






基础智能体的进展与挑战综述
从类脑智能到具备可进化性、协作性和安全性的系统
【翻译团队】刘军(liujun@bupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪
- 将大语言模型(LLM)作为优化器
在本章中,我们介绍并讨论将大型语言模型(LLMs)概念化为优化器的已有研究。首先,我们注意到,大多数现有研究都集中在第(9.1)式中定义的提示优化问题上,因为优化具备智能体能力的工作流程中的其他组成部分仍是一个新兴的研究领域。接下来,我们将其与经典的迭代算法进行类比,并探讨它们在现代优化流程中的融合。
10.1 优化范式
传统的优化方法在目标函数可访问性的假设上存在差异。我们将其大致分为三类,每一类都在输入空间上呈现出更广泛的扩展:基于梯度的优化依赖于显式的函数梯度;零阶优化无需梯度信息;而基于LLM的优化则超越了数值函数,能够在结构化和高维输入空间上进行优化。
-
基于梯度的优化。这类方法假设可以获得梯度信息,并通过迭代不断优化参数。诸如随机梯度下降(SGD)和牛顿法[801]等技术被广泛使用,但它们要求函数可微,这限制了其在诸如提示调优和结构化决策工作流等离散问题中的适用性,而这类问题通常具有图结构。
-
零阶优化。这类方法无需显式梯度,而是通过函数值评估来估计搜索方向[802]。代表方法包括贝叶斯优化[803]、进化策略[804]和有限差分法[805],当梯度难以获取或计算成本高时,这些方法非常有效。然而,它们仍然依赖于明确定义的数值目标和结构化的搜索空间,这限制了它们在语言类任务中的应用。
-
基于LLM的优化。LLM通过将自然语言作为优化域和反馈机制,能够在更广泛的解空间中进行优化。借助结构化推理和类似人类的迭代能力,LLM在优化提示、生成自适应工作流以及基于用户反馈迭代提升任务表现方面表现出色。
尽管基于梯度和零阶的方法主要应用于数值目标,但它们的核心原理——如迭代精炼、搜索启发式和自适应学习——同样构成了LLM优化策略的基础。在这些原则的基础上,我们重点介绍一种快速发展的基于LLM的优化范式:强化学习。这一方法已成为“慢思考”推理模型的基础[90, 806, 89]。随着这些模型的持续演进,我们预计它们将推动下一波具备智能体能力的应用,使LLM在复杂环境中具备更强的适应性和战略远见。
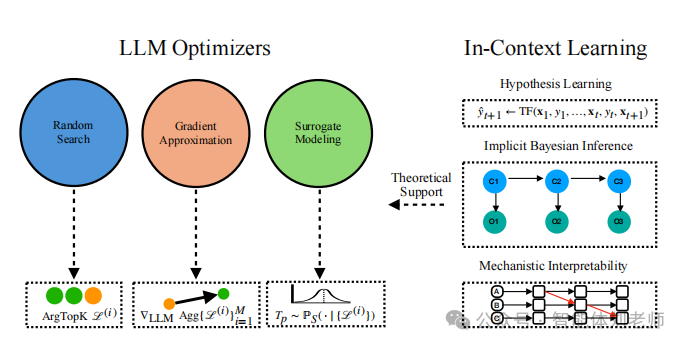
图 10.1:基于LLM的优化方法分类法,分为随机搜索、梯度近似和智能体建模三类。图中还强调了一些关于上下文学习的理论解释,包括假设学习、隐式贝叶斯推理和机制可解释性,这些理论构成了LLM优化能力的基础。
10.2 LLM优化的迭代方法
部分基于LLM的优化方法直接借鉴了经典优化理论,通过调整关键组件来应对离散且结构化的挑战。这些方法的一个核心特征是迭代更新步骤,在这一过程中,模型生成的修改方案从多个可能的改进中被选出,以优化目标。以第(9.1)式中的提示优化目标为贯穿示例,一个通用的迭代算法可以表述如下:
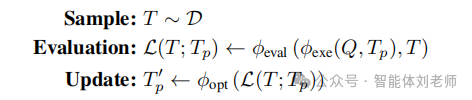
在这里,Sample和Update步骤是根据智能体任务定义的。在最简单的情形中,例如优化用于对电影评论进行二分类的指令,目标函数 L 是通过分类准确率来衡量的。在更复杂的具备智能体能力的工作流程中,决策变量可能包括工作流中不同阶段的提示、工具选择、智能体结构,或这些元素的组合。如第9章所讨论,这些决策变量的一个共同特征是它们具有组合性质——例如,来自LLM词汇表 的所有字符串集合,或工作流中所有可能的角色分配方式。由于枚举所有可能解在实践中往往是不可行的,因此这就要求设计近似的更新步骤 ,我们将在接下来的内容中讨论这一点。
-
随机搜索。早期的基于LLM的优化方法利用随机搜索的变体,在离散的自然语言空间中优化提示[774, 807, 651, 732, 808, 809, 810]。这些方法通常类似于进化算法,即在每一轮迭代中采样候选决策变量,并从中选择表现最优的个体。其一般形式如下:
