




 本文深入解析HBase的架构设计,包括其依赖的HDFS与Zookeeper组件的作用,以及RegionServer、HLog、Store的工作原理。详细阐述了HBase数据的写入流程,从客户端操作到wal文件的写入,再到storefile的刷新机制,并介绍了数据读取过程中磁盘访问的必要性及读取策略。
本文深入解析HBase的架构设计,包括其依赖的HDFS与Zookeeper组件的作用,以及RegionServer、HLog、Store的工作原理。详细阐述了HBase数据的写入流程,从客户端操作到wal文件的写入,再到storefile的刷新机制,并介绍了数据读取过程中磁盘访问的必要性及读取策略。
HBASE–详细架构&数据读写
详细架构:
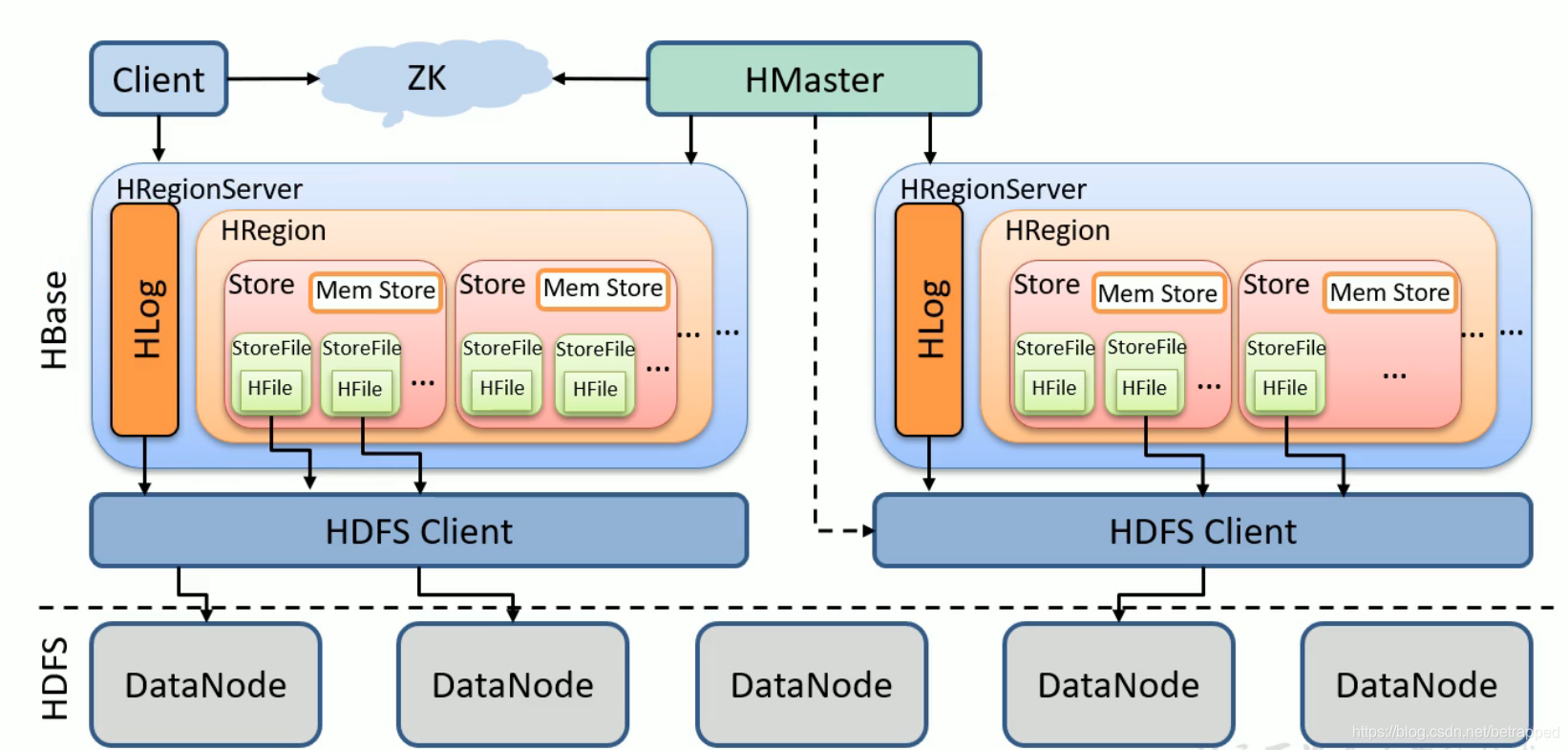
- 底层依赖于HDFS
- Hbase依赖于Zookeeper,Zookeeper分担了HMaster一部分操作(读写数据DML部分),客户端只和ZK交互
- RegionServer用来维护Region的
- HLog类似于HDFS中的edits文件,方式数据的丢失
- store分为内存store和store file,内存store通过刷写写成一个个store file,存在HDFS中
