







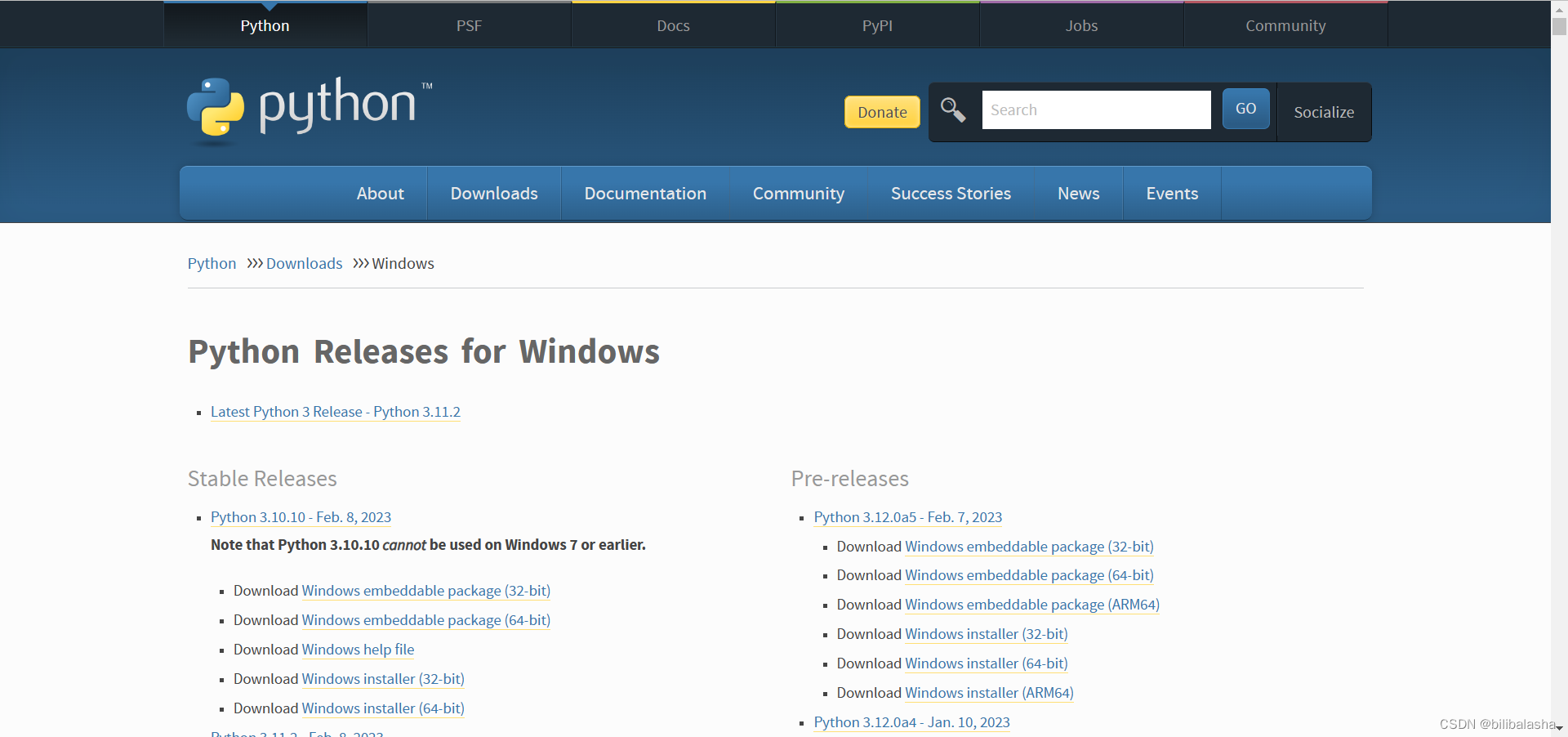
1、下载
官方连接:https://www.python.org/downloads/windows/
本文以【python-3.7.9-amd64.exe】为例。
2、安装
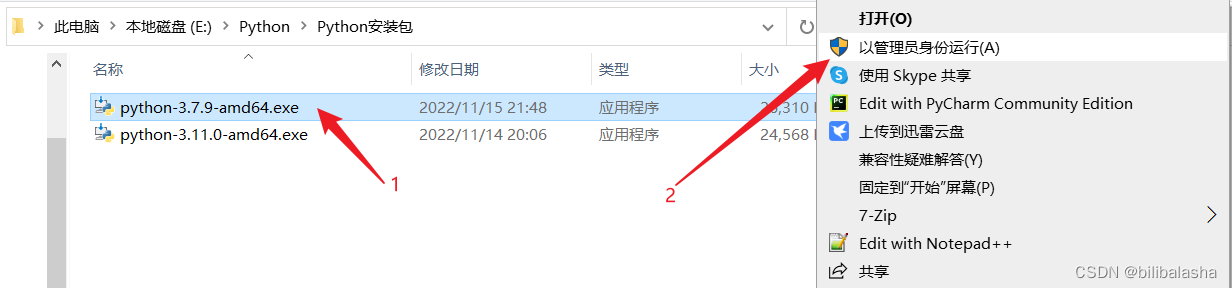
(1)右击安装包,以管理员身份运行。
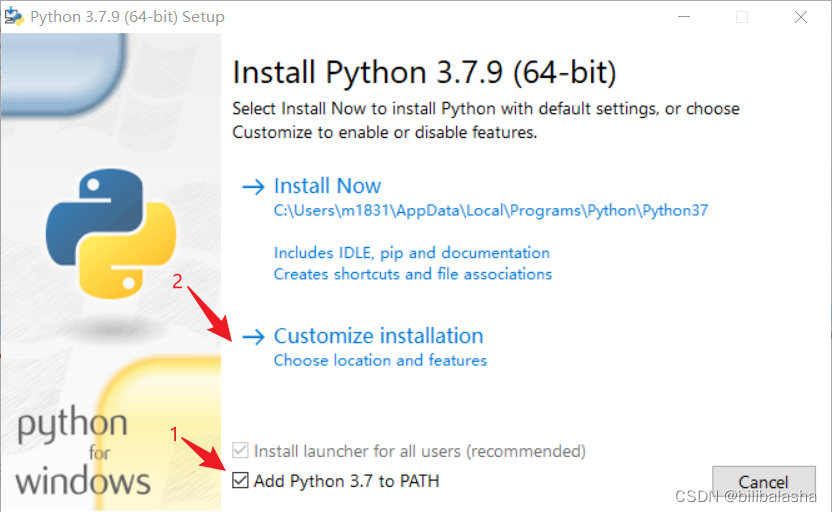
(2)勾选Add Python 3.7 to PATH,表示添加python的安装路径到环境变量的PATH系统变量。