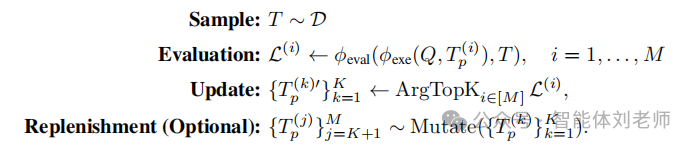
我们在此略微覆盖之前的符号,令表示每轮迭代中采样的候选提示总数,(其中 <)控制保留用于下一步的表现最优候选数量,这些候选是通过算法中的 ArgTopK 操作选出的。该算法还可选择性地引入补充步骤,以在多轮迭代中保持候选池的多样性。随机搜索方法实现简单、易于并行化,尤其适用于单提示工作流。此外,除了提示优化,它们在选择上下文内演示(in-context demonstrations)方面也表现出色[811, 812]。然而,这种方法的效率是有代价的——每轮迭代都需要进行 次并行API调用,对于涉及多个查询的复杂工作流来说,这种开销可能高得令人望而却步。
-
梯度近似。若干方法通过迭代地优化解来近似基于梯度的更新。例如,[779, 730, 728]在不同的工作流阶段生成改进版本;StraGO[722]使用中心差分启发式估计下降方向;而 Trace[813]通过将组合程序建模为计算图来进行优化,类似于反向传播。在连续优化中的梯度更新与提示空间中的精炼之间的关键类比是“下降方向”的概念——即对决策变量的系统性修改,以提升目标函数值。相比之下,随机搜索方法在每一步中独立提出新的决策变量,并不利用以往的更新轨迹。而基于梯度的方法则利用这些历史信息,通常能带来更快的收敛速度。梯度近似方法的一般迭代过程如下所示:
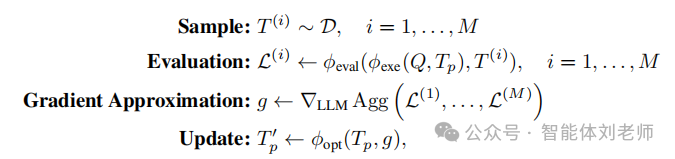
其中 M 表示小批量的大小,Agg(⋅) 是一种聚合函数用于整合反馈信号(例如,在数值优化中,Agg 通常是平均算子);∇LLM 表示一种抽象的 “LLM-梯度算子” [728],它基于反馈信号和当前的小批量生成文本形式的改进方向(例如:“智能体应考虑……的边界情况。此外 可以通过一次LLM查询来实例化,使智能体能够根据 g 更新其提示。与随机搜索方法相比,基于梯度的方法具有两个关键优势:一是它们允许将过去的优化方向融入融入融入 ,类似于一阶优化算法中的动量机制[814, 815];二是它们支持类似反向传播的技术,用于优化包含多个可优化模块的计算图[651, 813, 780],这使其在处理具有阶段依赖性的多阶段工作流中尤为有效。然而,这种灵活性也带来了设计上的额外开销,比如需要设计元提示(meta-prompts)来聚合反馈并应用优化方向。关于使用LLM来优化这些超参数的可行性,我们将在下文进一步讨论。此外,也有一些方法尝试直接对 soft prompt 进行梯度优化[816, 817, 818]。虽然这类方法在简单的输入输出序列学习任务中表现良好,但在多步骤工作流和顺序决策问题上则面临困难[630, 300]。最后,虽然上述方法已经充分利用了一阶优化的启发,但将二阶优化技术(如拟牛顿法)扩展到基于LLM的优化仍没有被足够探索。幸运的是,近期的研究如 Revolve[780]已朝这一方向迈出一步,其引入了一种结构化的二阶优化方法,通过建模多轮迭代中响应模式的演化过程来实现。借助更高阶的优化修正,Revolve能够实现更稳定、更有信息支撑的优化过程,有效缓解复杂任务中的停滞现象。我们也对在推理阶段利用计算资源[90, 89]来整合历史优化方向并研究动量机制带来的收益这一新趋势感到期待。
-
贝叶斯优化与智能体建模。尽管前述方法在基于LLM的优化方面取得了显著进展,但由于需要大量的LLM交互,它们通常会带来可观的经济和环境成本。此外,这些方法对噪声较为敏感,而离散提示等决策变量所对应的优化空间仍然理解有限[819, 820]。在这种约束条件下,贝叶斯优化(Bayesian Optimization, BO)成为一种具有吸引力的替代方案,它通过构建对噪声具有鲁棒性的优化目标智能体模型来实现优化:

