







本文为<x86汇编语言:从实模式到保护模式> 第17章笔记
中断和异常
中断和异常概述
中断和异常的作用是指示系统中的某个地方发生一些事件, 需要引起处理器(包括正在执行中的程序和任务)的注意. 当中断和异常发生时, 典型的结果是迫使处理器将控制从当前正在执行的程序或任务转移到另一个历程或任务中去. 该例程叫做中断处理程序, 或者异常处理程序. 如果是一个任务, 则发生任务切换.
1. 中断(Interrupt)
中断包括硬件中断和软中断.
硬件中断是由外围硬件设备发出的中断信号引发的, 以请求处理器提供服务. 当I/O接口发出中断请求时, 会被像8259A和I/O APIC这样的中断控制器收集, 并发送到处理器. 硬件中断完全是随机产生的, 与处理器的执行并不同步. 当中断发生时, 处理器要先执行完当前的指令, 然后才对中断进行处理.
软中断是由 int n 指令引发的中断处理, n是中断号或者叫类型吗.
2. 异常(Exception)
异常就是16位汇编中的内部中断. 它们是处理器内部产生的中断, 表示在指令执行的过程中遇到了错误的状况. 当处理器执行一条非法指令, 或者因条件不具备, 指令不能正常执行时, 将引发这种类型的中断. 以上所列都是异常情况, 所以内部中断又叫异常或者异常中断. 比如在执行除法指令 div/idiv 时, 遇到了被0除的情况(除数是0); 在比如, 使用jmp指令发起任务切换时, 指令的操作数不是一个有效的TSS描述符选择子.
异常分为三种, 第一种是程序错误异常, 指处理器在执行指令的过程中, 检测到了程序中的错误, 并由此而引发的异常.
第二种是软件引发的异常. 这类异常通常由into, int3和bound指令主动发起. 这些指令允许在指令流的当前点上检查实施异常处理的条件是否满足. 举个例子, into指令在执行时, 将检查EFLAGS的OF标志, 如果满足为1的条件, 则引发异常.
第三种是机器检查异常. 这种异常是处理器型号相关的, 也就是说, 每种处理器都不太一样. 无论如何, 处理器提供了一种对硬件芯片内部和总线处理进行检查的机制, 当检测到错误是, 将引发异常.
根据异常情况的性质和严重性, 异常又分为以下三种, 并分别实施不同的处理.
- 故障(Faults). 故障通常是可以纠正的, 比如, 当处理器执行一个访问内存的指令时, 发现那个段或者页不在内存中(P = 0), 此时, 可以在异常处理程序中予以纠正(分配内存, 或者执行磁盘的换入换出操作), 返回时, 程序可以重新启动并不失连续性. 为了做到这一点, 当故障发生时, 处理器把机器状态恢复到引起故障的那条指令之前的状态, 在进入异常处理程序时, 压入栈中的返回地址(CS和EIP的内容)是指向引起故障的那条指令的, 而不像通常那样指向下一条指令. 如此一来, 当中断返回时, 将重新执行引起故障的那条指令, 而且不再出错(如果引起异常的情况已经妥善处理).
- 陷阱(Traps). 陷阱中断通常在执行了截获陷阱条件的指令之后立即产生, 如果陷阱条件成立的话. 陷阱通常用于调试目的, 比如单步中断指令int3和溢出检测指令into. 陷阱中断允许程序或任务在从中断处理过程返回之后继续进行而不失连续性. 因此, 当此异常发生时, 在转入异常处理程序之前, 处理器在栈中压入陷阱截获指令的下一条指令的地址.
- 终止(Aborts). 终止标志着最严重的错误, 诸如硬件错误, 系统表(GDT, LDT等)中的数据不一致或者无效. 这类异常总是无法精确地报告引起错误的指令的位置, 在这种错误发生时, 程序或者任务不可能重新启动. 一个比较典型的终止类异常是"双重故障"(中断号为8), 当发生一次异常之后, 处理器在转入该中断的处理程序时, 又发生了另外的异常(如该中断处理程序所在的段不在内存中, 或者栈溢出). 对于中断处理程序来说, 很难从栈中获得有关如何纠正此类错误的明确信息, 往往是发生极为重大的错误时才伴随着这种异常, 所以在继续执行引起此异常的程序或任务已相当困难, 操作系统通常只能把该任务从系统中抹去.
