







一.概述
目标检测问题中的每个图片都可能包含一些不同类别的物体。如前所述,需要评估模型的物体分类和定位性能。因此,用于图像分类问题的标准指标precision不能直接应用于此。 这就是为什么需要mAP。
对于任何算法,评估指标需要知道ground truth(真实标签)数据。 我们只知道训练、验证和测试数据集的ground truth。对于目标检测问题,ground truth包括图像中物体的类别以及该图像中每个物体的真实边界框。
二.查准率与查全率(Precision and recall)
查准率(precision)和查全率(recall)。对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数。分类结果的“混淆矩阵”(confusion matrix)如表所示:
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率P和查全率R分别定义为:

举个例子:
Precision:衡量你的模型预测准确度。即预测的数目中正确的百分比,比如你预测100个 图片是苹果,其中80个真的是苹果,那么你的Precision为0.8
recall:召回表明你找到所有的苹果的数目。例如,总共有100张苹果图片,你成功找到其 中50张,那么你的recall为0.
一般来说查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
以查准率为纵轴,查全率为横轴作图,就得到了查准率-查全率曲线,简称"P-R曲线".
平衡点(BER):查准率=查全率时的取值,用来比较模型好坏.
三.交并比(IoU)
IoU是预测框与ground truth的交集和并集的比值。这个量也被称为Jaccard指数,并于20世纪初由Paul Jaccard首次提出。

