







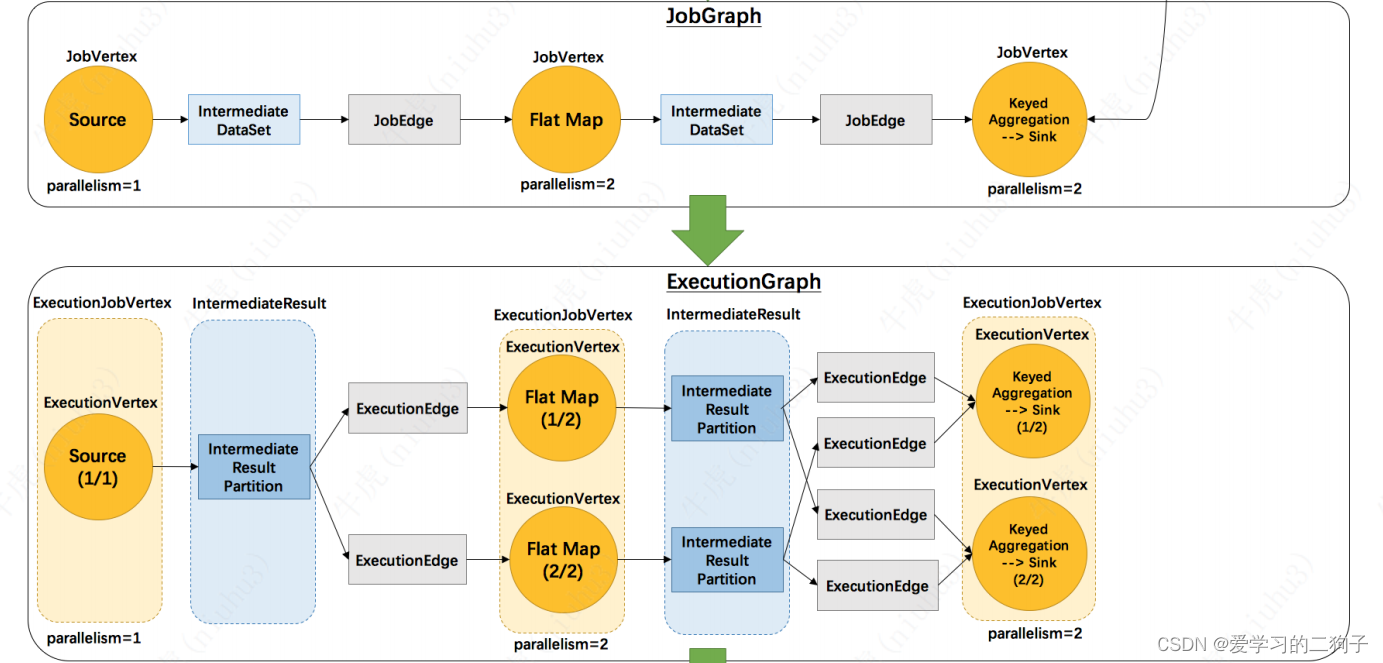
在JobGraph向ExecutionGraph转化的过程中,主要的工作内容为根据Operator的并行度来拆分JobVertex,每一个JobGraph中的JobVertex对应的ExecutionGraph中的一个ExecutionJobVertex,而每一个ExecutionJobVertex根据自身并行度会拆分成多个ExecutionVertex。同时会有一个IntermediateResultPartition对象来接收ExecutionVertex的输出。对于同一个ExecutionJobVertex中的多个ExecutionVertex的多个输出IntermediateResultPartition对象组成了一个IntermediateResult对象。但是在Flink1.13版本中,ExecutionGraph不再有ExecutionEdge的概念,取而代之的是ConsumedPartitionGroup和ConsumedVertexGroup.