然后选择自定义安装(作者习惯)。
(3)默认选择,点击下一步。
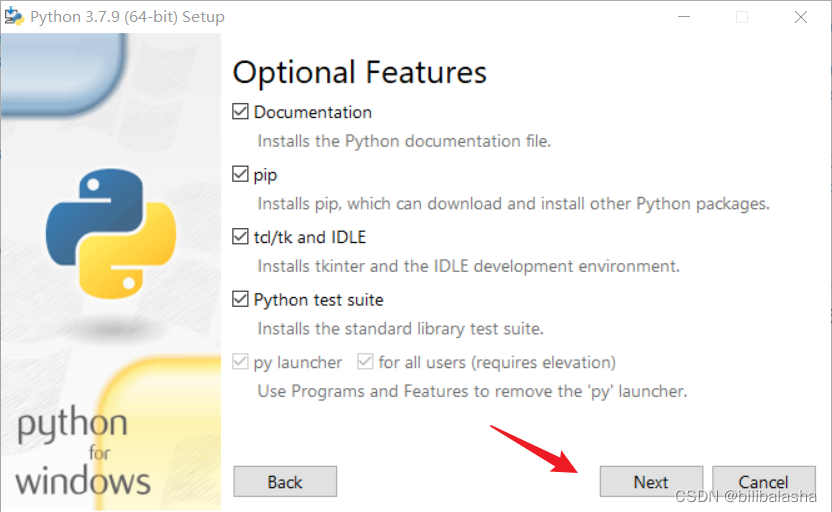
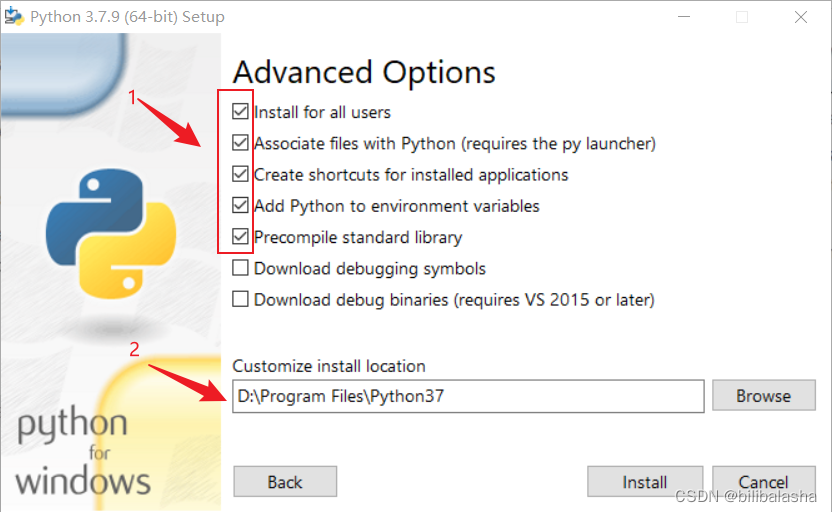
(4)勾选前面5项,然后选择你的自定义安装路径,最后点击安装。
(5)安装完毕!点击关闭。
(6)使用控制台查看当前安装使用的Python版本。输入python,出现图二结果证明安装成功!

3、配置环境变量
(1)系统变量:PATH,在安装的时候只要勾选了Add Python 3.7 to PATH,就会自动配置上。