| 向量 | 助记 | 描述 | 类型 | 错误代码 | 来源 |
| 0 | #DE | 除法错 | 故障 | 无 | div或idiv指令 |
| 1 | #DB | 保留 | |||
| 2 | - | NMI | 中断 | 无 | 不可屏蔽的外部中断 |
| 3 | #BP | 断点 | 陷阱 | 无 | int3指令 |
| 4 | #OF | 溢出 | 陷阱 | 无 | into指令 |
| 5 | #BR | 对数组的引用超出边界 | 故障 | 无 | bound指令 |
| 6 | #UD | 无效或未定义的操作码 | 故障 | 无 | ud2指令, 或保护的操作码 |
| 7 | #NM | 设备不可用(无数学协处理器) | 故障 | 无 | 浮点或者wait/fwait指令 |
| 8 | #DF | 双重故障 | 终止 | 有(0) | 任何会产生异常的指令, NMI或者硬件中断 |
| 9 | 协处理器段超越(保留). 协处理器执行浮点运算时, 至少有两个操作数不在一个段内(跨段) | 故障 | 无 | 浮点指令 | |
| 10 | #TS | 无效TSS | 故障 | 有 | 任务切换或访问TSS |
| 11 | #NP | 段不存在 | 故障 | 有 | 加载段寄存器或者访问系统段 |
| 12 | #SS | 栈段故障 | 故障 | 有 | 栈操作或者加载段寄存器SS |
| 13 | #GP | 常规保护 | 故障 | 有 | 任何内存引用或其他保护异常 |
| 14 | #PF | 页故障 | 故障 | 有 | 任何内存引用 |
| 15 | - | 由Intel处理器保留, 不能使用 | 无 | ||
| 16 | #MF | x87 FPU(浮点处理单元)浮点处理错误 | 故障 | 无 | x87 FPU浮点指令或wait/fwait指令 |
| 17 | #AC | 对齐检查 | 故障 | 有(0) | 任何内存数据引用 |
| 18 | #MC | 机器检查 | 终止 | 无 | 错误代码(如果有的话)和来源是处理器型号相关的 |
| 19 | #XM | SIMD(单指令多数据)浮点异常 | 故障 | 无 | sse/sse2/sse3浮点指令 |
| 20~31 | Intel公司保留, 建议不要使用 | ||||
| 32~255 | 用户自定义的中断 | 中断 | 外部中断, 或者int n指令 |
当中断和异常发生时, NMI和异常的向量是由处理器自动给出的; 硬件的向量是由I/O中断控制器芯片送给处理器的; 软中断的向量是由指令中的操作数给出的. 从80486之后开始, 处理器内部一般集成了浮点运算部件x87FPU, 不再需要安装独立的数学协处理器, 所以有些和浮点运算有关的异常可能不会产生(比如向量为9的协处理器段超越故障). wait和fwait指令用于主处理器和浮点处理部件(FPU)之间的同步, 它们应当放在浮点指令之后, 以捕捉任何我浮点异常.
- bound r16, m16
- bound r32, m32
ud2指令是从Pentium Pro处理器开始引入的, 它只有操作码而没有操作数, 执行该指令时, 会引发一个无效操作码异常. 该指令没有别的用处, 典型的用于软件测试. 尽管异常是该指令故意引发的, 但是, 在转入异常处理程序时, 压入栈中的指令指针是指向该指令的, 而非下一条指令.
中断描述符表 中断门和陷阱门
在实模式下, 位于内存最低端的1KB内存, 是中断向量表IVT, 定义了256种中断的入口地址, 包括16位段地址和16位段内偏移量. 当中断发生时, 处理器要么自发产生一个中断向量, 要么从int n 指令中得到中断向量, 或者从外部的中断控制器接受一个中断向量. 然后, 它将该向量作为索引访问中断向量表. 具体做法是, 乘以4, 作为表内偏移量访问中断向量表, 从中取得中断处理过程的段地址和偏移地址, 并转到那里执行.
在保护模式下, 处理器对中断的管理是相似的, 但并非使用传统的中断向量表来保存中断处理过程的地址, 而是中断描述符表(Interrupt Descriptor Table: IDT). 顾名思义, 这个表里, 保存的是和中断处理过程有关的描述符, 包括中断门, 陷阱门和任务门.
任务门的格式在<任务切换>中有说, 中断门和陷阱的格式如下图所示.