为了计算precision和recall,与所有机器学习问题一样,我们必须鉴别出True Positives(真正例)、False Positives(假正例)、True Negatives(真负例)和 False Negatives(假负例)。
假设边界框对应的IoU大于某个阈值(一般来说,比较常用的IoU阈值是0.5),我们就可以说这个预测的边界框是对的,或者说可以被划分为TP中。反之如果IoU小于阈值,那么这个预测的边界框就是错的,或者说是一个FP。如果对于图像中某个物体来说,我们的模型没有预测出对应的边界框,那么这种情况就可以被记为一次FN。
- True Positive (TP): IOU>=阈值的检测框
- False Positive (FP): IOU<阈值的检测框
- False Negative (FN): 未被检测到的GT
- True Negative (TN): 忽略不计
对于每一个图片,ground truth数据会给出该图片中各个类别的实际物体数量。我们可以计算每个Positive预测框与ground truth的IoU值,并取最大的IoU值,认为该预测框检测到了那个IoU最大的ground truth。然后根据IoU阈值,我们可以计算出一张图片中各个类别的正确检测值(True Positives, TP)数量以及错误检测值数量(False Positives, FP)。据此,可以计算出各个类别的precision:
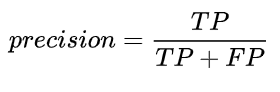
既然我们已经得到了正确的预测值数量(True Positives),也很容易计算出漏检的物体数(False Negatives, FN)。据此可以计算出Recall(其实分母可以用ground truth总数):
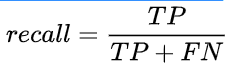
四.AP值
AP:PR曲线下面积的近似,是一个0~1之间的数值,也可用来衡量模型的performance
- PR曲线比较直观,但由于曲线的上下震荡,不方便比较不同模型的PR曲线
- AP是一个数字,模型的AP大,则模型更好,方便比较不同模型
对于AP的计算,VOC采用过两种不同方法:
11点插值法:
VOC2010以前,选取当Recall >= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,AP是这11个Precision的平均值,此时只由11个点去近似PR曲线下面积。
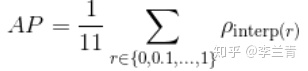
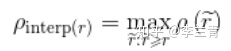
是recall=
时的precision
所有点插值法
VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值:
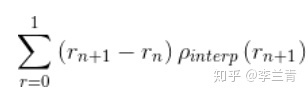
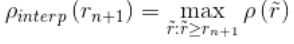
是recall=
时的precision
由于此方法用了所有点去近似PR曲线下面积,计算的AP比11点插值法更准确。
五.MAP(mean Average Precision, 即各类别AP的平均值)
对于各个类别,分别按照上述方式计算AP,取所有类别的AP平均值就是mAP。这就是在目标检测问题中mAP的计算方法。可能有时会发生些许变化,如COCO数据集采用的计算方式更严格,其计算了不同IoU阈值和物体大小下的AP.
在评测时,COCO评估了在不同的交并比(IoU)[0.5:0.05:0.95]共10个IoU下的AP,并且在最后以这些阈值下的AP平均作为结果,记为mAP@[.5, .95]。
而在Pascal VOC中,检测结果只评测了IOU在0.5这个阈值下的AP值。因此相比VOC而言,COCO数据集的评测会更加全面:不仅评估到物体检测模型的分类能力,同时也能体现出检测模型的定位能力。因此在IoU较大如0.8时,预测框必须和真实的框具有很大的重叠比才能被视为正确。
六.计算示例
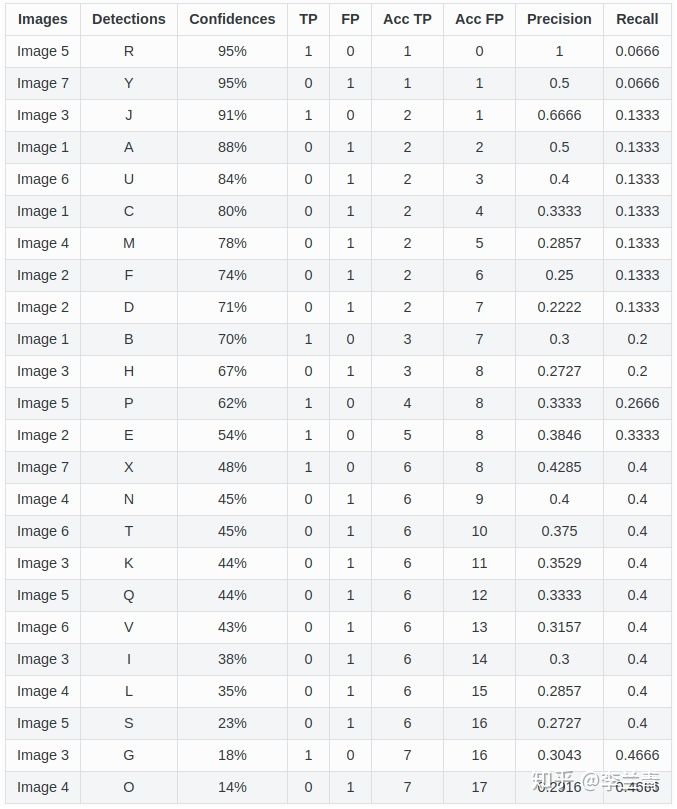
对某一类,共7张图片,15个GT(绿色框),24个预测BBOX(红色框),见下图,图中百分比为预测边框属于该类别的置信度。
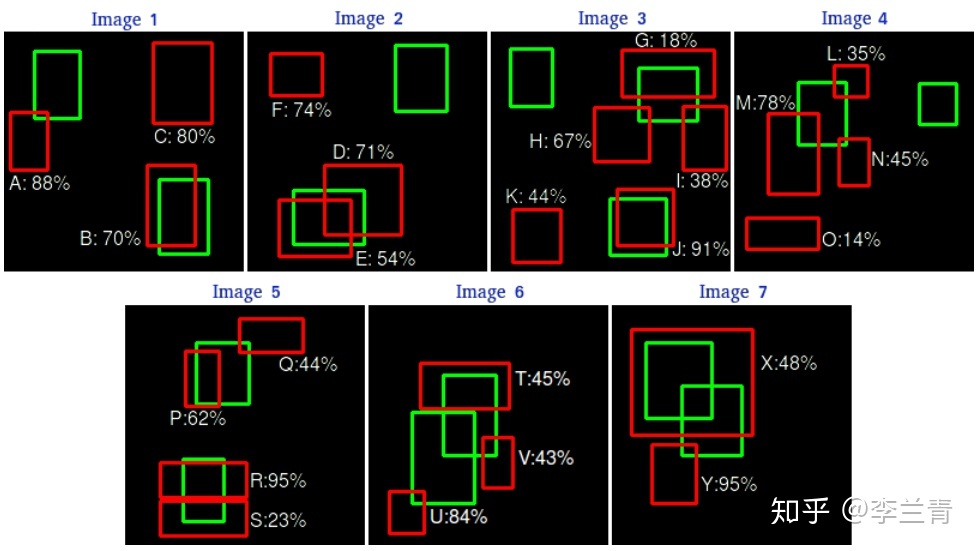
6.1TP、FP判定
- 对于每个BBOX,如果它与图片内某GT的IOU>0.3, 则该BBOX为TP,否则为FP
- 一个GT只能对应一个TP,如果一个GT对应了多个满足IOU阈值的BBOX,我们仅选取置信度最高的BBOX作为该GT的TP
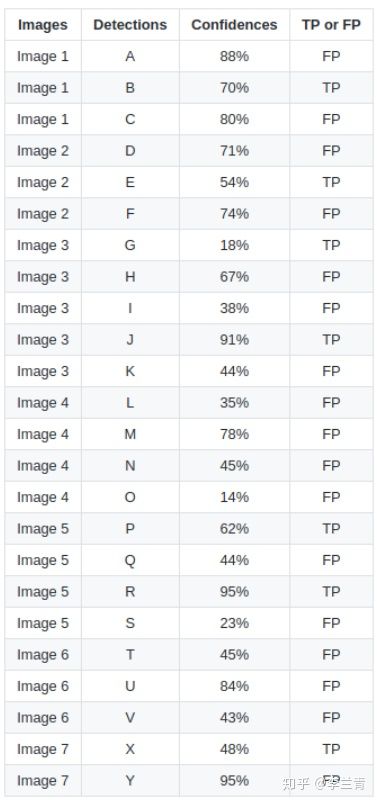
6.2 recall & precision计算
利用confidence给BBOX排序,对每个BBOX都计算对应的precision和recall值,例如:
- 对BBOX R,precision = 1/1 = 1,recall = 1/15=0.0666
- 对BBOX Y,precision = 1/2 = 0.5,recall = 1/15=0.0666
- 对BBOX J,precision = 2/3 = 0.6666,recall = 2/15=0.1333
6.3 AP计算


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