其中,S 表示优化目标的概率智能体模型,配备了提议操作符(例如,高斯过程贝叶斯优化程序中的后验采样[803])以及基于提示评估结果更新模型的机制。例如,MIPRO[821]使用树结构帕尔森估计器(Tree-Structured Parzen Estimator)作为其智能体模型[822],而 PROMST[823]则训练一个评分预测模型来引导提示调优。利用智能体模型进行基于LLM的优化,与近年来针对不可微目标函数的“摊销优化”(amortized optimization)趋势相一致[824]。例如,[825]训练了一个提示生成型LLM,用以摊销在寻找越狱攻击前缀的 beam search 问题上的计算成本。
最后,还有一些研究在LLM输出的基础上拟合额外的轻量级模块,例如贝叶斯后验信念或效用函数,以辅助特定领域工作流的优化,例如决策制定和多智能体协商[826, 827]。这类摊销式方法——即拟合一个可参数化模型,使其能够在面对未见输入时重复使用——在基于LLM的优化中正得到越来越广泛的应用,例如在越狱攻击(jailbreaking)任务中[828, 825]。
10.3 优化超参数
与传统优化类似,基于LLM的方法对超参数非常敏感,这些超参数会显著影响搜索效率和泛化能力。在基于梯度的LLM优化器中,关键的设计选择之一是聚合函数 Agg(⋅) 的设定,它决定了如何综合文本反馈来指导提示更新。如果选择不当,可能会导致关键信息丢失或迭代优化过程中的方向偏差。此外,[813]引入了“白板”方法(whiteboard approach),将LLM程序分解为可供人类理解的模块。然而,关于如何结构化这类模块化工作流的设计选择,目前研究仍较匮乏,这为优化以LLM驱动的决策流程提出了一个开放性挑战。
LLM优化中的超参数往往与数值优化中的超参数存在对应关系。例如,批量大小在这两者中都起着关键作用:正如小批量更新在经典优化中提升了稳定性与效率,LLM方法如 TextGrad[728]也会在更新前聚合多个生成样本的反馈。另一个关键因素是动量机制——在基于梯度的方法中,动量通过引入过去的梯度来稳定更新;类似地,LLM优化器也会利用历史优化结果来持续提升性能[728, 813]。尽管数值优化在超参数选择上已有诸多进展,但LLM优化器的超参数设置目前仍主要依赖启发式方法,常常基于试错过程进行调整。
在具备智能体能力的系统设计中,超参数分布于多个组件,例如智能体的角色分配、上下文示例的选择、工具调用的调度等。每一个选择都会对下游任务的表现产生深远影响,但关于如何系统性优化这些配置的方法仍然尚不成熟。虽然传统的超参数调优技术,如网格搜索和贝叶斯优化,可以应用于基于LLM的离散工作流,但由于语言模型输出具有较高的方差,其计算成本往往不可接受。此外,这些超参数的组合特性——智能体配置、提示策略与推理结构之间复杂的交互关系——使得穷举搜索在实践中不可行。近期的研究试图通过将智能体工作流嵌入结构化框架来应对这一挑战,例如有限状态机[729]、最优决策理论[826]和博弈论[827]。然而,这些方法往往难以在多样化环境中实现泛化。应对这一挑战的一个有前景方向是元优化(meta-optimization),即利用LLM优化其自身的超参数和决策策略。例如,基于LLM的优化器可以通过将过去的决策视为经验,来迭代改进自身的提示策略,这与深度学习中学习型优化器(learned optimizers)的思路类似[829]。此外,摊销式方法通过训练辅助模型预测有效的超参数,从而降低穷举搜索的计算成本[821, 823]。尽管这些技术带来了令人兴奋的可能性,但也引入了新的挑战,例如在自适应调优中如何平衡探索与利用,以及如何确保方法在不同优化任务间的泛化能力。因此,探索适用于LLM工作流的系统化元优化策略,仍是未来研究的关键方向。
10.4 跨深度与时间的优化