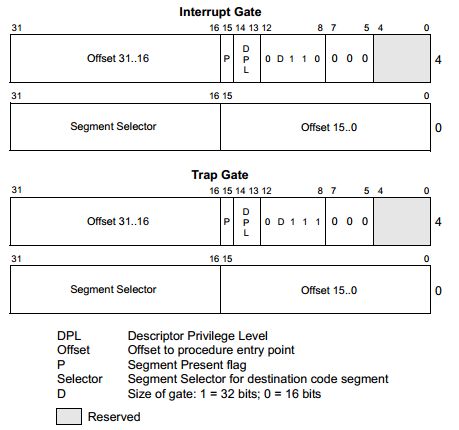
事实上, 调用门, 任务门, 中断门和陷阱门的描述符非常相似, 从大的方面来说, 因为都用于实施控制转移, 故都包括16位的目标代码段选择子, 以及32位的段内偏移量. 由上图可知, 中断门和陷阱门仅仅有一比特的差别. 中断门和陷阱门描述符只允许存放在IDT内, 任务门可以位于GDT, LDT和IDT中.
和实模式下的中断向量表(IVT)不同, 保护模式下的IDT不要求必须位于内存的最低端. 事实上, 在处理器内部, 有一个48位的中断描述符表寄存器(Interrupt Descriptor Table Register:IDTR), 保存着中断描述符表在内存中的线性基地址和界限. 如下图所示, 和GDT一样, 因为整个系统中只需要一个IDT就够了, 所以, GDTR与IDTR不像LDTR和TR, 没有也不需要选择器部分.

这就意味着, IDT可以位于内存中的任何地方, 只要IDTR指向了它, 整个中断系统就可以正常工作. 为了利用高速缓存使处理器的工作性能最大化, 建议IDT的基地址是8字节对齐的(地址的数值能够被8整除). 处理器复位时, IDTR的基地址部分为0, 界限部分为0xffff. 16位的表界限值意味着IDT和GDT, LDT一样, 表的大小可以使64KB, 但是, 事实上, 因为处理器只能识别256种中断, 故通常只是用2KB, 其他空余的槽位应当将描述符的P位清0. 最后, 与GDT不同的是, IDT中的第一个描述符也是有效的.
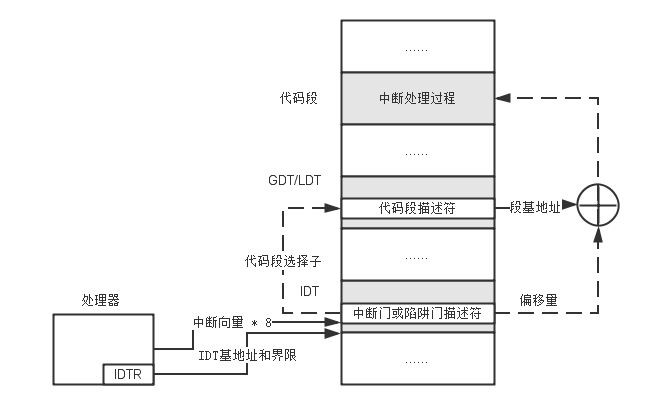
如上图所示, 在保护模式下, 当中断和异常发生时, 处理器用中断向量乘以8的结果去访问IDT, 从中取得对应的描述符. 因为IDT在内存中的位置是由IDTR指示的, 所以这很容易做到.
注意, 上图没有考虑分页, 也没有考虑门描述符是任务门的情况, 因为任务门的处理比较特殊. 中断门和陷阱门中有目标代码段描述符的选择子, 以及段内偏移量, 取决于选择子的TI位 , 处理器访问GDT或者LDT, 取出目标代码段的描述符. 接着, 从目标代码段的描述符中取得目标代码段所在的基地址, 再同门描述符中的偏移量相加, 就得到了中断处理程序的32位线性地址. 如果没有开启分页功能, 该线性地址就是物理地址; 否则, 送页部件转换成物理地址. 注意, 当处理器用中断向量访问IDT时, 要访问的位置超出了IDT的界限, 则产生常规保护异常(#GP).
中断和异常处理程序的保护
和通过调用门实施控制转移一样, 处理器要对中断和异常处理程序进行特权级保护. 当目标代码段描述符的特权级(可以用门描述符中的段选择子, 从GDT或LDT中找到)低于当前特权级CPL时, 即, 在数值上,
- CPL < 目标代码段的DPL
不过, 中断和异常处理程序的特权级保护也有一些特别之处. 具体表现在:
- 因为中断和异常的向量中没有RPL字段, 故当处理器进入中断或异常处理器, 或者通过任务门发起任务切换时, 不检查RPL.