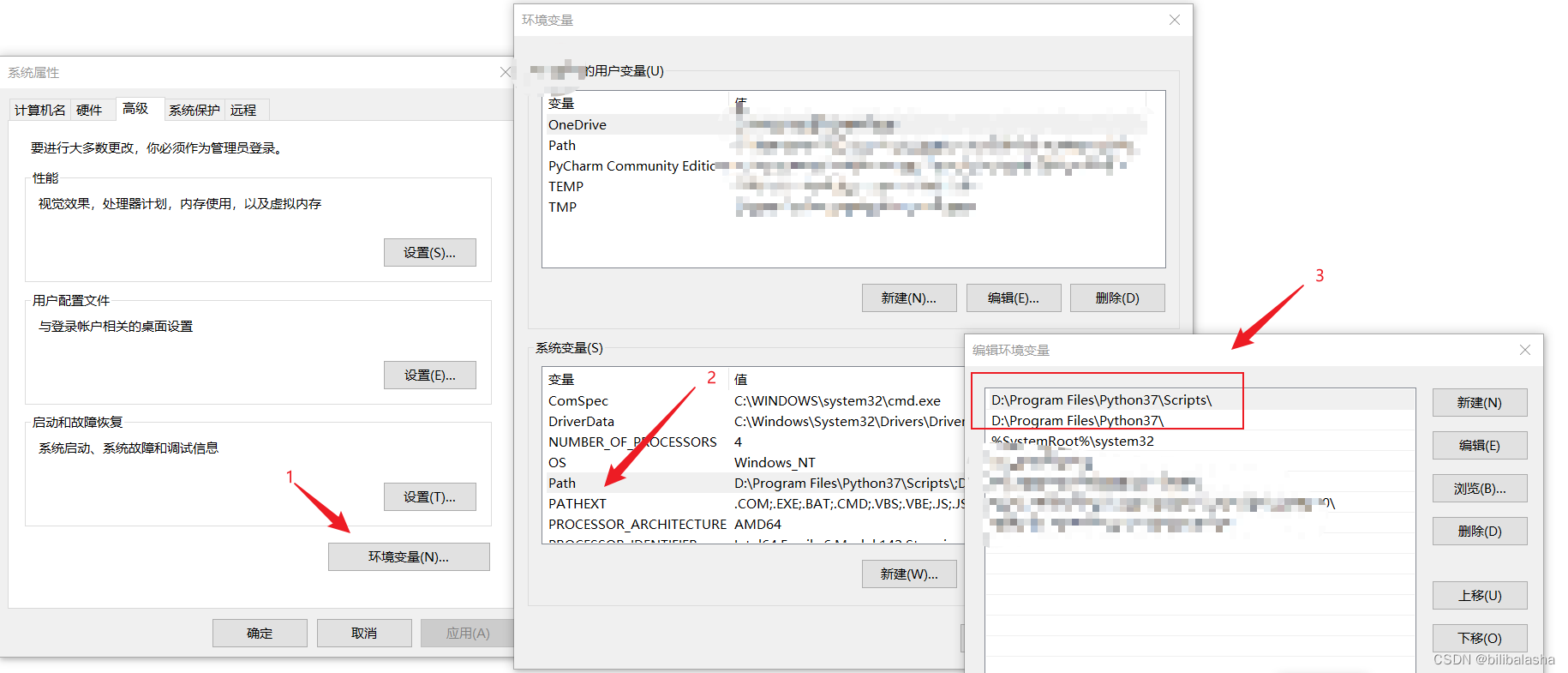
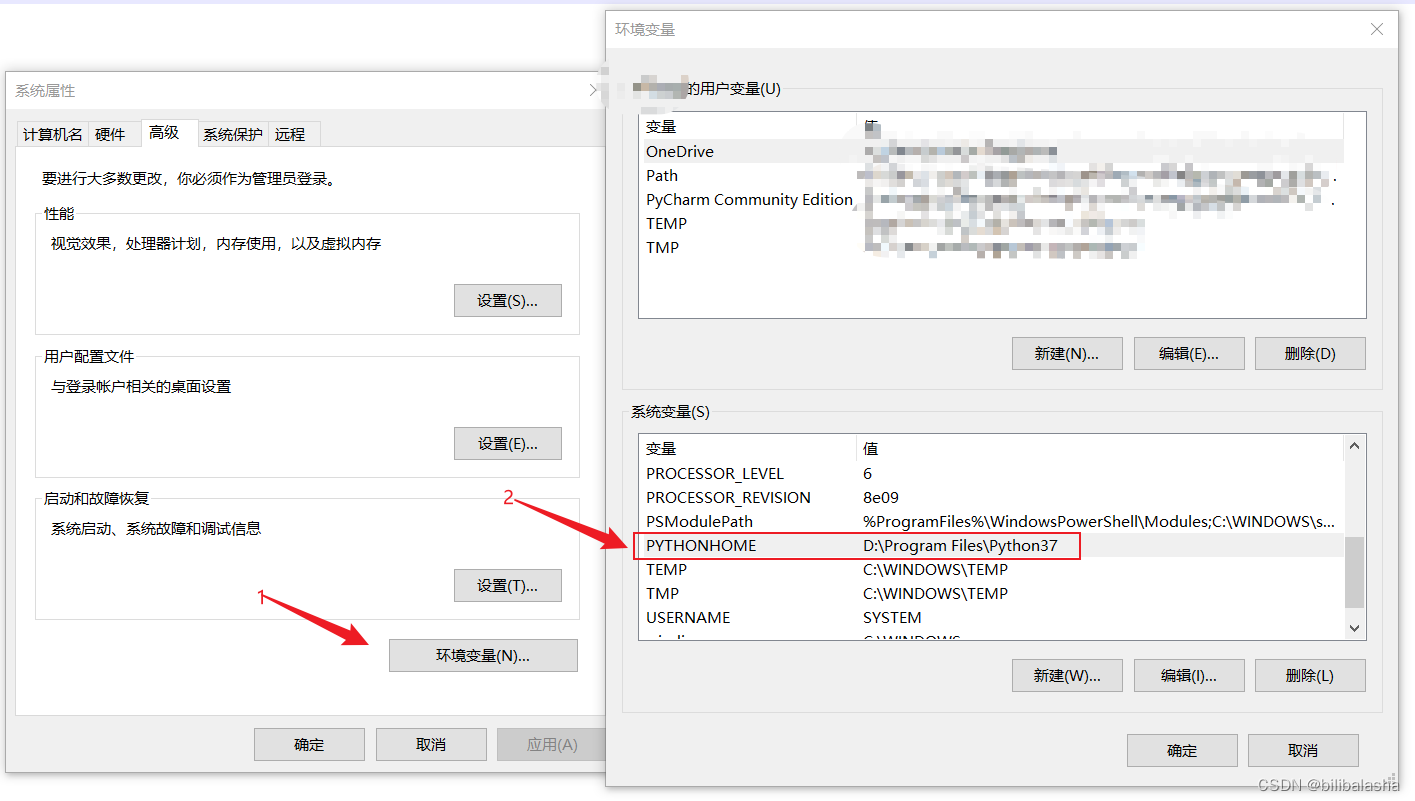
(2)系统变量:PYTHONHOME,配置的python的安装目录,该变量在使用到Apache服务的时候会用到,可以也配置上。
4、其他问题 - - - 修改第三方库的默认下载路径
(1)第三方库的默认下载路径是在系统盘的。
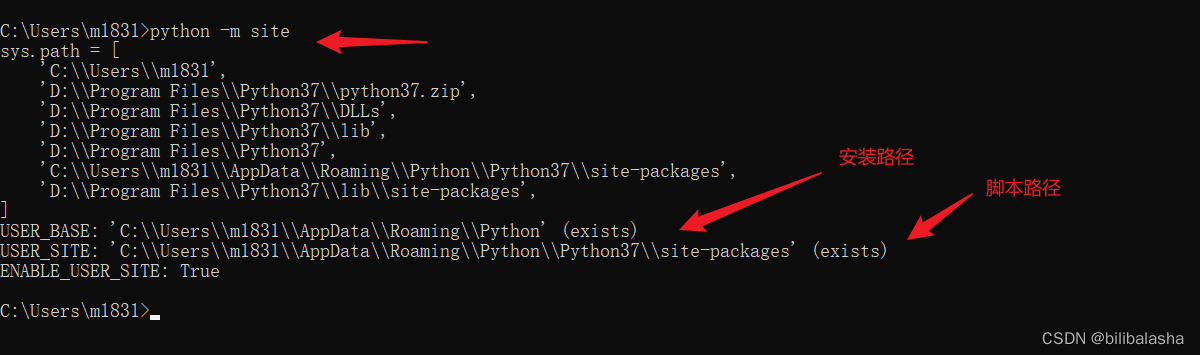
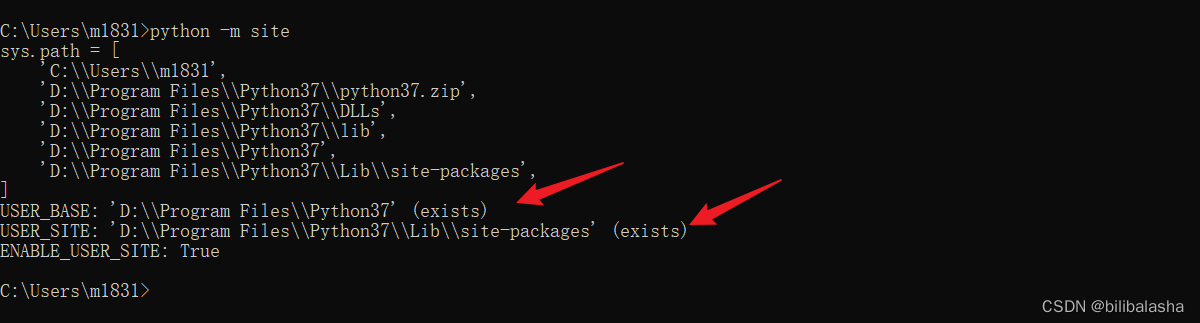
