







zset 基本使用
我们先来看一下 zset 都有哪些操作:
| 序号 | 命令及描述 |
|---|---|
| 1 | ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key 获取有序集合的成员数 |
| 3 | ZCOUNT key min max 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZINTERSTORE destination numkeys key [key …] 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 中 |
| 6 | ZLEXCOUNT key min max 在有序集合中计算指定字典区间内成员数量 |
| 7 | ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合指定区间内的成员 |
| 8 | ZRANGEBYLEX key min max [LIMIT offset count] 通过字典区间返回有序集合的成员 |
| 9 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员 |
| 10 | ZRANK key member 返回有序集合中指定成员的索引 |
| 11 | ZREM key member [member …]移除有序集合中的一个或多个成员 |
| 12 | ZREMRANGEBYLEX key min max 移除有序集合中给定的字典区间的所有成员 |
| 13 | ZREMRANGEBYRANK key start stop 移除有序集合中给定的排名区间的所有成员 |
| 14 | ZREMRANGEBYSCORE key min max 移除有序集合中给定的分数区间的所有成员 |
| 15 | ZREVRANGE key start stop [WITHSCORES] 返回有序集中指定区间内的成员,通过索引,分数从高到低 |
| 16 | ZREVRANGEBYSCORE key max min [WITHSCORES] 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 17 | ZREVRANK key member 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 18 | ZSCORE key member返回有序集中,成员的分数值 |
| 19 | ZUNIONSTORE destination numkeys key [key …] 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | ZSCAN key cursor [MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值) |
有序链表
在了解跳跃表之前,我们先了解一下有序链表。
有序链表是所有元素以递增或递减方式有序排列的数据结构,其中每个节点都有指向下个节点的next指针,最后一个节点的next指针指向NULL。

如果要查询值为51的元素,需要从第一个元素开始依次向后查找、比较才可以找到,查找顺序为1→11→21→31→41→51,共6次比较,时间复杂度为O(N)。
有序链表的插入和删除操作都需要先找到合适的位置再修改next指针,修改操作基本不消耗时间,所以插入、删除、修改有序链表的耗时主要在查找元素上。
如果对有序链表进行分层,如图:

- 从第2层开始,1节点比51节点小,向后比较。
- 21节点比51节点小,继续向后比较。第2层21节点的next指针指向NULL,所以从21节点开始需要下降一层到第1层继续向后比较。
- 第1层中,21节点的next节点为41节点,41节点比51节点小,继续向后比较。第1层41节点的next节点为61节点,比要查找的51节点大,所以从41节点开始下降一层到第0层继续向后比较。
- 在第0层,51节点为要查询的节点,节点被找到。
采用上面所示的数据结构后,总共查找4次就可以找到51节点,比有序链表少2次。当数据量大时,优势会更明显。
通过将有序集合的部分节点分层,由最上层开始依次向后查找,如果本层的next节点大于要查找的值或next节点为NULL,则从本节点开始,降低一层继续向后查找,依次类推,如果找到则返回节点;否则返回NULL。
采用该原理查找节点,在节点数量比较多时,可以跳过一些节点,查询效率大大提升,这就是跳跃表的基本思想。
跳跃表
接下来我们来看看redis是怎么实现它的。
跳跃表节点的zskiplistNode结构体:

- ele:用于存储字符串类型的数据。
- score:用于存储排序的分值。
- backward:后退指针,只能指向当前节点最底层的前一个节点,头节点和第一个节点——backward指向NULL,从后向前遍历跳跃表时使用。
- level:为柔性数组。每个节点的数组长度不一样,在生成跳跃表节点时,随机生成一个1~64的值,值越大出现的概率越低。level数组的每项包含以下两个元素。
- forward:指向本层下一个节点,尾节点的forward指向NULL。
- span: forward指向的节点与本节点之间的元素个数。span值越大,跳过的节点个数越多。
跳跃表是Redis有序集合的底层实现方式之一,所以每个节点的ele存储有序集合的成员member值,score存储成员score值。所有节点的分值是按从小到大的方式排序的,当有序集合的成员分值相同时,节点会按member的字典序进行排序。
除了跳跃表节点外,还需要一个跳跃表结构来管理节点,Redis使用zskiplist结构体:
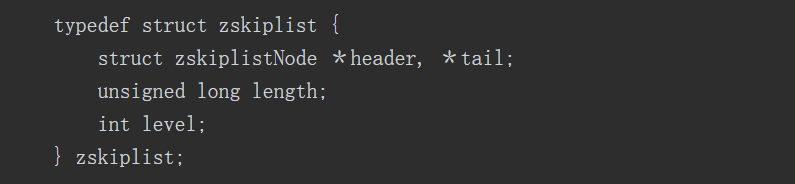
- header:指向跳跃表头节点。头节点是跳跃表的一个特殊节点,它的level数组元素个数为64。头节点在有序集合中不存储任何member和score值,ele值为NULL, score值为0;也不计入跳跃表的总长度。头节点在初始化时,64个元素的forward都指向NULL, span值都为0。
- tail:指向跳跃表尾节点。
- length:跳跃表长度,表示除头节点之外的节点总数。
- level:跳跃表的高度。
如图,可以看到第一个节点完全是为所有分层的一个起始点,最大可以使用64层。

大致这就是redis实现的跳跃表。
ZipList和跳跃表的抉择
在Redis中,跳跃表主要应用于有序集合的底层实现,而另一种是ZipList。
Redis的Zset之所以这样设计,是因为当ZipList变得很大的时候,它存在下面几个缺点:
- 每次插入或修改引发的realloc操作会有更大的概率造成内存复制,从而降低性能。
- 一旦发生内存复制,成本就会相应增加,因为要复制更大的一块数据。
- 当ZipList数据项过多时,在它里面查找指定的数据项的性能就会变得很低,因为在ZipList中的查找需要进行逐个节点的遍历。
Redis.conf相关配置如下:

- zset-max-ziplist-entries表示元素个数的最大值,默认值为128。
- zset-max-ziplist-value表示每个元素的字符串长度最大值,默认值为64。
当元素个数大于128或者每一个元素的长度大于64字节的时候底层数据结构从ZipList切换到SkipList。
当满足所需的条件Redis就会采用跳跃表作为底层实现,否则采用ZipList作为底层实现方式。Zset在转为跳跃表之后,即使元素被逐渐删除,也不会重新转为ZipList。
到这里 redis 的学习系列结束了!对于redis大多数常用的数据结构都有一定的了解,在之后的工作中使用起来也会更加的清晰。
欢迎关注我的公众号,分享golang日常,和学习笔记。
Go菜鸟:GolangNewBie















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