1.createJobMasterService方法
上节我们看到了Jobmaster的创建和启动,其实jobmaster在启动以后会将jobgraph转换成executiongraph,jobmaster启动会首先进行leader的选举,这里我们进行跳过,后面在讲leader的选举。下来我们看一下 DefaultJobMasterServiceFactory#createJobMasterService方法
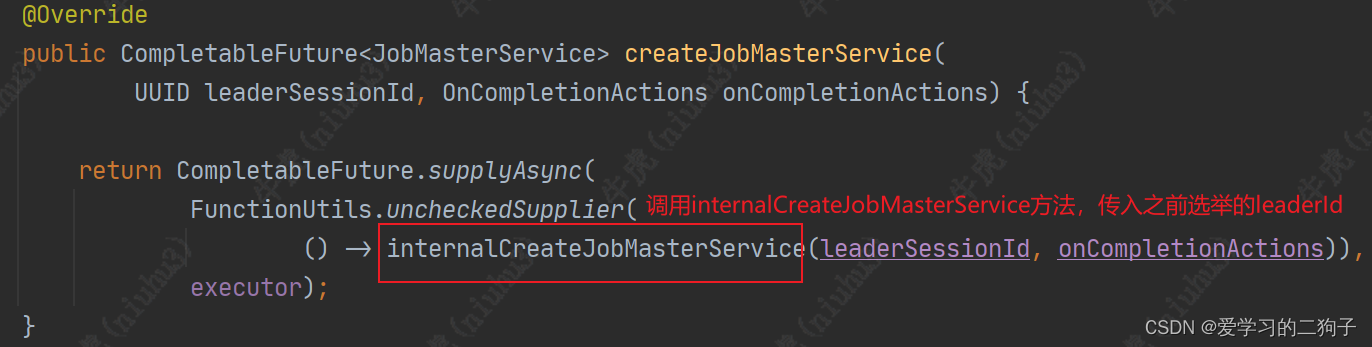
这里创建jobmaster的时候传入了我们之前上传到集群的jobgraph,创建完成后调用jobmaster的start方法启动jobmaster。
private JobMasterService internalCreateJobMasterService(
UUID leaderSessionId, OnCompletionActions onCompletionActions) throws Exception {
final JobMaster jobMaster =
new JobMaster(
rpcService,
JobMasterId.fromUuidOrNull(leaderSessionId),
jobMasterConfiguration,
ResourceID.generate(),
jobGraph,
haServices,
slotPoolServiceSchedulerFactory,
jobManagerSharedServices,
heartbeatServices,
jobManagerJobMetricGroupFactory,
onCompletionActions,
fatalErrorHandler,
userCodeClassloader,
shuffleMaster,
lookup ->
new JobMasterPartitionTrackerImpl(
jobGraph.getJobID(), shuffleMaster, lookup),
new DefaultExecutionDeploymentTracker(),
DefaultExecutionDeploymentReconciler::new,
initializationTimestamp);
jobMaster.start();
return jobMaster;
}这里我们看到jobgraph被当做参数传进了jobmaster的构造方法,这里我们直接点到jobmaster的构造方法中,jobmaster的构造方法中有一个schedulerNG这个类,这个类是flink的调度器。
调度器是 Flink 作业执行的核心组件,管理作业执行的所有相关过程,包括 JobGraph 到 ExecutionGraph 的转换、作业生命周期管理(作业的发布、取消、停止)、作业的 Task 生命周期管理(Task 的发布、取消、停止)、资源申请与释放、作业和 Task 的 Failover 等。
然后我们点进createScheduler这个方法中,这个方法里就调用了slotPoolServiceSchedulerFactory.createScheduler的方法
private SchedulerNG createScheduler(
SlotPoolServiceSchedulerFactory slotPoolServiceSchedulerFactory,
ExecutionDeploymentTracker executionDeploymentTracker,
JobManagerJobMetricGroup jobManagerJobMetricGroup,
JobStatusListener jobStatusListener)
throws Exception {
final SchedulerNG scheduler =
slotPoolServiceSchedulerFactory.createScheduler(
log,
jobGraph,
scheduledExecutorService,
jobMasterConfiguration.getConfiguration(),
slotPoolService,
scheduledExecutorService,
userCodeLoader,
highAvailabilityServices.getCheckpointRecoveryFactory(),
rpcTimeout,
blobWriter,
jobManagerJobMetricGroup,
jobMasterConfiguration.getSlotRequestTimeout(),
shuffleMaster,
partitionTracker,
executionDeploymentTracker,
initializationTimestamp,
getMainThreadExecutor(),
fatalErrorHandler,
jobStatusListener);
return scheduler;
}
从这个方法中我们可以看出slotPoolServiceSchedulerFactory.createScheduler又调用了schedulerNGFactory.createInstance方法
@Override
public SchedulerNG createScheduler(
Logger log,
JobGraph jobGraph,
ScheduledExecutorService scheduledExecutorService,
Configuration configuration,
SlotPoolService slotPoolService,
ScheduledExecutorService executorService,
ClassLoader userCodeLoader,
CheckpointRecoveryFactory checkpointRecoveryFactory,
Time rpcTimeout,
BlobWriter blobWriter,
JobManagerJobMetricGroup jobManagerJobMetricGroup,
Time slotRequestTimeout,
ShuffleMaster<?> shuffleMaster,
JobMasterPartitionTracker partitionTracker,
ExecutionDeploymentTracker executionDeploymentTracker,
long initializationTimestamp,
ComponentMainThreadExecutor mainThreadExecutor,
FatalErrorHandler fatalErrorHandler,
JobStatusListener jobStatusListener)
throws Exception {
return schedulerNGFactory.createInstance(
log,
jobGraph,
scheduledExecutorService,
configuration,
slotPoolService,
executorService,
userCodeLoader,
checkpointRecoveryFactory,
rpcTimeout,
blobWriter,
jobManagerJobMetricGroup,
slotRequestTimeout,
shuffleMaster,
partitionTracker,
executionDeploymentTracker,
