i, t1->ob_digit, Py_SIZE(t1));
Py_DECREF(t1);
/* 6. t3 <- (ah+al)(bh+bl), and add into result. */
if ((t1 = x_add(ah, al)) == NULL) goto fail;
Py_DECREF(ah);
Py_DECREF(al);
ah = al = NULL;
if (a == b) {
t2 = t1;
Py_INCREF(t2);
}
else if ((t2 = x_add(bh, bl)) == NULL) {
Py_DECREF(t1);
goto fail;
}
Py_DECREF(bh);
Py_DECREF(bl);
bh = bl = NULL;
t3 = k_mul(t1, t2);
Py_DECREF(t1);
Py_DECREF(t2);
if (t3 == NULL) goto fail;
assert(Py_SIZE(t3) >= 0);
(void)v_iadd(ret->ob_digit + shift, i, t3->ob_digit, Py_SIZE(t3));
Py_DECREF(t3);
return long_normalize(ret);
fail:
Py_XDECREF(ret);
Py_XDECREF(ah);
Py_XDECREF(al);
Py_XDECREF(bh);
Py_XDECREF(bl);
return NULL;
}
python的小整数对象与大整数对象
在实际的编程中,对于一些频繁使用的整数对象,python使用了对象池技术解决了这个问题,从而不用频繁的申请空间和释放空间。当然,对于小整数的范围是可以通过修改源码来控制的
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
小整数的范围一般是[-5, 257)
static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
这个变量是用来保存小整数的,即小整数对象池。
那么大整数是如何解决的呢?python运行环境会提供一块内存空间由这些大整数轮流使用,即谁需要谁就使用,这样就免去了不断的malloc与free。
大整数没有通过对象池技术来解决这个问题,在源码中没有找到相关代码,在python2中,是通过申请一块内存,用来存储大整数的,当一个大整数对象被回收过后并不会释放这块内存,而是会有一个空闲指针指向这块内存,以便下次使用。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