查看第三方库的默认下载路径【python -m site】,如果需要修改,请继续往下看。
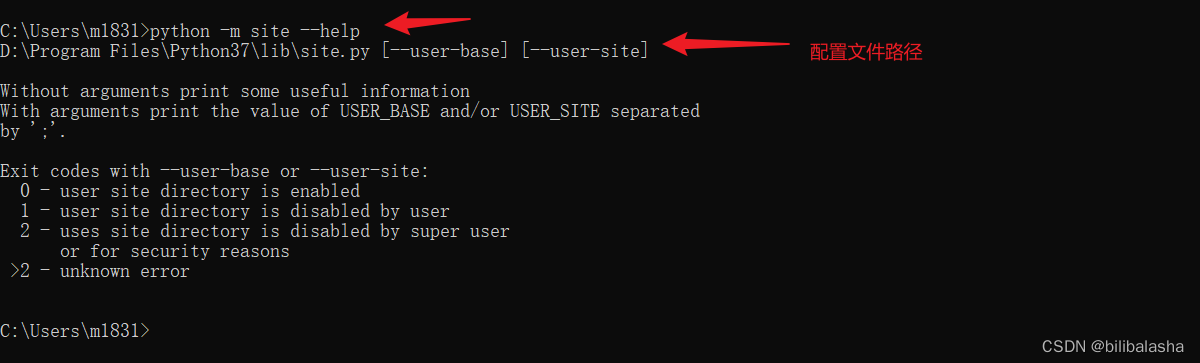
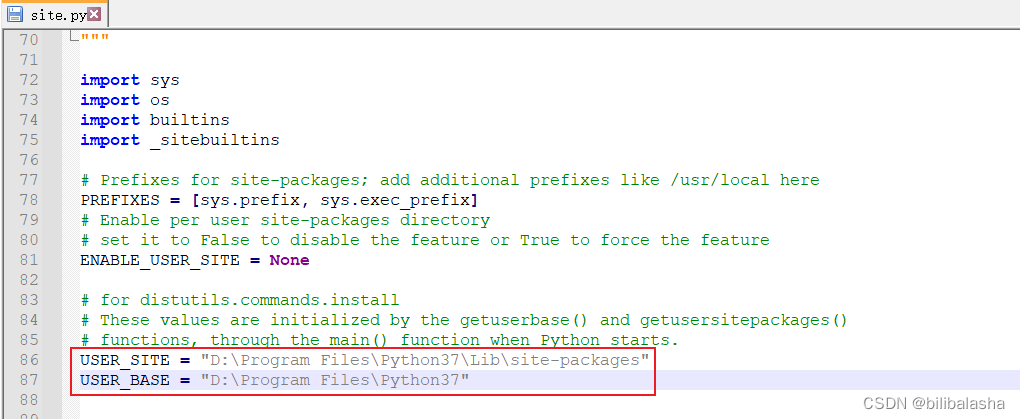
(2)查看默认路径的配置文件所在目录【python -m site --help】,然后招找到配置文件site.py,
修改USER_SITE、USER_BASE(如图2),保存的时候可能会需要管理员权限,授予权限即可。
修改结果如图3所示。
5、其他问题 - - - 修改镜像源
(1)如果觉得pip命令下载第三方库很慢,可以修改镜像源为国内的镜像源,使用pip命令修改即可。
如:修改为清华大学的开源镜像【pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/】。

(2)常用的国内镜像如下:
豆瓣:http://pypi.douban.com/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
华为云:https://repo.huaweicloud.com/repository/pypi/simple
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
中科大:https://pypi.mirrors.ustc.edu.cn/simple/
6、其他问题 - - - [WinError 5] 拒绝访问
(1)如果出现下面类似的问题(图1),使用语句【python -m ensurepip】来修复pip即可(图2)。

















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