initializationTimestamp,
mainThreadExecutor,
fatalErrorHandler,
jobStatusListener);
}这个方法有两个子类,这里我们选择DefaultSchedulerFactory这个类的createInstance方法
@Override
public SchedulerNG createInstance(
final Logger log,
final JobGraph jobGraph,
final Executor ioExecutor,
final Configuration jobMasterConfiguration,
final SlotPoolService slotPoolService,
final ScheduledExecutorService futureExecutor,
final ClassLoader userCodeLoader,
final CheckpointRecoveryFactory checkpointRecoveryFactory,
final Time rpcTimeout,
final BlobWriter blobWriter,
final JobManagerJobMetricGroup jobManagerJobMetricGroup,
final Time slotRequestTimeout,
final ShuffleMaster<?> shuffleMaster,
final JobMasterPartitionTracker partitionTracker,
final ExecutionDeploymentTracker executionDeploymentTracker,
long initializationTimestamp,
final ComponentMainThreadExecutor mainThreadExecutor,
final FatalErrorHandler fatalErrorHandler,
final JobStatusListener jobStatusListener)
throws Exception {
final SlotPool slotPool =
slotPoolService
.castInto(SlotPool.class)
.orElseThrow(
() ->
new IllegalStateException(
"The DefaultScheduler requires a SlotPool."));
final DefaultSchedulerComponents schedulerComponents =
createSchedulerComponents(
jobGraph.getJobType(),
jobGraph.isApproximateLocalRecoveryEnabled(),
jobMasterConfiguration,
slotPool,
slotRequestTimeout);
final RestartBackoffTimeStrategy restartBackoffTimeStrategy =
RestartBackoffTimeStrategyFactoryLoader.createRestartBackoffTimeStrategyFactory(
jobGraph.getSerializedExecutionConfig()
.deserializeValue(userCodeLoader)
.getRestartStrategy(),
jobMasterConfiguration,
jobGraph.isCheckpointingEnabled())
.create();
log.info(
"Using restart back off time strategy {} for {} ({}).",
restartBackoffTimeStrategy,
jobGraph.getName(),
jobGraph.getJobID());
final ExecutionGraphFactory executionGraphFactory =
new DefaultExecutionGraphFactory(
jobMasterConfiguration,
userCodeLoader,
executionDeploymentTracker,
futureExecutor,
ioExecutor,
rpcTimeout,
jobManagerJobMetricGroup,
blobWriter,
shuffleMaster,
partitionTracker);
return new DefaultScheduler(
log,
jobGraph,
ioExecutor,
jobMasterConfiguration,
schedulerComponents.getStartUpAction(),
new ScheduledExecutorServiceAdapter(futureExecutor),
userCodeLoader,
checkpointRecoveryFactory,
jobManagerJobMetricGroup,
schedulerComponents.getSchedulingStrategyFactory(),
FailoverStrategyFactoryLoader.loadFailoverStrategyFactory(jobMasterConfiguration),
restartBackoffTimeStrategy,
new DefaultExecutionVertexOperations(),
new ExecutionVertexVersioner(),
schedulerComponents.getAllocatorFactory(),
initializationTimestamp,
mainThreadExecutor,
jobStatusListener,
executionGraphFactory);
}
这个方法很长,他有很多成员变量,比如有负责管理slot的slotpool,excutionGraphFactory见名知意,是负责建造executionGraph的,在这里我们看到jobgrap最终又传到了DefaultScheduler的成员变量中,下面我们进入DefaultScheduler的构造方法中看一看
DefaultScheduler(
final Logger log,
final JobGraph jobGraph,
final Executor ioExecutor,
final Configuration jobMasterConfiguration,
final Consumer<ComponentMainThreadExecutor> startUpAction,
final ScheduledExecutor delayExecutor,
final ClassLoader userCodeLoader,
final CheckpointRecoveryFactory checkpointRecoveryFactory,
final JobManagerJobMetricGroup jobManagerJobMetricGroup,
final SchedulingStrategyFactory schedulingStrategyFactory,
final FailoverStrategy.Factory failoverStrategyFactory,
final RestartBackoffTimeStrategy restartBackoffTimeStrategy,