读写流程
数据的读写流程不依赖于Master,但是长期在没有Master的情况下进行数据的读写是不健康的。例如,当一个region过大进行切分之后,没有Master是无法把切分后的数据分配到其他节点上去的。
写流程:
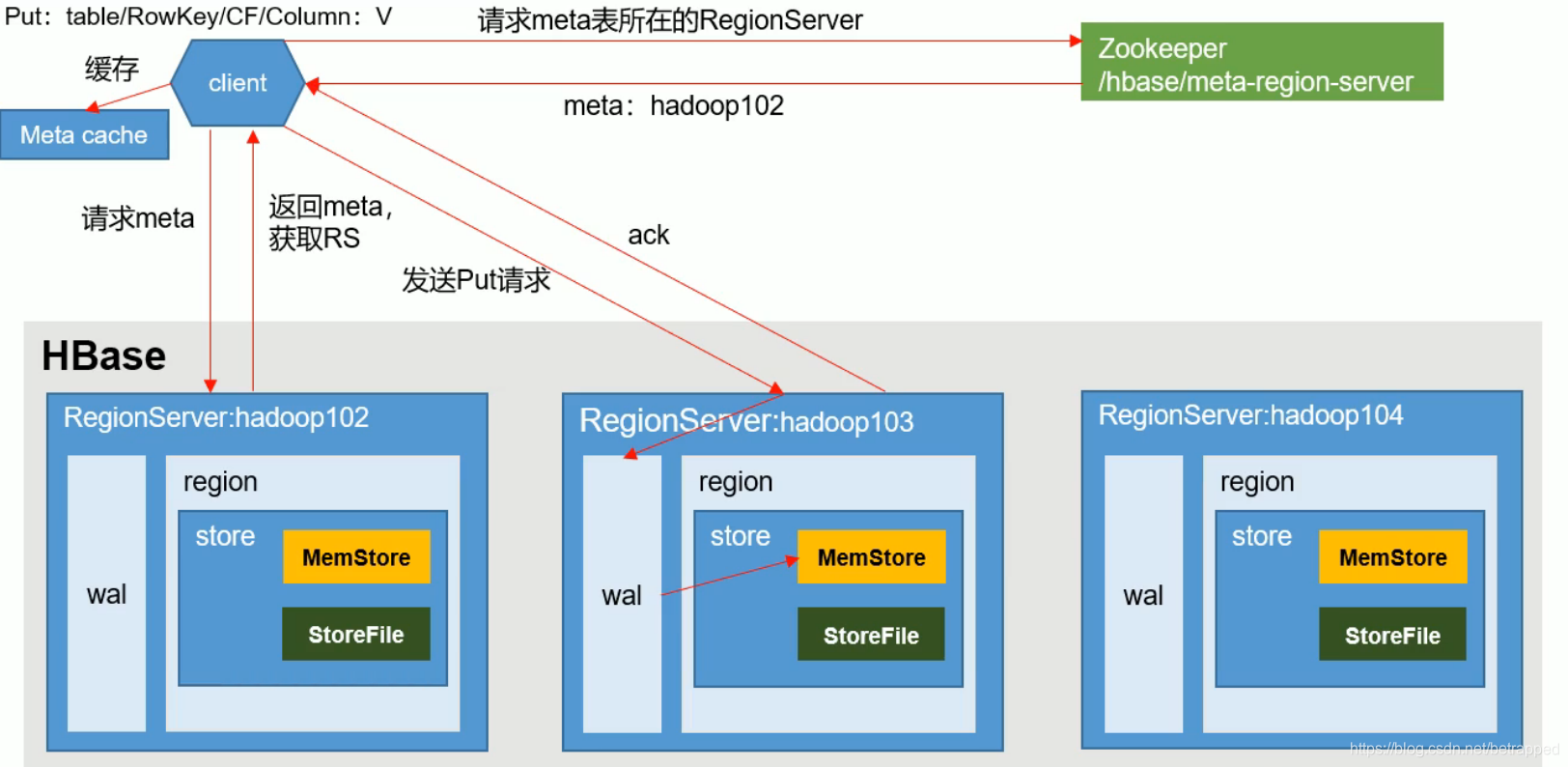
- 请求RegionServer找到meta表
- 通过meta的内容找到目标写入数据的位置信息
- 通过位置信息,往目标表中写入数据。先写wal文件,再写入内存(客户端操作到此为止)
- 后续再把文件写入到storefile中
需要注意的是第三部分,实际实现的过程中,操作信息写入wal但是没有立即同步到hdfs中,而是等写操作进入内存后才同步的。这样的可能会导致数据丢失,hbase框架的处理方式:当wal文件同步失败(doRollBackstore=true)的时候,会进行回滚,把内存中等待同步到hdfs中的数据删除。
关于flush:
- 对于RegionServer的刷写来说:有两个关键点0.4和0.38(0.4*0.95),这两个值对应的都是堆内存的大小,当数据在堆内存中达到0.38时就开始进行刷写,此时RegionServer的数据写操作还不会停止,当数据在堆内存中达到0.4的时候,就开始停止数据的写操作,只进行刷写,知道数据量下降到堆内存的0.4以下。