与在静态环境中更新参数的传统优化器不同,LLMs 以动态方式优化工作流,考虑了“深度”(单次传递的工作流)与“时间”(递归更新)两个维度。在“深度”维度上,LLMs 的运作方式类似于前馈神经网络,按顺序在工作流的不同模块中进行优化——大多数现有的基于LLM的优化器都遵循这一范式。在执行单次传递之外,LLMs 也可以在“时间”维度上进行优化,其机制类似于递归神经网络(RNN)或通用Transformer(Universal Transformers)[830],通过多轮迭代不断改进决策过程。例如,StateFlow[729]通过跨多轮迭代整合反馈,增强了工作流的动态优化与自适应能力。这种方法使得优化不再局限于单步,而是可以逐步演化。尽管上述类比具有吸引力,但许多已经在工程实践中成熟的优化技术——如检查点机制(checkpointing)[831]和截断反向传播(truncated backpropagation)[832]——在基于LLM的优化中仍鲜有探索。我们认为,这些技术为未来研究提供了有前景的方向,这也呼应了先前研究者对深入探索此类机制的呼吁[813]。
10.5 理论视角
近期研究表明,Transformer 本质上执行类似于优化的计算,这一发现支持了其作为通用计算工作流优化器的潜力。然而,其经验上的成功与理论理解之间仍存在显著差距。以下是关于缩小这一差距的最新进展简要概述:
-
上下文学习(In-Context Learning):将Transformer视为优化器的一个基础视角来自上下文学习,尤其是在 few-shot 场景中[2]。[733]显示,Transformer 能够在上下文中学习多种回归假设,包括正则化线性模型、决策树和浅层神经网络。在此基础上,后续研究[734, 833, 735]提出了结构化的证明,说明Transformer可以实现迭代优化算法,如梯度下降和二阶更新方法。然而,尽管这些理论模型刻画了Transformer的优化能力,但它们尚未充分解释大规模LLM中的上下文学习行为,尤其是在离散输入输出空间中的操作。为此,实证分析[819, 834, 820]试图理解预训练LLM如何实现上下文泛化。[834]提出,上下文学习类似于一个隐马尔可夫模型(HMM)执行隐式贝叶斯推断,而[819, 820]则挑战了将上下文演示视为用于形成假设的测试样本这一传统观点。上下文学习仍是实现自我改进与优化的核心涌现能力[835],但它仍然难以被完整理论化。
-
机制可解释性(Mechanistic Interpretability):与理论分析并行,机制可解释性致力于通过识别Transformer中负责特定行为的子图(即回路 circuits)来揭示其内部计算过程。早期研究在预训练的 GPT-2 模型中映射了用于风格化语言任务的回路[836, 837, 838],而近期的研究进一步扩展,利用稀疏自动编码器识别具有语义意义的特征[839, 736, 840, 841]。这些方法在从先进的LLM中提取因果性和可控行为方面取得了显著成效,但也揭示了一项意外后果:上下文学习能力往往会在多轮示例条件下将有益的泛化与有害行为纠缠在一起[842],这对安全可靠地优化LLM工作流提出了新的挑战。
-
不确定性下的局限性:虽然LLM在有上下文信息支持的情况下展现出一定的顺序决策能力,但在不确定性环境下,它们往往难以做出最优决策[843, 844, 845, 846]。特别是,[826]发现基于LLM的优化器在应对随机性环境时适应能力较差,常常无法进行有效的探索。这些发现为在动态或不确定环境中部署LLM优化器敲响了警钟,尤其在探索性和鲁棒决策至关重要的场景下。
LLM 通过将结构化推理、自然语言处理和上下文学习相融合,重新定义了优化的内涵,拓展了其应用领域,超越了传统数值方法。尽管它们在结构化搜索空间中展现出强大的经验性能,但关于其理论基础仍存在诸多未解之谜,特别是在上下文学习能力如何通过标准梯度训练涌现方面,仍需深入研究。
【往期回顾】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