final ExecutionVertexOperations executionVertexOperations,
final ExecutionVertexVersioner executionVertexVersioner,
final ExecutionSlotAllocatorFactory executionSlotAllocatorFactory,
long initializationTimestamp,
final ComponentMainThreadExecutor mainThreadExecutor,
final JobStatusListener jobStatusListener,
final ExecutionGraphFactory executionGraphFactory)
throws Exception {
super(
log,
jobGraph,
ioExecutor,
jobMasterConfiguration,
userCodeLoader,
checkpointRecoveryFactory,
jobManagerJobMetricGroup,
executionVertexVersioner,
initializationTimestamp,
mainThreadExecutor,
jobStatusListener,
executionGraphFactory);
this.log = log;
this.delayExecutor = checkNotNull(delayExecutor);
this.userCodeLoader = checkNotNull(userCodeLoader);
this.executionVertexOperations = checkNotNull(executionVertexOperations);
final FailoverStrategy failoverStrategy =
failoverStrategyFactory.create(
getSchedulingTopology(), getResultPartitionAvailabilityChecker());
log.info(
"Using failover strategy {} for {} ({}).",
failoverStrategy,
jobGraph.getName(),
jobGraph.getJobID());
this.executionFailureHandler =
new ExecutionFailureHandler(
getSchedulingTopology(), failoverStrategy, restartBackoffTimeStrategy);
this.schedulingStrategy =
schedulingStrategyFactory.createInstance(this, getSchedulingTopology());
this.executionSlotAllocator =
checkNotNull(executionSlotAllocatorFactory)
.createInstance(new DefaultExecutionSlotAllocationContext());
this.verticesWaitingForRestart = new HashSet<>();
startUpAction.accept(mainThreadExecutor);
}
在这个构造方法中jobgraph又被传给了他的父类构造方法,最终我们进入到了schedulerBase的构造方法中
public SchedulerBase(
final Logger log,
final JobGraph jobGraph,
final Executor ioExecutor,
final Configuration jobMasterConfiguration,
final ClassLoader userCodeLoader,
final CheckpointRecoveryFactory checkpointRecoveryFactory,
final JobManagerJobMetricGroup jobManagerJobMetricGroup,
final ExecutionVertexVersioner executionVertexVersioner,
long initializationTimestamp,
final ComponentMainThreadExecutor mainThreadExecutor,
final JobStatusListener jobStatusListener,
final ExecutionGraphFactory executionGraphFactory)
throws Exception {
this.log = checkNotNull(log);
this.jobGraph = checkNotNull(jobGraph);
this.executionGraphFactory = executionGraphFactory;
this.jobManagerJobMetricGroup = checkNotNull(jobManagerJobMetricGroup);
this.executionVertexVersioner = checkNotNull(executionVertexVersioner);
this.mainThreadExecutor = mainThreadExecutor;
this.checkpointsCleaner = new CheckpointsCleaner();
this.completedCheckpointStore =
SchedulerUtils.createCompletedCheckpointStoreIfCheckpointingIsEnabled(
jobGraph,
jobMasterConfiguration,
userCodeLoader,
checkNotNull(checkpointRecoveryFactory),
log);
this.checkpointIdCounter =
SchedulerUtils.createCheckpointIDCounterIfCheckpointingIsEnabled(
jobGraph, checkNotNull(checkpointRecoveryFactory));
//在这里构造executiongraph
this.executionGraph =
createAndRestoreExecutionGraph(
completedCheckpointStore,
checkpointsCleaner,
checkpointIdCounter,
initializationTimestamp,
mainThreadExecutor,
jobStatusListener);
registerShutDownCheckpointServicesOnExecutionGraphTermination(executionGraph);
this.schedulingTopology = executionGraph.getSchedulingTopology();
stateLocationRetriever =
executionVertexId ->
getExecutionVertex(executionVertexId).getPreferredLocationBasedOnState();
inputsLocationsRetriever =
