







 本文深入探讨了聚类分析,特别是层次聚类。介绍了聚类的基本概念、目的以及与分类的区别。文章详细阐述了层次聚类的思想,包括相似度计算,如欧氏距离、曼哈顿距离等,并讨论了不同的距离度量方法。同时,文章讲解了层次聚类的过程,包括Single、Complete、Average和Centroid等方法,并提供了在R语言中进行层次聚类的实现示例。
本文深入探讨了聚类分析,特别是层次聚类。介绍了聚类的基本概念、目的以及与分类的区别。文章详细阐述了层次聚类的思想,包括相似度计算,如欧氏距离、曼哈顿距离等,并讨论了不同的距离度量方法。同时,文章讲解了层次聚类的过程,包括Single、Complete、Average和Centroid等方法,并提供了在R语言中进行层次聚类的实现示例。
浅谈聚类
引言
聚类分析的目标就是在相似的基础上收集数据来分类。即聚类是我们在面对于大量数据时,所常采用的一种数据处理方式。通过,使用聚类方法有助于将原有数据进行划分,初步将其分为不同部分,提升对于数据的宏观认识,为深入理解数据打下基础。
聚类算法在工业界有着巨大的应用,如在<数学之美>一书中,即举Google将其应用于新闻分类的例子。近年,尤其随着机器学习的火热,聚类算法在学术界与工业界均得到了极大的重视。如2015年初,Science即发表一kmeans聚类改进算法。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。
从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。
聚类与分类(判别)
单从名字中来看,聚类与分类差别不大。但不论放之于统计或机器学习中其差别巨大。用一句常语"物以类聚,人以群分",则是对于聚类分析与分类的最直观简明的诠释。
从理论上而言,在机器学习中,聚类与分类最大的区别在于是否有监督的学习,即是否存在训练集,即分类(判别)方法具有训练集,通过训练集训练模型进而得到分类模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。而聚类则常不具有训练集,也即是说事先没有任何训练样本,而需要直接对数据进行建模。
在统计学中,聚类分析。根据研究对象特征对研究对象进行分类的一种多元分析技术, 把性质相近的个体归为一类, 使得同一类中的个体都具有高度的同质性, 不同类之间的个体具有高度的异质性。而分类(判别) 是一种进行统计判别和分组的技术手段。根据一定量案例的一个分组变量和相应的其他多元变量的已知信息, 确定分组与其他多元变量之间的数量关系, 建立判别函数, 然后便可以利用这一数量关系对其他未知分组类型所属的案例进行判别分组。
也即是随聚类与分类名称类似,但实际其为完全不同的两个概念,所处理的数据也是截然不同的。
主要聚类思想与方法
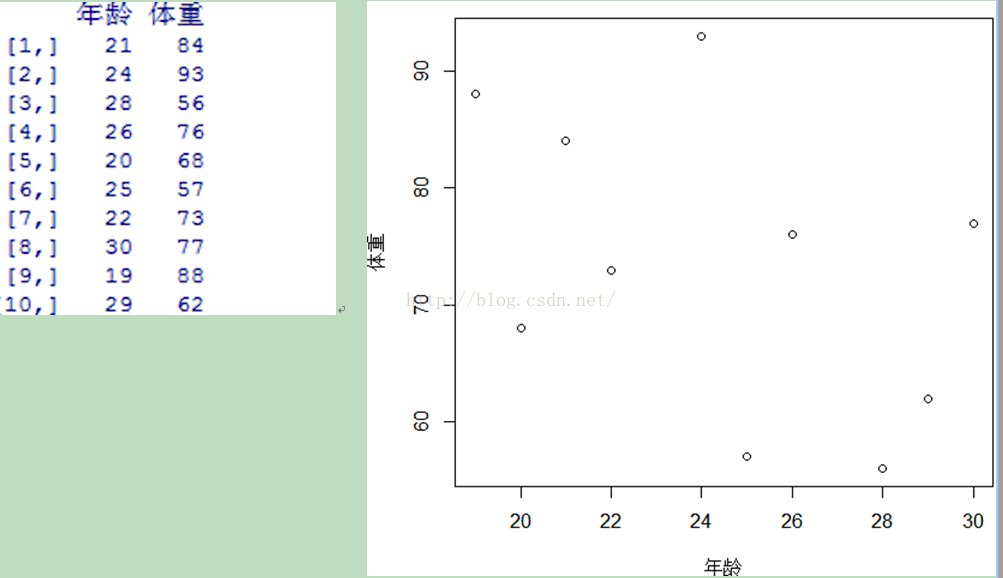
谈起聚类,首先,在此我们假设一个简单的情景即假设我们需要将某一体育课程学生进行聚类,那么我们将如何完成对于所选学生的划分呢?在此,为简单过程,我们在此假设学生仅具有两种属性即年龄与体重。下面本文将结合各主要聚类思想与算法基于R语言给大家详细介绍:
1 层次聚类
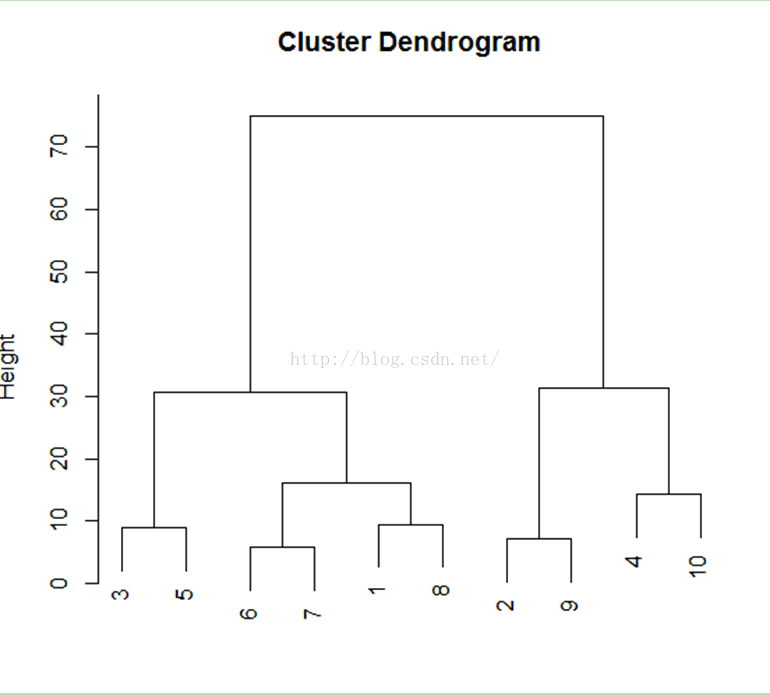
层次聚类是我们在聚类过程中常用的一种方法,其主要思想是:
即将聚类样本中的个体间关系远近使用距离来进行代替,将距离相近的样本放之于一类,重复此过程即可完成聚类。一般采取的聚类过程为自下而上,上图即为一层次聚类过程图,所谓自下而上,也即是一开始样本比如在y轴0层时,都是各自的个体,随着聚类的进行&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2294
2294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