- 中断门, 陷阱门也有自己的描述符特权级DPL, 即门的DPL. 但是, 通常情况下不针对该DPL进行检查, 除了用软中断int n和单步中断int3, 以及into引发的中断和异常. 在这种情况下, 当前特权级CPL必须高于, 或者和门的特权级DPL相同, 即, 在数值上
这主要是为了防止低段特技的软件通过软中断指令访问一些只为内核服务的例程, 如页故障处理. 相反地, 对于硬件中断和处理器检测到异常情况而引发的中断处理, 不检查门的DPL.
- CPL <= 门描述符的DPL
中断和异常是随机产生的, 不可预测的. 但是, 有一点可以确定的, 即, 它总是发生在某个任务内, 是在某个任务正在进行的时候产生的, 即使整个系统内只有一个任务. 当中断和异常发生时, 任务可能正在特权级0的全局空间(内核)中执行, 也可能正在特权级为3的局部空间执行. 因此, 当处理器将控制转移到中断或异常处理程序时, 如果处理程序运行在较高的特权级上(数值上较低的), 那么, 将转换栈:
- 根据处理程序的特权级别, 从当前任务的TSS中取得栈段选择子和栈指针. 处理器把旧栈的选择子和栈指针压入新栈. 毕竟, 中断处理程序也是当前任务的一部分.
- 处理器把EFLAGS, CS和EIP的当前状态压入新栈.
- 对于有错误代码的异常, 处理器还要把错误代码压入新栈, 紧挨在EIP之后, 如下图下面所示.
- 如果中断处理程序的特权级别和当前特权级别一致, 则不用转换栈.
- 处理器把EFLAGS, CS和EIP的当前状态压入当前栈.
- 对于有错误代码的异常, 处理器还要把错误代码压入当前栈, 紧挨在EIP之后, 如下图上面所示
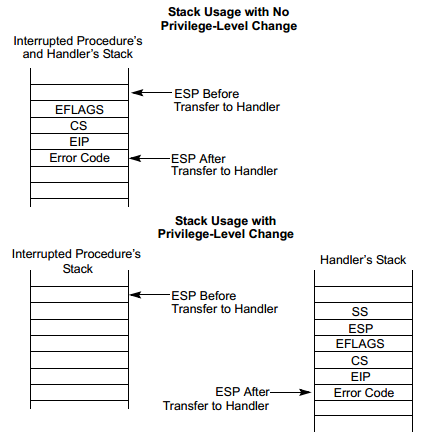
中断门和陷阱门区别不大, 通过中断门进入中断处理程序时, EFLAGS寄存器的IF位被处理器清零, 以禁止嵌套的中断, 当中断返回时, 将从栈中恢复EFLAGS寄存器的原始状态. 陷阱中断的优先级较低, 当通过陷阱门进入中断处理程序时, EFLAGS寄存器的IF位不变, 以允许其他中断优先处理.
EFLAGS寄存器的IF位仅影响硬件中断, 对NMI, 异常和int n形式的软件中断不起作用.
中断任务
当中断和异常发生时, 如果很具中断向量从IDT中找到的描述符是任务门, 则不是进行一般的中断处理过程, 而是发起任务切换. 如下图所示, 这是通过中断发起任务切换的原理.
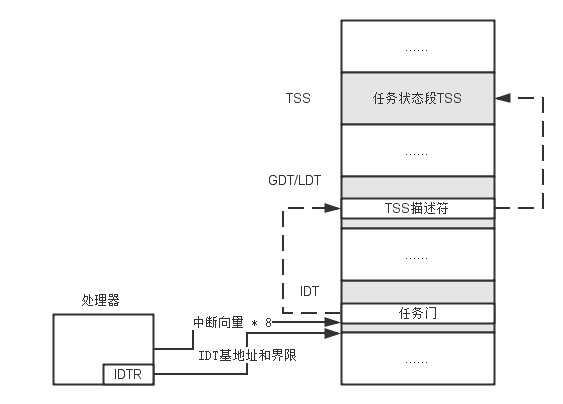
具体的说, 在中断中使用任务门可以获得以下好处:
- 被中断的那个程序或任务的整个执行环境可以被完整的保存起来(保存到它的TSS中).
- 由于接管控制的是一个新的任务, 因此, 可以使用要给全新的0特权级栈. 这可以有效地防止因当前任务的0特权级栈遭到破坏而使系统崩溃.
- 由于是切换到一个新任务, 因此, 它有一个独立的地址空间.