new ExecutionGraphToInputsLocationsRetrieverAdapter(executionGraph);
this.kvStateHandler = new KvStateHandler(executionGraph);
this.executionGraphHandler =
new ExecutionGraphHandler(executionGraph, log, ioExecutor, this.mainThreadExecutor);
this.operatorCoordinatorHandler =
new DefaultOperatorCoordinatorHandler(executionGraph, this::handleGlobalFailure);
operatorCoordinatorHandler.initializeOperatorCoordinators(this.mainThreadExecutor);
this.exceptionHistory =
new BoundedFIFOQueue<>(
jobMasterConfiguration.getInteger(WebOptions.MAX_EXCEPTION_HISTORY_SIZE));
}在这里我们就会看到我们最想看到的东西,createAndRestoreExecutionGraph方法,从这个方法名我们不难猜出他的主要功能就是创建和存储executionGraph
2.createAndRestoreExecutionGraph
Schedulerase这个方法里主要做了两件事:
1.利用工厂模式创建ExecutionGraph
2.设置executionGraph的作业状态监听器和作业失败监听器,并开启主线程
private ExecutionGraph createAndRestoreExecutionGraph(
CompletedCheckpointStore completedCheckpointStore,
CheckpointsCleaner checkpointsCleaner,
CheckpointIDCounter checkpointIdCounter,
long initializationTimestamp,
ComponentMainThreadExecutor mainThreadExecutor,
JobStatusListener jobStatusListener)
throws Exception {
//利用工厂模式创建executionGraph
final ExecutionGraph newExecutionGraph =
executionGraphFactory.createAndRestoreExecutionGraph(
jobGraph,
completedCheckpointStore,
checkpointsCleaner,
checkpointIdCounter,
TaskDeploymentDescriptorFactory.PartitionLocationConstraint.fromJobType(
jobGraph.getJobType()),
initializationTimestamp,
new DefaultVertexAttemptNumberStore(),
computeVertexParallelismStore(jobGraph),
log);
//设置executionGraph的作业状态监听器和作业失败监听器,并开启主线程
newExecutionGraph.setInternalTaskFailuresListener(
new UpdateSchedulerNgOnInternalFailuresListener(this));
newExecutionGraph.registerJobStatusListener(jobStatusListener);
newExecutionGraph.start(mainThreadExecutor);
return newExecutionGraph;
}3.createAndRestoreExecutionGraph
DefaultExecutionGraphFactory 的这个方法中主要做了三件事:
1.创建各种作业部署的监听器
2.利用建造者模式创建executionGraph
3.创建检查点协调器
@Override
public ExecutionGraph createAndRestoreExecutionGraph(
JobGraph jobGraph,
CompletedCheckpointStore completedCheckpointStore,
CheckpointsCleaner checkpointsCleaner,
CheckpointIDCounter checkpointIdCounter,
TaskDeploymentDescriptorFactory.PartitionLocationConstraint partitionLocationConstraint,
long initializationTimestamp,
VertexAttemptNumberStore vertexAttemptNumberStore,
VertexParallelismStore vertexParallelismStore,
Logger log)
throws Exception {
//创建作业部署的各种监听器
ExecutionDeploymentListener executionDeploymentListener =
new ExecutionDeploymentTrackerDeploymentListenerAdapter(executionDeploymentTracker);
ExecutionStateUpdateListener executionStateUpdateListener =
(execution, newState) -> {
if (newState.isTerminal()) {
executionDeploymentTracker.stopTrackingDeploymentOf(execution);
}
};
//利用建造者模式创建executionGraph
final ExecutionGraph newExecutionGraph =
DefaultExecutionGraphBuilder.buildGraph(
jobGraph,
configuration,
futureExecutor,
ioExecutor,
userCodeClassLoader,
completedCheckpointStore,
checkpointsCleaner,
checkpointIdCounter,
rpcTimeout,
jobManagerJobMetricGroup,
blobWriter,
log,
shuffleMaster,
jobMasterPartitionTracker,
partitionLocationConstraint,
executionDeploymentListener,
executionStateUpdateListener,
initializationTimestamp,
vertexAttemptNumberStore,
vertexParallelismStore);
//创建检查点协调器
final CheckpointCoordinator checkpointCoordinator =
newExecutionGraph.getCheckpointCoordinator();
if (checkpointCoordinator != null) {