刷写的过程会根据数据大小排序,优先刷写数据量大的数据。时间方面:当内存中最后一次编辑的数据存在时间超过一小时(没有其他写操作)时,就开始进行刷写。
- 对于Region来说:当前Region内存中的数据超过了128M的时候就开始进行刷写
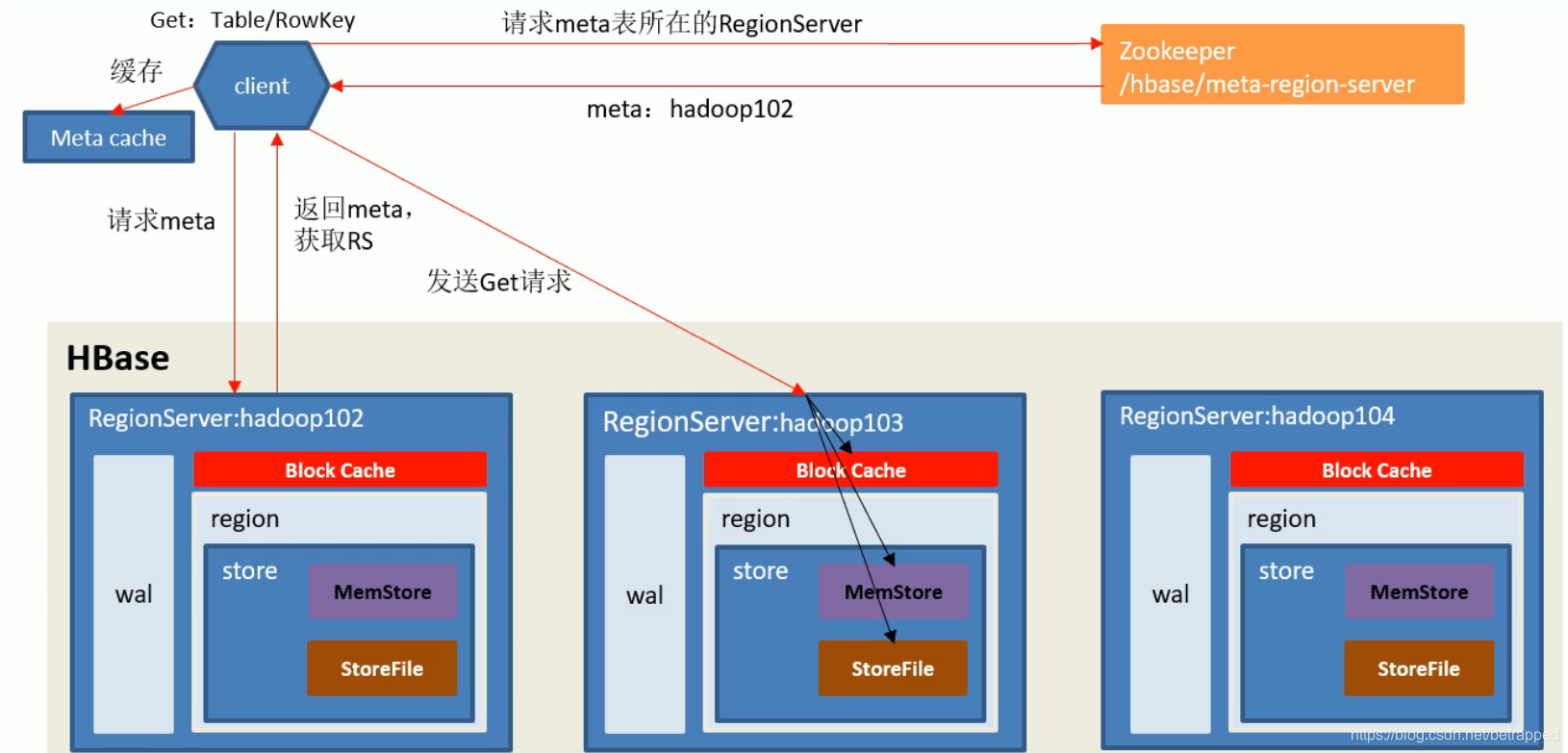
读流程:
HBASE因为存储机制的原因,读流程不论什么情况都是要读取磁盘信息的,所以过程比较慢。
如下图所示,hbase读取数据并不是按照block cache–>memstore–>storefile这样的顺序读取的,而是三个部分都需要读取,最后比较取出的相同的RowKey中时间戳最靠后的那一条显示出来。block cache中有的数据,在读取storefile的时候可以不必再读取,但仅仅只是那一条数据文件不用读取而已。
一定要读磁盘主要是为了防止后写入的数据在内存中还未刷写,但是它的时间戳是自定义的,比磁盘记录的时间戳更靠前,而只读到内存就会导致读出的数据不是时间戳最后的数据。

















 2583
2583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