当然, 和一般的中断处理过程相比, 利用中断发起任务切换也有不利的一面, 那就是速度很慢, 笔记要保存大量的机器状态, 并进行一系列的特权级和内存访问的检查. 因中断和异常而发起任务切换时, 不再保存CS, EIP的状态, 但是, 在任务切换工作完成后, 处理器要把错误代码压入新任务的栈中(如果有错误代码的话).
任务是不可重入的, 因此, 在进行中断任务之后和执行iret指令之前, 必须关中断, 以防止因相同的中断再此发生而产生常规保护异常(#GP);
作为对任务门的保护, 和中断门, 陷阱门一样, 只对通过int3, int n和into指令发起的任务切换实施特权级检查, 即, 只有在数值上符合以下条件, 才允许通过以上指令发起任务切换:
- CPL <= 任务门的DPL
错误代码
有些异常产生时, 处理器会在异常处理程序或中断任务的栈中压入一个错误代码, 通常, 这意味着异常和特定的段选择子或中断向量有关.
如下图所示, 压入栈中的错误代码是32位的, 但高16位不用.

EXT位的意思是, 异常是由外部事件引发的. 此位置位时, 表示异常是由NMI, 硬件中断等引发的.
IDT位用于指示描述符的位置. 为1时, 表示段选择子的索引部分(错误代码的位15~3)是指向中断描述符表的; 为0时, 表示段选择子的索引部分指向GDT或者LDT.
TI位仅在IDT位是0的情况下才有意义. 此位是0时, 表示段选择子的索引部分指向GDT, 否则, 指向LDT.
段选择子的索引部分用于指示GDT/LDT内的段描述符, 或者IDT内的门描述符, 它就是我们平时所用的段选择子的高13位.
有时候, 错误代码可能是全零(空), 这表示异常的产生并非由于引用了一个特定的段. 当然, 也可能确实是在引用一个段时发生的, 而且由于那个段的描述符是空描述符.
注意, 当通过iret指令从中断处理程序返回时, 处理器并不会自动弹出错误代码. 因此, 对那些有异常代码的异常处理程序来说, 在执行iret之前必须先从栈中移去错误代码.
对于外部异常(通过处理器引脚触发), 以及用软中断指令int n引发的异常, 处理器不会压入错误代码, 即使它原本是一个有错误代码的异常.
8259A芯片初始化
一旦设置了中断描述符表, 并加载了IDTR寄存器(用lidt指令), 处理器的中断机制就开始起作用了. 但现在还不宜开放硬件中断. 在保护模式下, 如果计算机系统的可编程中断控制器芯片还是8259A, 那就得重新进行初始化, 事实上, 8259A并没有过时, 在单处理器系统中, 它依然健在. 重新初始化的原因是其主片的中断向量和处理器的异常向量冲突. 计算机启动之后, 主片的中断向量为0x08~0x0F, 从片的中断向量为0x70~0x77, 在以8086位处理器的系统中, 这没有什么问题, 在32位处理器上, 0x08~0x0f已经被处理器用做异常向量.
好在8259A(以及I/O APIC)都是可编程的, Intel公司建议, 中断向量0x20~0xff是用户可以自由分配的部分. 那么, 我们可以设置8259A的主片, 把它的中断向量改成0x20~0x27.
对8259A编程需要使用初始化命令字(Initialize Command Word: ICW), 以设置它的工作方式, 共有4个初始化命令字. 分别是ICW1~ICW4, 都是单字节命令.ICW1用于设置中断请求的触发方式, 以及级联的芯片数量; ICW2用于设置每个芯片的中断向量; ICW3用于指定用哪个引脚实现芯片的级联; ICW4用于控制芯片的工作方式.
主片的端口是0x20和0x21, 从片的端口是0xa0和0xa1, 要发送初始化命令字给8259A, 对于主片来说, 需要先向0x20端口发送ICW1, 而对于从片来说, 这个端口是0xa0. 这是一个标志, 每次8259A接到ICW1时, 都意味着一个新的初始化过程开始了.
从0x20/0xa0端口接受命令字ICW1后, 8259A期待从0x21/0xa1端口接受命令字ICW2, 但是, 它是否接受ICW3和ICW4, 还要看ICW1的内容. 如下图所示, ICW1的位0决定了是否有ICW4命令, 位1指示是否为多片级联. 如果是多片级联, 那么, 必定有ICW3命令. 这样一来, 8259A就知道, 在接受了ICW2之后, 是否还要在相同的端口(0x21/0xa1)上依次再接受ICW3和ICW4.