// check whether we find a valid checkpoint
if (!checkpointCoordinator.restoreInitialCheckpointIfPresent(
new HashSet<>(newExecutionGraph.getAllVertices().values()))) {
// check whether we can restore from a savepoint
tryRestoreExecutionGraphFromSavepoint(
newExecutionGraph, jobGraph.getSavepointRestoreSettings());
}
}
return newExecutionGraph;
}4.buildGraph
这个方法非常长,所以我们只关注重点和executiongraph相关的东西,这里主要做了以下几件事:
1.创建executiongraph
2.循环遍历jobgraph的顶点,并对每个顶点进行拓扑排序
3.将拓扑排序后的结果添加到executiongraph中
public static ExecutionGraph buildGraph(
@Nullable ExecutionGraph prior,
JobGraph jobGraph,
Configuration jobManagerConfig,
Executor futureExecutor,
Executor ioExecutor,
ClassLoader classLoader,
CheckpointRecoveryFactory recoveryFactory,
Time timeout,
RestartStrategy restartStrategy,
MetricGroup metrics,
int parallelismForAutoMax,
Logger log)
throws JobExecutionException, JobException
{
checkNotNull(jobGraph, "job graph cannot be null");
final String jobName = jobGraph.getName();
final JobID jobId = jobGraph.getJobID();
// create a new execution graph, if none exists so far
final ExecutionGraph executionGraph;
//创建executiongraph
try {
executionGraph = (prior != null) ? prior :
new ExecutionGraph(
futureExecutor,
ioExecutor,
jobId,
jobName,
jobGraph.getJobConfiguration(),
jobGraph.getSerializedExecutionConfig(),
timeout,
restartStrategy,
jobGraph.getUserJarBlobKeys(),
jobGraph.getClasspaths(),
classLoader,
metrics);
} catch (IOException e) {
throw new JobException("Could not create the execution graph.", e);
}
// set the basic properties
executionGraph.setScheduleMode(jobGraph.getScheduleMode());
executionGraph.setQueuedSchedulingAllowed(jobGraph.getAllowQueuedScheduling());
try {
executionGraph.setJsonPlan(JsonPlanGenerator.generatePlan(jobGraph));
}
catch (Throwable t) {
log.warn("Cannot create JSON plan for job", t);
// give the graph an empty plan
executionGraph.setJsonPlan("{}");
}
// initialize the vertices that have a master initialization hook
// file output formats create directories here, input formats create splits
final long initMasterStart = System.nanoTime();
log.info("Running initialization on master for job {} ({}).", jobName, jobId);
//循环遍历jobgraph中的顶点
for (JobVertex vertex : jobGraph.getVertices()) {
String executableClass = vertex.getInvokableClassName();
if (executableClass == null || executableClass.isEmpty()) {
throw new JobSubmissionException(jobId,
"The vertex " + vertex.getID() + " (" + vertex.getName() + ") has no invokable class.");
}
if (vertex.getParallelism() == ExecutionConfig.PARALLELISM_AUTO_MAX) {
vertex.setParallelism(parallelismForAutoMax);
}
try {
vertex.initializeOnMaster(classLoader);
}
catch (Throwable t) {
throw new JobExecutionException(jobId,
"Cannot initialize task '" + vertex.getName() + "': " + t.getMessage(), t);
}
}
log.info("Successfully ran initialization on master in {} ms.",
(System.nanoTime() - initMasterStart) / 1_000_000);
//对jobgraph中的顶点进行拓扑排序
// topologically sort the job vertices and attach the graph to the existing one
List<JobVertex> sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();
if (log.isDebugEnabled()) {
log.debug("Adding {} vertices from job graph {} ({}).", sortedTopology.size(), jobName, jobId);
}
//将排序后的拓扑结果添加到executiongraph
executionGraph.attachJobGraph(sortedTopology);
if (log.isDebugEnabled()) {
