 数仓拉链表分区实现方案详解
数仓拉链表分区实现方案详解





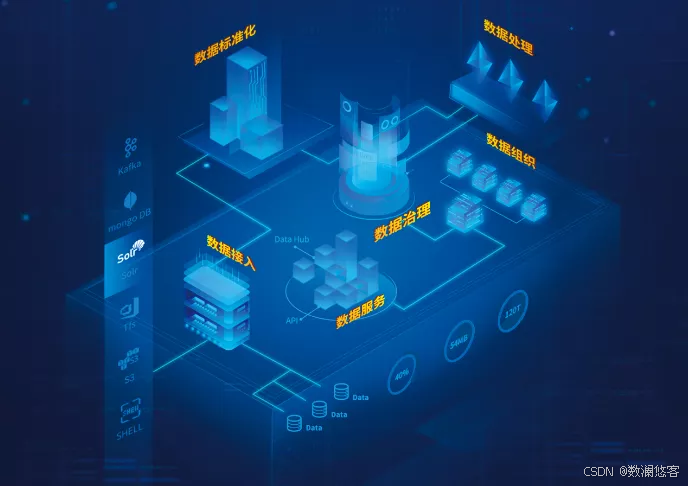
简述:
在当今数字化时代,数据已成为企业和组织的核心资产。数据治理作为确保数据质量、可用性、安全性和合规性的关键手段,在 IT 领域的重要性与日俱增。有效的数据治理能够帮助企业更好地理解和利用数据,支持决策制定、提升运营效率、降低风险,并推动业务创新。
在数据治理的诸多环节中,数据仓库的建设与管理至关重要。而数仓拉链表作为一种特殊的数据存储结构,在数据治理中扮演着不可或缺的角色。它主要用于记录数据的历史变化,通过在表中添加开始时间和结束时间字段,能够清晰地追踪数据从初始状态到当前状态的所有变更情况。
相较于传统的数据存储方式,数仓拉链表具有显著的优势。它能极大地节省存储空间。在数据仓库中,若某些表的数据量庞大且部分字段频繁更新,若采用每天全量存储的方式,会导致大量的存储空间被浪费,因为大部分数据在连续时间点上保持不变。而拉链表仅存储数据的变化部分,大大降低了存储成本。
数仓拉链表为数据分析和审计提供了有力支持。通过拉链表,我们可以轻松获取任意时间点的数据快照,满足对历史数据的查询和分析需求。这对于复盘业务发展历程、分析数据变化趋势、进行合规审计等场景来说,具有不可替代的价值。
一、分区设计思路
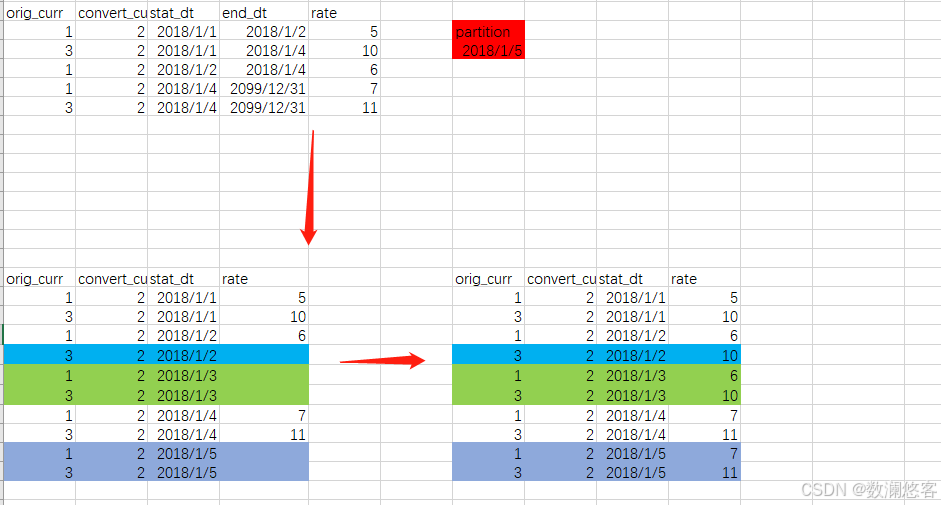
- 基于时间的分区:考虑到拉链表主要记录数据的历史变化,以时间维度进行分区是较为常见且有效的方式。如按天、周、月对start_date或end_date进行分区。例如,按天分区能够精准定位到每一天数据变化的情况,方便数据管理与维护。
- 分区粒度选择:若数据量增长较快且查询频繁涉及短期历史数据,可选择按天分区;若数据量相对较小且更关注长期历史数据的分析,按周或月分区可能更为合适,以减少分区数量,降低管理成本。
二、创建分区表
- Hive 示例
-
- 按start_date进行按天分区的拉链表创建 SQL 如下:
CREATE TABLE zip_tabl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