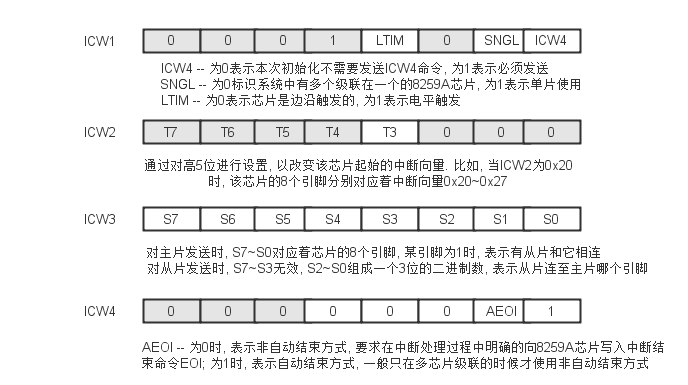
注意, 上图中, 深色的比特位表示它被保留, 或者不用, 使用途中所标注的固定值(0或1); 有些虽然不是深色, 但也标注了固定值(0或1),这些位是有意义的, 可以设置或改变, 具体含义可参考芯片手册.
转换后援缓冲期的刷新
开启也功能时, 处理器的页部件要把线性地址转换成物理地址, 而访问页目录表和页表是相当费时的. 因此, 把页表项预先存放到处理器中, 可以加考哪个地址转换速度. 为此, 处理器专门构造了一个特殊的高速缓存装置, 叫做转换后援缓冲器(Translation Lookaside Buffer:TLB). 事实上, 对该缓冲器的命名可谓五花八门, 从"转换旁路缓冲器", "转换后备缓冲区"到"快表"不一而足.
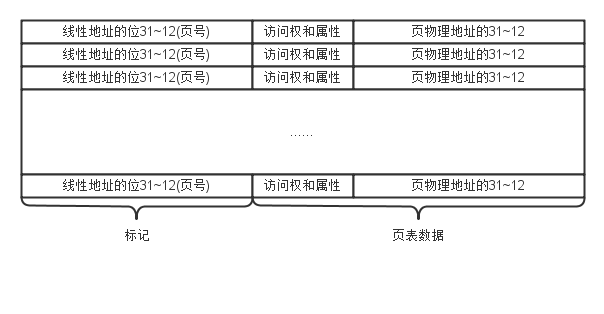
如上图所示, 这是TLB的结构, 它分为两大部分, 第一部分是标记, 其内容为线性地址的高20位; 第二部分是页表数据, 包括属性, 访问权和页物理地址的高20位. 在分页模式下, 当段部件发出一个线性地址时, 处理器用线性地址的高20位来查找TLB(用线性地址的高20位和TLB中的标记比对查找), 如果找到匹配项(命中), 则直接使用数据部分物理地址作为转换用的地址; 如果检索不成功(不中), 则处理器还得花时间访问内存中的页目录表和页表, 找到那个页表项, 然后将它填写到TLB中, 以备后用. TLB容量不大, 如果它装满了, 则必须淘汰掉那些用的较少的项目.
TLB中的属性位来自页表项, 比如D位等; 访问权来自页目录项和对应的页表项, 比如RW位和US位等. 问题是, 就RW位和US位来说, 页目录项和页表项都有着两位, 以哪一个为准呢? 在分页机制中, 对页的访问控制按最严格的访问权进行. 对于某个线性地址, 如果其页目录项的RW为0而其也表项的RW为1, 则按RW位是0执行. 也就是说, TLB中的访问权, 是页目录项和页表项中, 对应访问权的逻辑与.
处理器仅仅缓存那些P位是1的页表项, 而且, TLB的工作和CR3的PCD和PWT位无关, 不受这两位影响. 另外, 对于页表项的修改不会同时反映到TLB中, 是的, 这是很糟糕的, 如果内从中的页表项已经修改, 但TLB中对应的条目还没有更新, 那么, 转换后的物理地址必定是错误的.
可以将CR3寄存器的内容都出, 再原样写入, 这样就会是的TLB中的所有条目失效. 当然, 这是比较直接的办法. 当任务切换时, 因为要从新任务中的CR3寄存器域加载页目录项, 也会隐式得导致TLB中的所有条目无效. 注意, 上述方法对于那些标记为全局(G位 = 1)的页表项来说无效, 不起作用.
也可以用指令invlpg来刷新TLB中的单个条目. 当然, 要做到这一点, 必须指定一个线性地址, 处理器用给出的线性地址搜索TLB, 找到那个条目, 然后重新加载它. invlpg指令格式:
- invlpg m















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