log.debug("Successfully created execution graph from job graph {} ({}).", jobName, jobId);
}
// configure the state checkpointing
JobSnapshottingSettings snapshotSettings = jobGraph.getSnapshotSettings();
if (snapshotSettings != null) {
List<ExecutionJobVertex> triggerVertices =
idToVertex(snapshotSettings.getVerticesToTrigger(), executionGraph);
List<ExecutionJobVertex> ackVertices =
idToVertex(snapshotSettings.getVerticesToAcknowledge(), executionGraph);
List<ExecutionJobVertex> confirmVertices =
idToVertex(snapshotSettings.getVerticesToConfirm(), executionGraph);
CompletedCheckpointStore completedCheckpoints;
CheckpointIDCounter checkpointIdCounter;
try {
completedCheckpoints = recoveryFactory.createCheckpointStore(jobId, classLoader);
checkpointIdCounter = recoveryFactory.createCheckpointIDCounter(jobId);
}
catch (Exception e) {
throw new JobExecutionException(jobId, "Failed to initialize high-availability checkpoint handler", e);
}
// Maximum number of remembered checkpoints
int historySize = jobManagerConfig.getInteger(
ConfigConstants.JOB_MANAGER_WEB_CHECKPOINTS_HISTORY_SIZE,
ConfigConstants.DEFAULT_JOB_MANAGER_WEB_CHECKPOINTS_HISTORY_SIZE);
CheckpointStatsTracker checkpointStatsTracker = new CheckpointStatsTracker(
historySize,
ackVertices,
snapshotSettings,
metrics);
// The default directory for externalized checkpoints
String externalizedCheckpointsDir = jobManagerConfig.getString(
ConfigConstants.CHECKPOINTS_DIRECTORY_KEY, null);
executionGraph.enableSnapshotCheckpointing(
snapshotSettings.getCheckpointInterval(),
snapshotSettings.getCheckpointTimeout(),
snapshotSettings.getMinPauseBetweenCheckpoints(),
snapshotSettings.getMaxConcurrentCheckpoints(),
snapshotSettings.getExternalizedCheckpointSettings(),
triggerVertices,
ackVertices,
confirmVertices,
checkpointIdCounter,
completedCheckpoints,
externalizedCheckpointsDir,
checkpointStatsTracker);
}
return executionGraph;
}5.attachJobGraph
这个方法里主要做了以下几件事:
1.循环遍历jobvertex
2.创建executionJobVertex,并将intermidateResult与之链接(在这里会创建jobedge)
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException {
if (LOG.isDebugEnabled()) {
LOG.debug(String.format("Attaching %d topologically sorted vertices to existing job graph with %d "
+ "vertices and %d intermediate results.", topologiallySorted.size(), tasks.size(), intermediateResults.size()));
}
final long createTimestamp = System.currentTimeMillis();
//循环遍历jobvertex
for (JobVertex jobVertex : topologiallySorted) {
if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) {
this.isStoppable = false;
}
// create the execution job vertex and attach it to the graph
//创建executionjobvertex,将intermediateResults与之链接
ExecutionJobVertex ejv =
new ExecutionJobVertex(this, jobVertex, 1, timeout, createTimestamp);
ejv.connectToPredecessors(this.intermediateResults);
ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);
if (previousTask != null) {
throw new JobException(String.format("Encountered two job vertices with ID %s : previous=[%s] / new=[%s]",
jobVertex.getID(), ejv, previousTask));
}
for (IntermediateResult res : ejv.getProducedDataSets()) {
IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);
if (previousDataSet != null) {
throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",
res.getId(), res, previousDataSet));
}
}
this.verticesInCreationOrder.add(ejv);
}
}














 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









